소개: 이중 지불 문제
E-commerce 플랫폼을 개발하다 보면 흔히 마주치는 문제가 있습니다. 예를 들어, 환불 로직이 고객, 판매자, 또는 자동화된 사기 탐지 시스템에 의해 동시에 트리거될 수 있습니다. 분산 시스템 내에서 적절한 메커니즘이 없으면 동일한 주문이 여러 번 환불됩니다.
실제 시나리오를 생각해 봅시다. 총액 $200짜리 주문에 대해 1초 안에 세 개의 부분 환불 요청($200씩)이 동시에 들어옵니다.
- 고객이 앱을 통해 파손된 상품에 대한 $200 환불을 요청합니다.
- 판매자가 배송 지연에 대한 사과로 $200 환불을 시작합니다.
- 로열티 시스템이 프로모션 가격 매칭 보장의 일환으로 자동으로 $200 환불을 트리거합니다.
세 개의 독립적인 마이크로서비스가 이 요청들을 동시에 처리합니다. 각 서비스는 데이터베이스에서 주문 상태를 읽고, “남은 환불 가능 금액"이 $200인 것을 확인합니다. 데이터베이스가 잔액을 업데이트하기 전에 요청들이 겹치기 때문에, 세 서비스 모두 트랜잭션을 “안전하다"고 검증합니다.
결과: 의도했던 $200 감소가 아니라, 시스템은 세 개의 별개 트랜잭션을 처리합니다. 고객은 총 $600를 환불받고, 실질적인 주문 잔액은 -$400로 떨어집니다. 사용자 의도상으로는 $200 차감 하나만 정당한데 말이죠. 이 경쟁 조건은 분산 lock이나 원자적 카운터의 부재로 인해 의도하지 않은 $400 손실을 초래합니다.
이는 외부의 악의적인 공격에 대비하기 위해서도 반드시 대비가 필요합니다.
전통적인 lock이 작동하지 않는 이유
환불 로직을 synchronized 블록으로 감싸는 게 자연스러운 해결책처럼 보입니다.
// Anti-pattern: 단일 JVM 내에서만 lock이 걸립니다
synchronized(this) {
if (!order.isRefunded()) {
processRefund(order); // 결제 게이트웨이 API 호출, 주문 상태 업데이트
}
}
다른 프로그래밍 언어를 사용한다면 mutex를 쓸 수도 있습니다. 단일 서버에서는 이게 작동하지만, 현대 아키텍처는 여러 인스턴스에 걸쳐 마이크로서비스를 stateless하게 실행합니다. 요청 A는 서버-1로, 요청 B는 서버-2로, 요청 C는 서버-3로 들어갑니다. 각 JVM은 자체 힙과 자체 synchronized lock을 가지고 있으며, 이는 해당 서버 프로세스 내의 스레드들만 조정합니다. 즉, 로컬 mutex로는 네트워크 경계를 넘어 동작의 실행을 조정할 수 없습니다.
타이밍 문제
로컬 lock 문제 외에도, 타이밍 이슈가 여전히 경쟁 조건(race condition)을 일으킵니다.
네트워크 지연: 요청 A는 T=0ms에 시작되지만 네트워크 지터로 인해 데이터베이스에 도달하는 데 150ms가 걸립니다. 요청 B는 T=50ms에 시작되어 먼저 도착하고 커밋됩니다.
오래된 읽기: 요청 A가 primary 데이터베이스에서 주문 상태를 “환불됨"으로 업데이트합니다. 요청 B는 아직 따라잡지 못한 replica에서 읽어서 “환불 안 됨"을 봅니다.
전통적인 동시성 프리미티브들—mutex, semaphore, synchronized 블록—은 공유 메모리를 전제로 합니다. 분산 시스템은 네트워크 외에는 공유하는 게 없으며, 네트워크는 본질적으로 신뢰할 수 없습니다.
핵심 문제
이게 분산 시스템의 이중 지불 문제입니다. 정확히 한 번 실행되어야 하는 작업(환불 발행 같은)이 조정 실패로 인해 여러 번 실행됩니다. 환불 작업이 멱등하지 않다면—두 번 실행하면 결제 게이트웨이를 두 번 호출해서 두 개의 별개 환불 트랜잭션을 생성하고 손실을 두 배로 만듭니다. 멱등성은 작업을 여러 번 수행해도 한 번 수행한 것과 동일한 효과를 갖는 속성입니다. 분산 시스템에서 클라이언트는 네트워크 타임아웃 때문에 요청을 재시도할 수 있고, 이는 동일한 명령이 두 번 전송되는 상황으로 이어집니다. 분산 lock은 고유한 idempotency key와 함께 사용되어, 이런 중복 요청들이 동시에 도착하더라도 첫 번째 요청만 실행되고 이후 요청들은 반복으로 인식되어 안전하게 무시되도록 보장합니다.멱등성이란?
해결책으로는 데이터베이스 수준의 uniqueness constraint(낙관적 lock), 분산 lock(Redis, ZooKeeper), 그리고 API 레이어에서 중복 제거를 위한 idempotency key가 있습니다. 데이터베이스 constraint는 데이터 레이어에서 원자적 강제를 제공합니다. 분산 lock은 서비스 간 조정을 하지만 타임아웃과 실패를 신중하게 다뤄야 합니다. Idempotency key는 중복 API 요청이 중복 작업을 일으키는 것을 방지합니다. 각 접근 방식은 서로 다른 일관성 보장과 트레이드오프를 갖습니다.
분산 lock이 정말 필요한 경우는?
요즘 백엔드 시스템은 확장성과 장애 내성을 위해 여러 개의 stateless 인스턴스를 운영합니다. 이 인스턴스들간에 공유되는 상태값이 필요하며 이 값에 대한 조율이 필요할 때, 그 조율은 서버 인스턴스의 밖에서 일어나야 합니다. 보통은 분산 lock을 통해서요.
공유 리소스
여러 프로세스가 제한된 리소스를 두고 경쟁할 때는 충돌을 방지하기 위한 조율이 필요합니다.
외부 API 할당량이 흔한 예시입니다. 분당 100건의 요청을 허용하는 API를 돈 주고 쓰고 있다고 해보죠. 조율이 없으면 10대의 서버 인스턴스가 각각 100건씩 요청을 보내서 총 1000건이 되고, 결국 throttle을 당하거나 초과 요금을 내게 됩니다.
효율성: 중복 작업 방지
일부 작업은 워낙 무겁기 때문에 여러 번 실행하면 상당한 리소스를 낭비하게 됩니다.
일일 분석 리포트를 생성하는데 5분이 걸리고 CPU를 많이 쓴다고 해보죠. 5개의 인스턴스가 동시에 이 작업을 시작하면 20분의 연산 시간을 날리는 셈이고, 결과가 일관되지 않을 수도 있습니다. 분산 lock을 쓰면 하나의 인스턴스만 작업을 수행하고 나머지는 건너뛰거나 결과를 기다리도록 만들 수 있습니다. ㄴ 핫 키 만료는 인기 있는 캐시 키 하나가 만료될 때 밀리초 단위로 1,000개의 요청이 동시에 같은 데이터를 달라고 API를 찌르는 상황입니다. lock이 없으면 1,000개의 동시 요청이 전부 캐시가 비어있는 걸 확인하고 똑같은 무거운 DB 쿼리를 동시에 날립니다. 분산 lock을 쓰면 첫 번째 요청만 캐시를 다시 채울 권한을 얻고, 나머지는 잠깐 기다렸다가 새로 갱신된 값을 읽어가게 됩니다. DB 부하 폭증을 막는 거죠.
정확성: 데이터 손상 방지
여기서 분산 lock은 애플리케이션 레벨에서, 그러니까 DB 트랜잭션을 시작하기도 전에 조율을 담당합니다.
멱등성 로직(유니크 키 체크 등)이 중복 레코드 생성을 막아준다면, 분산 lock은 그 체크 과정 자체에서 발생할 수 있는 레이스 컨디션(Race Condition)을 원천 봉쇄합니다. lock이 없다면, 사용자가 ‘환불’ 버튼을 더블 클릭했을 때 두 요청이 거의 동시에 “이미 처리되었나?“라는 체크 로직을 통과해 버릴 위험이 있습니다. 멱등성 키를 기반으로 분산 lock을 걸면, 단 하나의 요청만이 상태를 확인하고 트랜잭션을 시작할 수 있도록 보장합니다.
또한, 다단계 워크플로우로 외부 시스템이 얽혀 있는 경우 그 중요성은 더 커집니다. 데이터베이스, 인증 프로바이더(Auth Provider), 그리고 외부 SaaS 툴을 가로질러 계정을 생성하는 과정을 예로 들어보겠습니다. 데이터베이스 트랜잭션만으로는 외부 시스템에서 이미 발생한 사이드 이펙트(Side Effect)까지 롤백할 수 없습니다. 시작 시점에 사용자 ID에 lock을 걸어두면, 동시 가입 요청으로 인해 외부 시스템에 ‘유령 계정’이 생성되거나 불필요한 리소스가 중복으로 할당되는 대참사를 막을 수 있습니다. 이러한 방어 기제는 단순한 기술적 결함을 넘어 외부의 악의적인 공격(Race Condition Exploit 등)으로부터 시스템을 보호하기 위한 필수적인 보안 조치이기도 합니다.
왜 외부 상태 관리인가?
Stateless 서버끼리는 서로 조율할 수 없습니다. 공유 메모리가 없거든요. 한 프로세스 메모리에 잡힌 lock은 다른 프로세스나 서버에는 보이지 않습니다. 조율을 위해서는 모든 인스턴스가 접근할 수 있는 시스템이 필요합니다. Redis, 적절한 트랜잭션 격리 수준을 가진 데이터베이스, etcd, 또는 ZooKeeper 같은 합의 시스템이죠.
트레이드오프는 명확합니다. 인스턴스 간 조율을 얻는 대신, 모든 lock 작업이 접촉해야 하는 의존성이 생깁니다. lock 서비스가 느리거나 먹통이 되면 조율이 필요한 모든 작업이 막히게 됩니다.
해결책: 간단하고 성능 우선의 Redis Lock
Redis는 분산 lock을 구현하는 가장 간단한 방법입니다. 싱글 스레드 실행 모델과 원자적 연산이 핵심적인 동시성 문제를 처리해주거든요.
Redis가 잘 맞는 이유
Redis의 싱글 스레드 실행 방식은 명령어를 순차적으로 처리합니다. SET key value NX를 실행하면 Redis가 키의 존재 여부를 확인하고 설정하는 과정이 원자적으로 진행됩니다. 이 두 단계 사이에 다른 명령어가 끼어들 수 없죠. 애플리케이션 레벨에서 “체크 후 설정” 로직을 직접 구현할 때 마주치는 race condition을 원천적으로 차단하는 셈입니다.
Redis 연산은 빠릅니다(서버에서 밀리초 이하). 물론 분산 시스템에서는 네트워크 지연이 대부분의 시간을 차지하지만요(인프라에 따라 1-10ms 이상). 그래도 데이터베이스 row lock보다는 빠르고, 트랜잭션 격리 수준을 관리하거나 여러 테이블에 걸친 데드락을 걱정할 필요도 없습니다.
구현
핵심 Redis 명령어는 다음과 같습니다:
SET invoice:123 550e8400-e29b-41d4-a716-446655440000 NX PX 30000
하나씩 뜯어보면:
invoice:123- lock key550e8400-e29b-41d4-a716-446655440000- lock 소유자를 식별하는 고유 토큰(UUID)NX- 키가 없을 때만 설정 (lock 획득)PX 30000- 30초 후 만료 (안전 장치, TTL)
고유 토큰이 핵심입니다. 토큰이 없으면 Service A가 실수로 Service B의 lock을 해제할 수 있거든요. lock을 해제할 때는 반드시 자신이 여전히 소유자인지 확인해야 합니다:
import uuid
import redis
import time
redis_client = redis.Redis(host='localhost', port=6379, decode_responses=True)
def acquire_lock_with_retry(lock_name, acquire_timeout=10):
lock_id = str(uuid.uuid4())
end_time = time.time() + acquire_timeout
while time.time() < end_time:
# NX: 키가 없을 때만 획득 시도
# PX 30000: 30초 후 자동 만료 (안전 장치)
if redis_client.set(lock_name, lock_id, nx=True, px=30000):
return lock_id
# 획득 실패 시 짧게 대기 (CPU 부하 방지)
time.sleep(0.1)
return None
# 실행
lock_key = 'invoice:123'
lock_id = acquire_lock_with_retry(lock_key)
if lock_id:
try:
# 인보이스 처리
pass
finally:
# 아직 lock 소유자일 때만 해제 (Lua 스크립트로 원자성 보장)
release_script = """
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end
"""
redis_client.eval(release_script, 1, lock_key, lock_id)
대부분의 Redis 클라이언트 라이브러리는 더 높은 수준의 추상화를 제공합니다(aioredis도 마찬가지):
# redis-py 편의 래퍼
lock = redis_client.lock("invoice:123", timeout=30)
if lock.acquire(blocking=False):
try:
# 인보이스 처리
pass
finally:
lock.release()
라이브러리가 내부적으로 고유 토큰을 처리해줍니다.
마이크로서비스 크래시 처리
lock에는 항상 TTL을 설정하세요. 서비스가 lock을 획득한 후 크래시되면 TTL이 Redis가 자동으로 락을 해제하도록 보장합니다.
TTL은 예상 처리 시간의 2-3배로 설정하세요. 인보이스 처리가 P99 지연 시간 기준 5초 걸린다면 15초 TTL을 사용하면 됩니다. 프로덕션 메트릭을 모니터링하세요. release()가 호출되기 전에 lock이 만료되는 현상이 보인다면, 처리 시간이 너무 길거나 서비스가 크래시되고 있는 겁니다.
라이선스 참고사항
새로 시작한다면 Valkey를 고려해보세요. Redis가 2024년에 제한적인 라이선스로 변경한 이후 BSD 라이선스를 유지하는 Linux Foundation 포크입니다. 모든 Redis 클라이언트와 프로토콜 호환됩니다.
트레이드오프
Redis lock은 빠르고 간단하지만, 단일 장애 지점(single point of failure)을 만듭니다. Redis가 다운되면 어떤 서비스도 lock을 획득할 수 없죠. 많은 케이스에서 이 위험은 감수할 만하지만, 진정한 장애 허용성(fault tolerance)이 필요하다면 다른 접근 방식이 필요합니다.
분산 솔루션: 안정성과 조율
단일 노드 Redis가 죽으면 모든 lock이 날아갑니다. 분산 대안들은 이런 단일 장애 지점을 제거하지만, 각각 고유한 트레이드오프가 있습니다.
Redis 계열: 트로이 목마
기존 Redis 인프라를 분산 lock에 활용하는 건 매력적이고 비용도 적게 들며 마이그레이션 부담도 적어 보이지만, 가용성과 안정성 사이의 위험한 트레이드오프를 초래합니다. 핵심 문제는 Redis 복제가 본질적으로 비동기라는 점입니다.
비동기 복제의 간극 Redis 복제는 비동기입니다. 클라이언트가 lock을 획득하면 Primary 노드에 먼저 쓰기가 발생합니다. Primary는 데이터가 Replica와 동기화되기 전에 클라이언트에게 확인 응답을 보냅니다.
시나리오:
- Client A가 Primary에서 lock을 성공적으로 획득합니다.
- Primary는 lock을 확인했지만 Replica에 키를 복제하기 전에 죽습니다.
- Replica가 페일오버(Sentinel 또는 Cluster)를 통해 Primary로 승격됩니다.
- 새 Primary에는 Client A가 보유한 lock 기록이 없습니다.
- Client B가 같은 lock을 요청하고, 새 Primary는 이를 허가합니다.
결과: Client A와 Client B가 동시에 “배타적” lock을 보유하게 되어 경쟁 상태와 데이터 손상 가능성이 생깁니다.
시간 드리프트 문제 Redis lock은 TTL(Time-to-Live)에 의존합니다. 분산 환경에서 Primary와 Replica(또는 서로 다른 클라이언트) 간 시스템 시계가 완벽하게 동기화되지 않으면, 한 노드에서는 lock이 조기 만료되지만 다른 노드에서는 여전히 유효하다고 간주되어 페일오버 중 lock의 신뢰성을 떨어뜨립니다.
Redis Sentinel은 자동 페일오버를 통해 고가용성을 제공합니다. 여러 Redis 인스턴스(하나의 마스터, 여러 레플리카)를 실행하고 Sentinel 프로세스가 이를 모니터링합니다. 마스터가 죽으면 Sentinel이 레플리카 중에서 새 마스터를 선출합니다. Redis의 기본 비동기 복제 메커니즘을 바꾸지는 않습니다. 여전히 한 번에 단일 마스터에만 쓰기를 하므로—진정으로 분산된 게 아니라 그냥 장애 허용이 될 뿐이고, 본질적으로 같은 취약점을 공유합니다.
Redis Cluster는 해시 슬롯(총 16,384개 슬롯)을 사용해 여러 마스터에 데이터를 분할합니다. 각 키는 슬롯에 해싱되고, 각 마스터는 슬롯 범위를 소유합니다. 수평 확장성을 제공하고 단일 마스터 병목 현상을 제거합니다.
- 여전히 비동기 복제가 있어서—페일오버 중 lock을 잃을 수 있습니다.
- 네트워크 오버헤드 증가: 노드들이 클러스터 멤버십을 발견하기 위해 가십하고, 클라이언트가 잘못된 슬롯 소유자를 건드리면 요청을 리다이렉트해야 합니다.
- 더 복잡한 작업(다중 키 트랜잭션)은 해시 태그(
{user123}:lock,{user123}:data가 같은 노드에 위치)를 사용하지 않는 한 다른 슬롯 간에 작동하지 않습니다.
본질적으로 Redis 계열은 속도와 가용성을 위해 설계된 고성능 키-값 데이터 저장소로 설계되었습니다. 캐싱 레이어로는 탁월하지만, 신뢰할 수 있는 분산 lock에 필요한 CP(일관성과 파티션 허용) 시스템으로 만들어진 건 아닙니다. 게다가 모든 옵션은 여전히 TTL 기반 만료와 비동기 복제에 의존하는데, 이는 본질적으로 페일오버 중에 “손실"을 동반합니다. 이런 접근법을 채택하면 추적과 재현이 어렵기로 악명 높은 은밀한 버그와 며칠 동안 씨름할 수 있습니다.
Zookeeper: 조율을 위해 만들어진 도구
Apache Zookeeper는 리더 선출, 설정 관리, 분산 락과 같은 분산 코디네이션 작업에 특화된 도구입니다. 캐시 시스템에 락 기능을 덧붙인 Redis와 달리, Zookeeper는 설계 단계부터 이러한 조율 기능을 핵심 데이터 모델로 삼아 구축되었습니다.
간단한 내부 구조
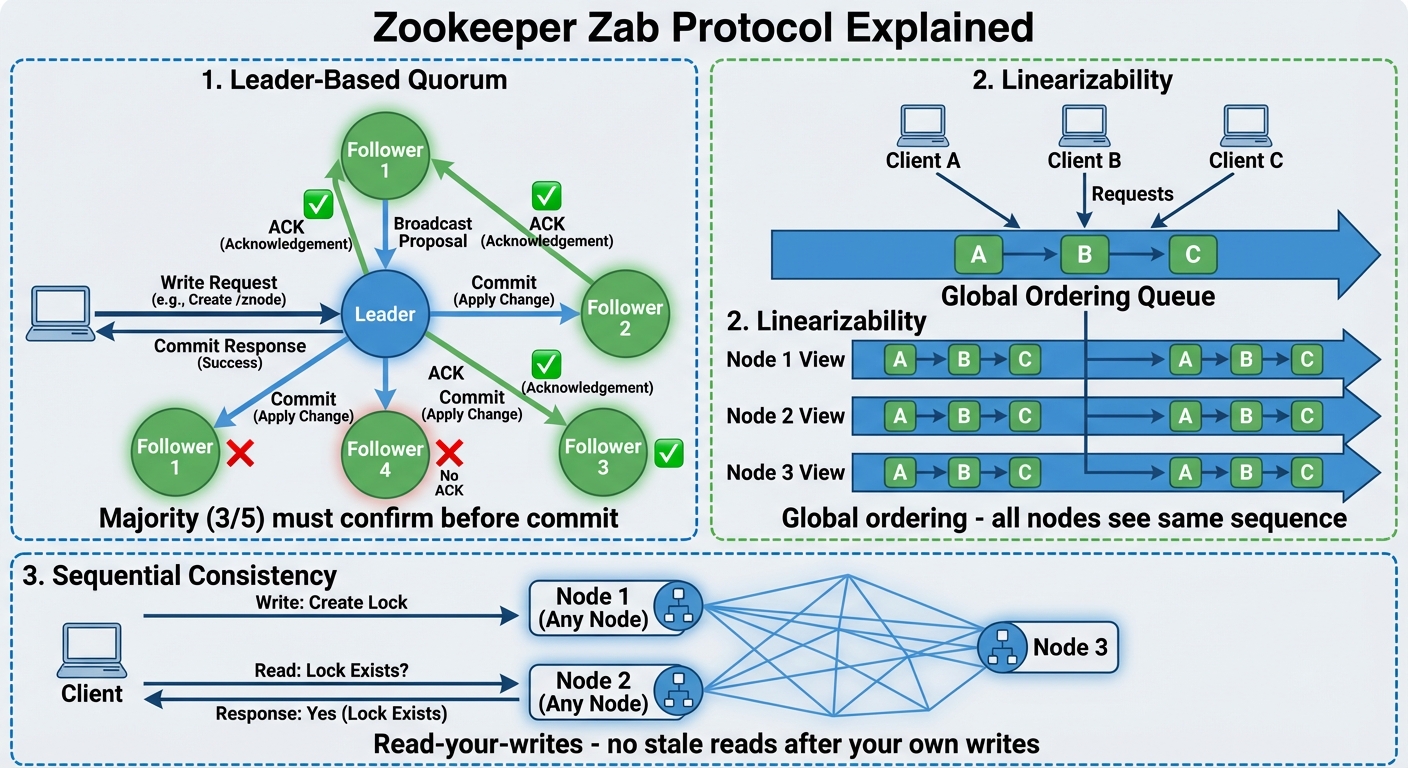
Zookeeper의 신뢰성은 핵심 합의 엔진인 Zab(Zookeeper Atomic Broadcast)에서 비롯됩니다. Redis에서 발견되는 단순한 “발사 후 잊기” 복제와 달리, Zab는 lock 획득이나 해제 같은 모든 변경 사항이 클러스터가 내리는 집단적 결정임을 보장합니다.
다수결의 힘(Quorum): Zookeeper의 강력한 신뢰성은 핵심 합의 알고리즘인 **Zab(Zookeeper Atomic Broadcast)**에서 나옵니다. 복제 성공 여부를 확인하지 않는 Redis의 일반적인 복제 방식과 달리, Zab는 락의 획득과 해제 등 모든 상태 변경이 클러스터 전체의 합의를 거쳐 확정됨을 보장합니다.
안전망: lock이 확인되기 전에 과반수가 동의해야 하므로, Leader가 죽더라도 생존자 중에서 선출된 새 Leader는 항상 가장 최근의 확인된 lock 상태를 보유하게 됩니다.
보장된 순서(Linearizability): 분산 환경에서 이벤트의 발생 순서는 시스템의 성패를 결정짓는 핵심 요소입니다. Zab는 선형성(Linearizability)을 보장하여, 모든 업데이트 요청이 하나의 엄격한 전역 순서(Global Ordering)에 따라 순차적으로 처리되도록 강제합니다.
그 결과 클러스터의 모든 노드가 정확히 동일한 이벤트 타임라인을 바라봅니다. 서로 다른 노드가 누가 먼저 lock을 획득했는지 의견이 다른 “스플릿 브레인” 시나리오는 절대 발생하지 않습니다.
지연 처리의 기술 Zookeeper를 처음 접하면 모든 노드가 언제나 완벽하게 동기화되어 있을 것이라고 오해하기 쉽습니다. 실제로는 다른 분산 시스템처럼 Follower 노드가 네트워크 지연으로 인해 잠깐 “오래된” 데이터를 제공할 수 있습니다. 하지만 Zookeeper는 일시적인 지연이 안전을 절대 해치지 않도록 설계되었습니다. 이를 Eventual Consistency와 엄격한 순서 지정의 영리한 조합으로 처리합니다.
Zookeeper는 Follower가 읽기를 수행하기 전에 Leader의 최신 상태를 따라잡도록 강제하는 sync() 명령을 제공합니다. sync()는 절대적인 선형성을 제공하지만, Leader에 대한 추가 왕복이 필요하므로 운영상 “무겁습니다”. 따라서 대부분의 프로덕션급 lock 구현은 지속적인 sync() 호출을 피합니다. 대신 Watcher 메커니즘과 재검증 루프에 의존해 지연을 커버합니다.
Zookeeper는 또다른 중요한 보장 메커니즘을 제공합니다: watch 이벤트는 클라이언트가 데이터 변경을 보기 전에 도착할 것을 약속합니다. 이전 lock 보유자가 사라지면 Leader가 이 삭제를 브로드캐스트합니다. 각 Zookeeper 노드는 자체 로컬 데이터베이스를 업데이트하기 전에 연결된 클라이언트에게 “Deleted” 알림을 보내도록 보장합니다. 대기 중인 클라이언트가 알림을 받고 자식 목록을 다시 읽을 때쯤이면 최신 상태가 반영되어 있을 가능성이 높습니다. 다음 섹션에서 이를 더 자세히 논의하겠습니다.
분산 lock에 사용하는 방법
Zookeeper는 파일 시스템과 유사한 계층적 네임스페이스를 사용합니다. 각 노드(znode라고 불림)는 소량의 데이터를 저장할 수 있습니다(최대 ~1MB, 하지만 lock의 경우 일반적으로 몇 바이트). lock을 위해서는 임시 순차 znode를 생성합니다:
임시 znode는 클라이언트 연결이 끊어지면 사라져서—죽은 클라이언트 문제를 깔끔하게 해결합니다. TTL에 의존하는 대신 Zookeeper는 lock의 수명을 클라이언트의 활성 세션에 묶습니다.
게다가 기본 lock 모델에서는 여러 서버가 “경주"를 벌이고 보통 가장 빠른 네트워크가 이깁니다. 이는 일부 서버가 절대 차례를 얻지 못하는 Lock Starvation으로 이어질 수 있습니다. Zookeeper는 모든 lock 요청에 순차 번호(lock-001, lock-002)를 할당해 이를 해결합니다. 가장 낮은 번호를 가진 클라이언트만 lock을 보유하므로 모든 프로세스가 도착한 정확한 순서대로 처리됩니다.
아래 예제 코드로 watch가 임시 노드와 어떻게 작동하는지 살펴봅시다.
# Zookeeper lock 패턴
zk.create("/locks/my-resource/lock-", ephemeral=True, sequence=True)
# 생성: /locks/my-resource/lock-005
while True:
# 1. 모든 참여자 가져오기 (지연으로 인해 약간 오래된 목록을 반환할 수 있음)
children = zk.get_children("/locks/my-resource")
children.sort()
# 2. 내가 소유자인지 확인 (가장 낮은 순차 번호)
if children[0] == my_lock_node:
# [SUCCESS] 리더로 확인됨
perform_critical_section()
zk.delete(my_lock_node) # lock 해제
break
else:
# [WAIT] 바로 앞 노드를 감시
# 이전 노드가 삭제되거나 세션이 끊어질 때까지 블록
wait_for_event(watch_previous_node(children[children.index(my_lock_node) - 1]))
# 이벤트가 발생하면 루프가 재시작되어 상태를 재검증
거의 불가능한 극단적인 케이스를 고려해봅시다. Zookeeper의 안전성을 이해하기 위한 “과거의 유령” 시나리오입니다.
- Client B가 005를 성공적으로 생성했습니다.
- 하지만 읽고 있는 Follower 노드가 너무 느려서 여전히 003을 목록의 선두로 표시합니다.
- 실제로는 003과 004가 이미 작업을 마치고 005가 생성된 직후 노드를 삭제했지만, Follower는 아직 그걸 모릅니다.
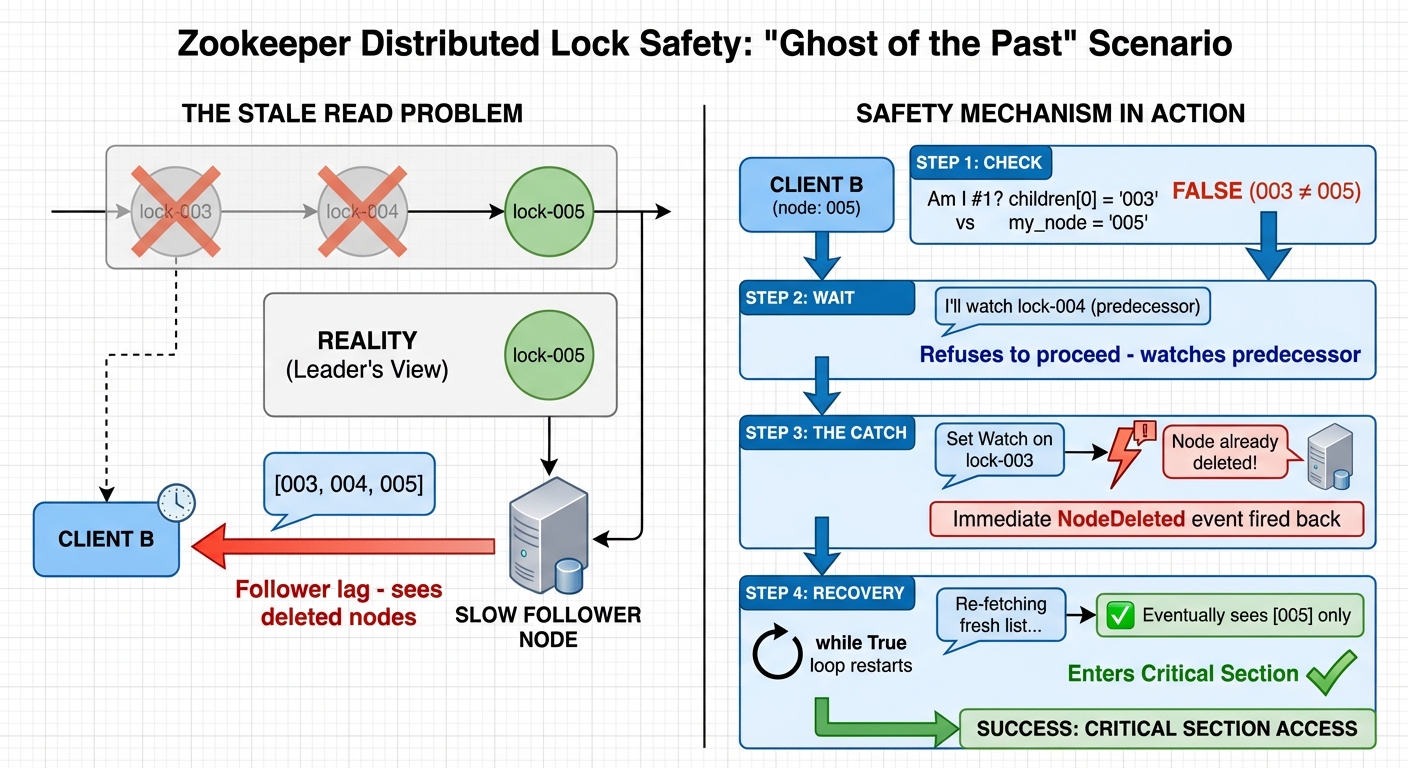
코드가 실행될 때 안전을 향한 엄격한 경로를 따릅니다:
- 단계 1 (확인): 클라이언트가 목록의 선두(003)를 자신의 노드(005)와 비교합니다. 조건 if children[0] == “lock-005"는 False를 반환합니다.
- 단계 2 (대기): #1이 아니기 때문에 Client B는 임계 영역 진입을 거부합니다. 대신 앞 노드(003)를 감시할 준비를 합니다.
- 단계 3 (포착): Client B가 lock-003에 Watch를 설정하려 시도할 때, Zookeeper 서버는 노드가 이미 사라졌다는 것을 알아차립니다. 즉시 클라이언트에게 “Node Deleted” 이벤트를 발생시킵니다.
- 단계 4 (복구): 이 이벤트가 Client B를 즉시 깨웁니다. while True 루프가 재시작되고, 클라이언트는 목록을 다시 가져오며, 지연이 해소되고 자신이 줄의 맨 앞에 있는 것을 볼 때까지 이 사이클을 계속합니다.
실제 사용 사례
Kafka는 v2.8까지 브로커 메타데이터에 Zookeeper를 사용했지만, 대규모 클러스터에서 확장성 문제로 KRaft로 교체했습니다.
주의할 점:
- Zookeeper는 운영상 복잡합니다. 안정적인 3-5 노드 앙상블을 실행하려면 튜닝과 모니터링이 필요합니다.
- 높은 처리량의 데이터 저장용으로 설계되지 않았습니다. 쓰기가 많은 워크로드는 시스템에 스트레스를 줄 수 있습니다.
- 클라이언트는 연결 손실과 세션 만료를 명시적으로 처리해야 합니다. 세션 타임아웃 설정은 lock 안전성에 직접 영향을 미칩니다.
Apache Ignite: 분산 데이터 그리드
Apache Ignite는 강력한 일관성을 갖춘 분산 인메모리 데이터 그리드입니다. 코어당 싱글 스레드로 동작하는 Redis나 코디네이션에 특화된 ZooKeeper와 달리, Ignite는 분산 클러스터 전체에서 대규모 트랜잭션 워크로드를 처리하도록 설계되었습니다.
데이터 구조
Ignite는 대규모 워크로드를 병렬로 처리하기 위한 여러 메커니즘을 갖추고 있습니다.
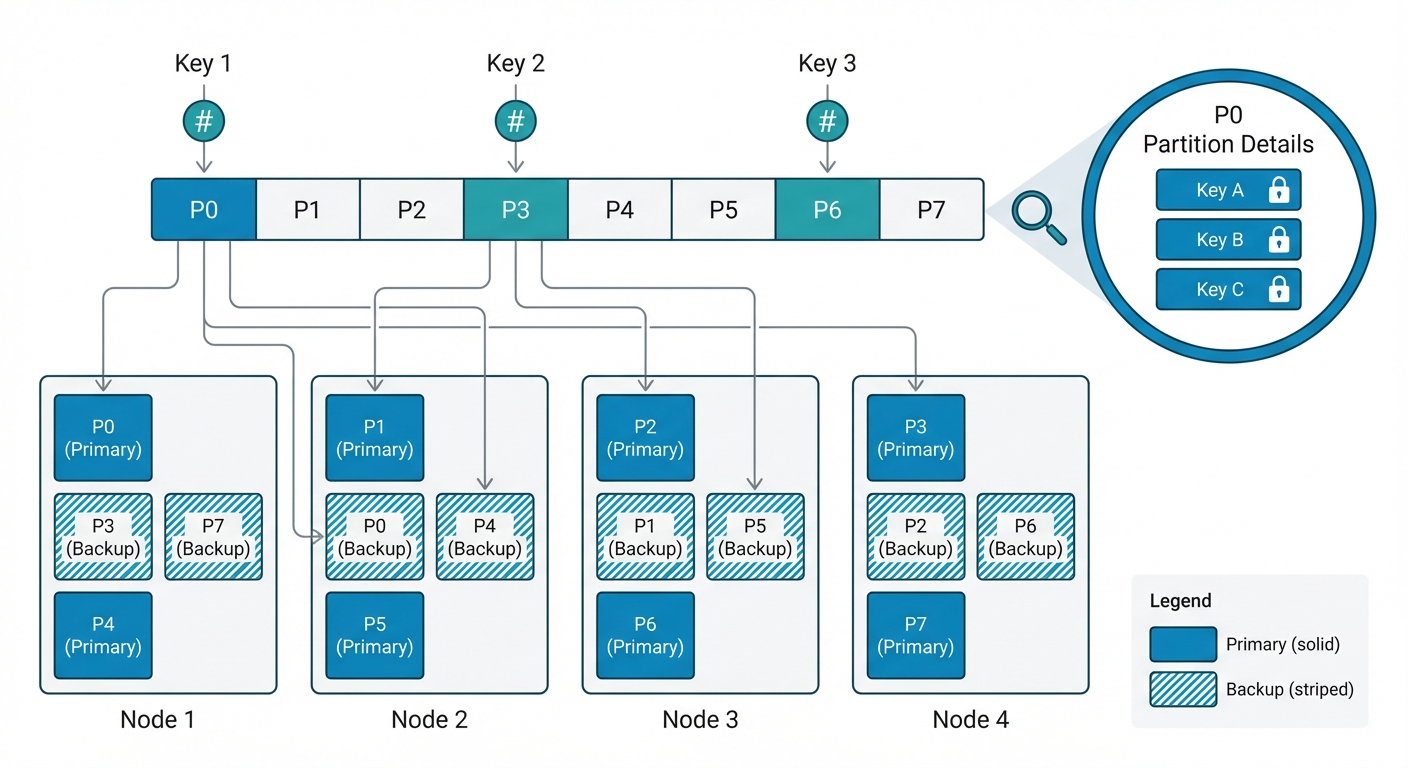 Figure: Ignite의 해시 파티션 기반 데이터 분배와 백업 레플리카, 키 레벨 lock
Figure: Ignite의 해시 파티션 기반 데이터 분배와 백업 레플리카, 키 레벨 lock
리더 병목을 넘어서: 해시 기반 파티셔닝 Ignite의 처리량 비결은 Shared-nothing Architecture에 있습니다. ZooKeeper가 모든 lock 요청을 단일 리더 노드를 통과시키는 것과 달리, Ignite는 데이터와 그 관리를 클러스터 전체에 분산시킵니다.
- 해시 파티셔닝: 모든 데이터(키)은 결정론적 해시 함수를 통해 특정 파티션에 매핑됩니다. 이 파티션들은 클러스터의 모든 노드에 걸쳐 분산됩니다.
- 탈중앙화된 제어: 특정 키의 프라이머리 파티션을 소유한 노드가 해당 키의 “미니 리더” 역할을 합니다. 클러스터의 모든 노드가 서로 다른 데이터 부분집합에 대해 동시에 코디네이터 역할을 수행하는 셈이죠.
세밀한 동시성: 키 레벨 lock Ignite에서 lock 단위는 파티션 레벨이 아닌 개별 키 레벨입니다.
- 파티션 내 병렬 처리: 수천 개의 트랜잭션이 같은 파티션에 몰려도, 서로 다른 키를 대상으로 하면 여러 “쓰기” 작업이 동시에 병렬로 진행될 수 있습니다.
- 멀티 스레드 처리 (Striped Thread Pool): 각 Ignite 노드는 정교한 멀티 스레딩 모델을 활용합니다. 들어오는 요청들은 워커 스레드 풀이 처리하므로, 단일 노드가 모든 CPU 코어를 활용해 수천 개의 동시 lock 획득을 처리할 수 있습니다.
ACID 트랜잭션
Ignite는 분산 데이터 전체에 걸쳐 완전한 ACID 트랜잭션을 지원합니다. lock은 트랜잭션 범위 내에서 유지하거나 커밋 시까지 유지할 수 있습니다.
이를 구현하기 위해 Ignite는 Two-Phase Commit (2PC) 프로토콜을 사용합니다. 일부 노드나 네트워크 링크가 장애를 일으켜도 여러 노드에 걸쳐 데이터 일관성을 보장하는 “만장일치 투표” 시스템이라고 생각하면 됩니다.
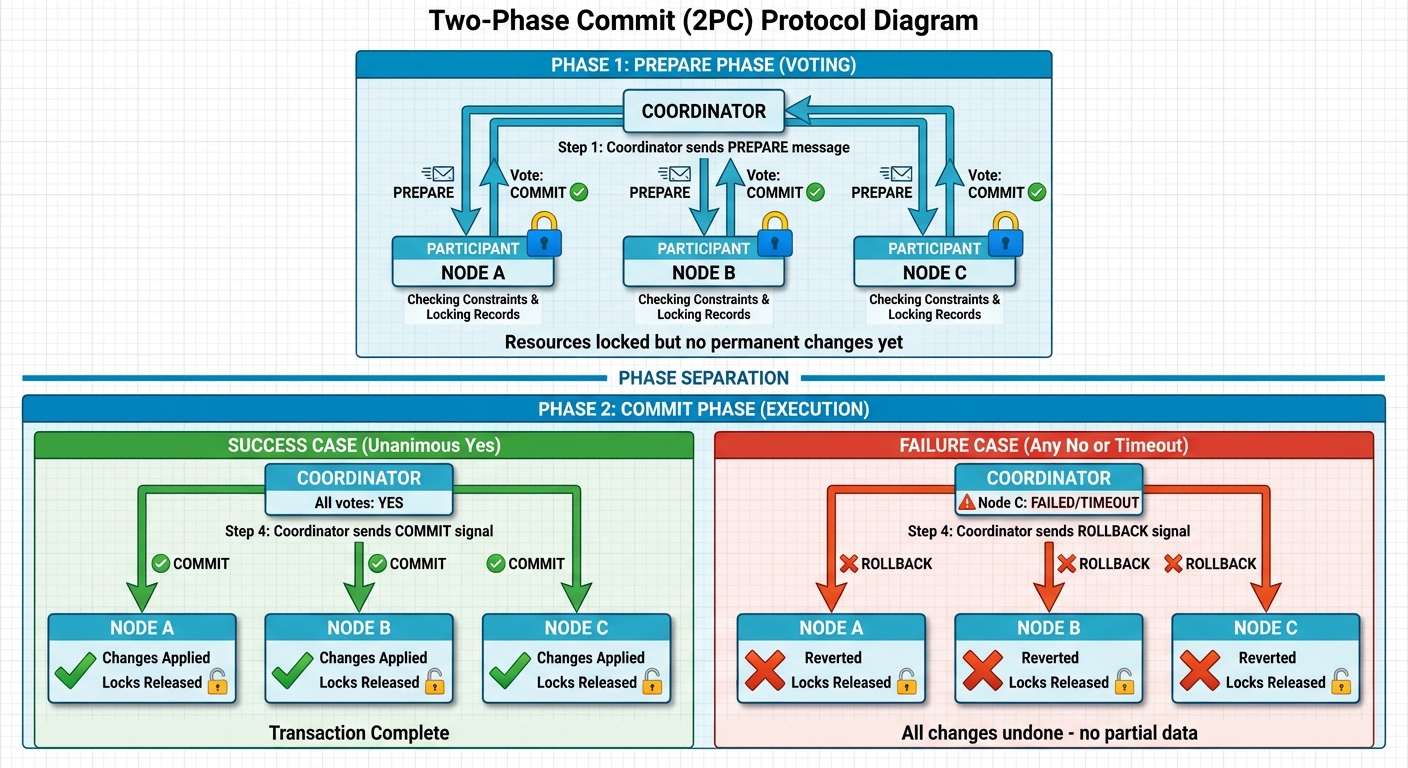
1단계: Prepare 단계 (투표)
- 트랜잭션 코디네이터가 참여하는 모든 노드에 “Prepare” 메시지를 보냅니다.
- 각 노드는 트랜잭션을 안전하게 커밋할 수 있는지 확인하고(제약 조건이나 리소스 가용성 체크 등), 필요한 레코드를 lock합니다.
- 노드들은 “커밋 찬성” 또는 “중단 찬성"으로 응답합니다.
- 이 단계에서는 영구적인 변경이 이루어지지 않지만, 리소스는 “예약"된 상태입니다.
2단계: Commit 단계 (실행)
- 코디네이터가 모든 투표를 수집하고 최종 결정을 내립니다:
- 만장일치 “Yes”: 모든 노드가 커밋에 찬성하면, 코디네이터가 “Commit” 신호를 보냅니다. 모든 노드가 변경을 영구 적용하고 lock을 해제합니다.
- 하나라도 “No” 또는 타임아웃: 단 하나의 노드라도 실패하거나 중단에 투표하면, 코디네이터가 “Rollback” 신호를 보냅니다. 모든 노드가 이전 상태로 되돌아가서 부분적인 데이터가 남지 않도록 합니다.
이 아키텍처 선택에는 명확한 트레이드오프가 있습니다:
- 장점 (원자성): 2PC는 트랜잭션이 모든 참여 노드에서 성공하거나 모두 실패하도록 보장합니다. 단순한 복제 모델에서 발생하는 부분 업데이트 위험을 제거하여 데이터 무결성의 “골드 스탠다드"를 제공합니다.
- 잠재적 위험 (Blocking 문제): 표준 2PC 구현에서 트랜잭션 코디네이터가 “Prepare” 단계 이후 “Commit” 신호를 보내기 전에 장애가 발생하면, 참여 노드들은 “Heuristic” 상태에 빠집니다. 영원히 돌아오지 않을 수도 있는 코디네이터를 기다리며 lock을 무한정 유지하게 되죠. 이는 시스템 전체의 리소스 고갈과 데드락으로 이어질 수 있습니다.
- Ignite의 해결책 (자동 복구): 이 문제를 완화하기 위해 Ignite는 정교한 자동 트랜잭션 복구 메커니즘을 내장하고 있습니다. 코디네이터가 장애를 일으키면, 영향받는 데이터의 나머지 프라이머리 및 백업 노드들이 서로 통신하여 트랜잭션 상태를 재구성합니다.
명시적 Lock
분산 클러스터 전체에서 작업을 조율하는 가장 직관적인 방법입니다. 파라미터를 통해 안전성과 성능 사이의 균형을 세밀하게 조정할 수 있습니다.
// Initialize or get a distributed lock with specific behaviors
IgniteLock lock = ignite.reentrantLock(
"reportGenerationLock", // Name: 클러스터 전체에서 lock의 고유 식별자
true, // failoverSafe: lock 소유자가 크래시하면 lock을 자동으로 해제
false, // fair: false(non-fair)면 FIFO 큐잉을 건너뛰어 처리량이 높아짐
true // create: lock이 없으면 생성
);
try {
// 데드락 방지를 위해 타임아웃과 함께 lock 획득 시도
if (lock.tryLock(10, TimeUnit.SECONDS)) {
try {
// Critical Section: 한 번에 하나의 노드/스레드만 실행 가능
System.out.println("Lock acquired! Performing cluster-wide task...");
} finally {
// lock은 반드시 해제
lock.unlock();
}
} else {
System.out.println("Could not acquire lock within 10 seconds. Task skipped.");
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
위 예제에서 주목할 점은 failoverSafe 파라미터와 tryLock 타임아웃입니다. Ignite는 단순한 도구가 아니라 데이터 그리드 기반의 시스템이기 때문에, 분산 환경의 고질적인 문제들을 다음과 같은 메커니즘으로 해결합니다.
- 노드 장애 시 자동 해제 (Node Failure Detection) Ignite 클러스터의 각 노드는 서로 **하트비트(Heartbeat)**를 주고받으며 상태를 실시간으로 모니터링합니다. 만약 위 코드에서 락을 보유한 노드가 비정상적으로 종료(Crash)되더라도 걱정할 필요가 없습니다. 클러스터가 해당 노드가 이탈(Left)했음을 감지하는 즉시, 그 노드가 소유했던 모든 락과 트랜잭션을 자동으로 해제하거나 롤백하기 때문입니다. 이는 Zookeeper의 임시 노드(Ephemeral Node)와 유사하게 락의 고착화를 방지하는 핵심 장치입니다.
- Implicit & Explicit Timeouts 분산 환경에서는 네트워크 지연으로 인해 lock 획득이 무한정 대기 상태에 빠질 수 있습니다. Ignite는 이를 두 가지 방식으로 방어하기 위에 명시적 타임아웃을 제공합니다. tryLock(10, TimeUnit.SECONDS)처럼 개발자가 직접 대기 시간을 설정하여 데드락을 방지할 수 있습니다. 또한 설령 개발자가 이를 빼 먹었더라도, Ignite 내부의 트랜잭션 타임아웃이나 토폴로지 변경 감지 메커니즘이 작동하여 시스템 전체가 멈추는 상황을 예방합니다.
- 데이터 소유권 기반의 관리 Ignite는 내부적으로 락을 특정 데이터(Key)에 대한 소유권으로 관리합니다. 이러한 구조 덕분에 클러스터 전체에 걸쳐 데이터 정합성을 유지하면서도, 필요한 노드들끼리만 빠르게 조율하는 효율적인 분산 처리가 가능해집니다.
분산 트랜잭션
Ignite의 가장 강력한 장점 중 하나는 단순히 “lock"만 제공하는 게 아니라 그 위에 트랜잭션 무결성을 제공한다는 점입니다. ZooKeeper 같은 도구가 데이터 외부에 존재하는 반면, Ignite의 lock은 데이터 그리드와 깊이 통합되어 있어 정교한 최적화가 가능합니다.
트랜잭션 동시성 모드: Ignite는 워크로드 경합 상황에 가장 적합한 lock 전략을 선택할 수 있게 해줍니다:
- Pessimistic Locking: 첫 번째 읽기 또는 쓰기 작업 시점에 즉시 lock을 획득합니다. 충돌하는 트랜잭션은 lock이 해제될 때까지 블로킹됩니다. 여러 스레드가 같은 레코드를 자주 다투는 고경합 시나리오에 “안전한” 선택입니다.
- Optimistic Locking: 실행 단계에서는 lock을 획득하지 않습니다. 대신 커밋 시점에만 버전 충돌을 검증합니다. lock 유지 시간을 최소화하므로 저경합 워크로드에서 훨씬 빠릅니다.
// Example: Pessimistic 트랜잭션 설정
try (Transaction tx = ignite.transactions().txStart(
TransactionConcurrency.PESSIMISTIC,
TransactionIsolation.REPEATABLE_READ)) {
// 여기서 즉시 lock 획득
cache.put("key1", "value1");
cache.put("key2", "value2");
tx.commit(); // 2PC 완료 후 lock 해제
}
“성능 치트키”: Colocation & 1PC: 일반적인 분산 lock은 보통 여러 번의 네트워크 왕복이 필요합니다. Ignite는 Data Colocation과 One-Phase Commit (1PC)을 통해 이 오버헤드를 완화합니다.
- 데이터 & lock Colocation:
@AffinityKeyMapped어노테이션을 사용하면 특정 lock이 보호하는 데이터와 정확히 같은 물리 노드에 위치하도록 보장할 수 있습니다. “분산 lock"이 “로컬 lock"이 되는 셈이죠.
class UserLock {
@AffinityKeyMapped
private String userId; // lock과 User 데이터가 같은 노드에 위치
}
- One-Phase Commit (1PC) 최적화: 데이터와 로직을 제대로 colocate하면, Ignite는 영향받는 모든 키가 단일 노드에 있음을 감지합니다. 이 경우 Ignite는 무거운 2PC를 자동으로 건너뛰고 1PC를 사용합니다.
일반 2PC: 코디네이터 ↔ 여러 노드 (여러 번의 네트워크 홉)
Ignite 1PC: 코디네이터 (로컬) → 단일 노드 (네트워크 홉 없음 또는 최소화)
- 이 Affinity Colocation과 1PC의 조합으로 Ignite는 ZooKeeper 같은 중앙집중식 시스템에서는 수학적으로 불가능한 처리량을 달성할 수 있습니다. 분산 lock에서 “분산” 페널티를 효과적으로 제거하기 때문이죠.
네이티브 객체 처리
Ignite는 단순 문자열뿐만 아니라 복잡한 객체 타입도 네이티브로 처리합니다. 수동 직렬화 없이 구조화된 lock 메타데이터를 저장할 수 있습니다. 이는 몇 가지 장점을 제공합니다.
- 개발 생산성: 타임스탬프, 소유자 ID, 커스텀 상태 플래그 등 구조화된 lock 메타데이터를 자바 객체로 직접 저장할 수 있습니다. 직렬화 보일러플레이트 코드를 작성할 필요가 없죠.
- 즉시 접근: Ignite는 바이너리 포맷을 사용하여 클러스터가 전체 객체를 역직렬화하지 않고도 특정 필드(예:
acquiredAt)만 읽을 수 있습니다. 분산 lock의 “조율” 부분을 매우 가볍게 유지할 수 있습니다.
// 풍부한 메타데이터 객체 정의
public class LockInfo {
private String owner;
private String reason;
private long timestamp;
}
// 값으로 직접 저장
cache.put("order_lock_123", new LockInfo("Node-A", "Inventory Update", now()));
SQL 지원
Apache Ignite는 기본적으로 키-밸류 저장소로 동작하지만, 데이터 그리드를 분산 관계형 데이터베이스처럼 다룰 수 있는 강력한 SQL 엔진을 갖추고 있습니다. Ignite는 원시 데이터와 함께 분산 SQL 인덱스를 유지하여 SQL을 지원합니다.
- 스키마 매핑: Ignite의 모든 “캐시"는 “테이블"에 매핑될 수 있습니다. “키"는 보통 Primary Key를 나타내고, “값”(주로 POJO나 Binary Object)은 컬럼을 나타냅니다.
- 분산 실행: SQL 쿼리를 실행하면, Ignite의 옵티마이저가 쿼리를 분해하여 관련 파티션을 보유한 모든 노드에 전송합니다. 각 노드는 자신의 메모리에서 로컬로 쿼리를 실행하고 결과를 최종 병합을 위해 반환합니다.
진짜 “킬러 기능"은 SQL과 Ignite의 트랜잭션 엔진 통합입니다. SQL이 종종 “최종적 일관성"인 단순한 NoSQL 저장소와 달리, Ignite는 ACID 트랜잭션 범위 내에서 SQL을 실행할 수 있습니다.
- DML의 암묵적 lock: 트랜잭션 내에서
UPDATE나DELETE문을 실행하면, Ignite가 영향받는 키를 자동으로 식별하고 앞서 설명한 2PC 프로토콜을 사용하여 필요한 키 레벨 lock을 획득합니다. - 복잡한 원자적 변경: 키-밸류 API 호출과 SQL 문을 단일 트랜잭션에서 혼합할 수 있습니다. 예를 들어, 키-밸류 API로 특정 lock 레코드를 가져온 다음 SQL로 수천 개의 관련 상태 행을 업데이트하는 것을 하나의 원자적 단위로 처리할 수 있습니다.
try (Transaction tx = ignite.transactions().txStart(PESSIMISTIC, REPEATABLE_READ)) {
// 1. 키-밸류 API: 특정 제어 레코드 lock
LockControl ctrl = lockCache.get("maintenance_lock");
// 2. SQL: 여러 레코드를 원자적으로 업데이트
String sql = "UPDATE Tasks SET status = 'CANCELLED' WHERE type = 'CLEANUP' AND locked = true";
taskCache.query(new SqlFieldsQuery(sql)).getAll();
// 3. Commit: KV get/lock과 SQL update 모두 2PC를 통해 커밋
tx.commit();
}
언어별 제한 사항
Ignite는 Java, .NET, C++, Python, Node.js 클라이언트가 있지만, 고급 기능은 언어마다 다릅니다:
- Java 클라이언트가 가장 완전한 기능 제공 (네이티브 구현)
- .NET은 강력한 지원이 있지만 Java보다 약간 뒤처짐
- Python/Node.js 클라이언트는 기본 작업은 지원하지만 트랜잭션 API와 고급 lock 모드가 없음
- C++ 클라이언트는 캐시 작업에 집중된 경량 버전
완전한 트랜잭션 지원이 필요하다면, 사실상 Java나 .NET을 써야 합니다. 라이선스 문제는 없습니다—Ignite는 Apache 2.0 라이선스입니다.
정리
- Redis보다 훨씬 높은 운영 복잡도를 가집니다. 분산 캐싱, 파티션 토폴로지, 리밸런싱에 대한 이해가 필요합니다.
- Ignite는 기본적으로 전체 데이터셋을 RAM에 로드합니다. 일반적인 프로덕션 배포에는 노드당 64GB 이상이 필요합니다. Off-heap 스토리지가 도움이 되지만 복잡도가 올라갑니다.
- 단순한 시스템보다 네트워크 통신이 많습니다. 백그라운드 작업(리밸런싱, 디스커버리)이 대역폭을 소모합니다.
- Ignite는 분산 캐싱과 lock이 둘 다 필요할 때 의미가 있습니다. lock만 필요하다면 과도한 선택입니다—조율 기본 요소 하나를 위해 전체 컴퓨트 그리드를 배포하는 셈이니까요.
모든 분산 데이터베이스는 단일 장애점을 제거하지만, 합의를 위해 여러 번의 네트워크 왕복이 필요합니다—단일 노드 시스템 대비 어느정도의 지연이 추가됩니다.
생각의 전환: 비동기 분산 메시지 시스템
가장 좋은 lock은 lock이 없는 것입니다.
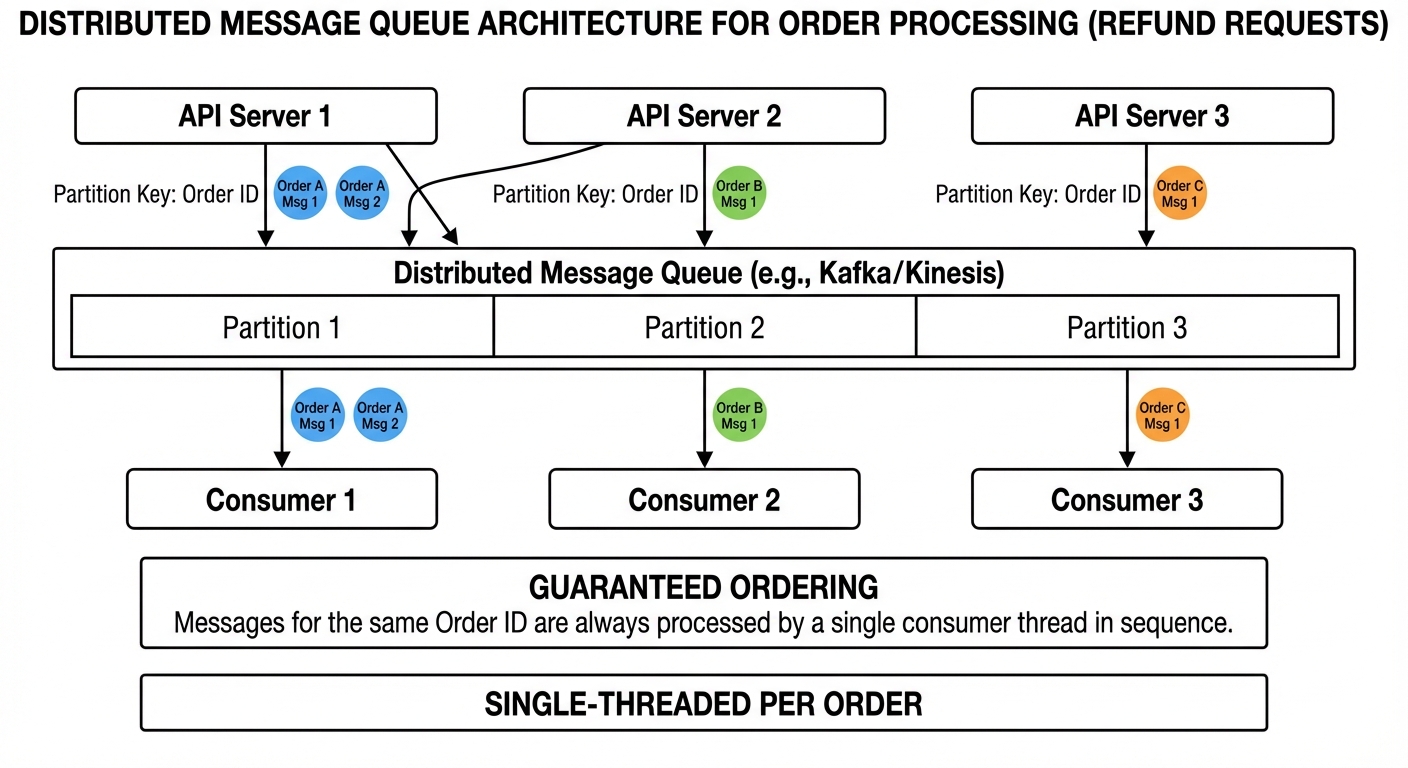
여러 서비스가 lock을 두고 경쟁하게 만드는 대신, 경쟁 조건 자체가 발생하지 않도록 문제를 재구성하세요. 환불 시나리오의 경우, 환불 요청을 메시지 큐에 발행하고 순차적으로 처리하면 됩니다—주문당 한 번에 하나의 요청만 처리하는 거죠.
파티션 키 전략
Kafka, Kinesis, Google Cloud Pub/Sub 같은 메시지 시스템은 파티션 키 기반 순서 보장을 지원합니다:
- 환불 요청을 발행할 때, 주문 ID를 파티션 키로 설정합니다
- 메시지 시스템이 같은 키를 가진 모든 메시지를 같은 파티션으로 라우팅합니다
- 각 파티션은 한 번에 하나의 컨슈머만 처리합니다 (하나의 컨슈머가 여러 파티션을 처리할 수는 있습니다)
- 파티션 내의 메시지는 순서대로 처리됩니다
병렬성은 파티션 개수로 제한됩니다. 파티션이 10개라면, 해당 토픽에 대해 10개를 초과하는 컨슈머 인스턴스를 효과적으로 사용할 수 없습니다.
주문 12345에 대한 모든 환불 요청은 같은 파티션으로 라우팅되어 순차적으로 처리됩니다. lock이 아니라 메시지 순서를 통해 직렬화가 이루어지는 셈이죠.
결국 파티션 키로 순서가 보장되면, 남은 책임은 처리 로직을 멱등하게 만드는 것뿐입니다.
# 발행 측 (API 서버)
def request_refund(order_id: str, amount: float):
refund_id = generate_unique_id() # 멱등성 토큰
message = {
'refund_id': refund_id,
'order_id': order_id,
'amount': amount,
'timestamp': time.time()
}
# Kafka 예시 - 파티션 키로 순서 보장
producer.send(
topic='refund-requests',
key=order_id, # 핵심: 같은 주문은 항상 같은 파티션으로
value=message
)
return {'status': 'processing', 'refund_id': refund_id}
# 컨슈머 측 (별도 워커 프로세스)
import psycopg2
def process_refund_message(message):
refund_id = message['refund_id']
order_id = message['order_id']
amount = message['amount']
conn = psycopg2.connect("dbname=orders user=app")
try:
with conn:
with conn.cursor() as cur:
# unique constraint를 이용한 원자적 멱등성 검사
# refund_id가 이미 존재하면 INSERT가 실패하고 처리를 건너뜀
try:
cur.execute(
"INSERT INTO processed_refunds (refund_id, order_id, amount, processed_at) "
"VALUES (%s, %s, %s, NOW())",
(refund_id, order_id, amount)
)
except psycopg2.IntegrityError:
# 이미 처리됨, 건너뜀
conn.rollback()
return
# 주문 검증 및 업데이트
cur.execute("SELECT total_amount, refunded_amount FROM orders WHERE id = %s", (order_id,))
order = cur.fetchone()
if order and order[1] + amount <= order[0]:
cur.execute(
"UPDATE orders SET refunded_amount = refunded_amount + %s WHERE id = %s",
(amount, order_id)
)
# 컨텍스트 종료 시 트랜잭션이 자동으로 커밋됨
process_payment_reversal(order_id, amount)
finally:
conn.close()
중요한 디테일: processed_refunds 테이블에는 refund_id에 대한 unique constraint가 필요합니다. 데이터베이스가 원자적으로 멱등성을 보장하는 거죠—두 컨슈머가 같은 메시지를 처리하더라도 하나의 INSERT만 성공합니다.
기술 선택과 차이점
Kafka 파티션은 토픽 생성 시 고정됩니다. 컨슈머 그룹 내 각 파티션은 정확히 하나의 컨슈머에게만 할당됩니다. 컨슈머가 죽으면 Kafka가 리밸런싱해서 파티션을 다른 컨슈머에게 재할당합니다. 병렬성을 높이려면 더 많은 파티션으로 새 토픽을 만들고 컨슈머를 마이그레이션해야 합니다. 운영 복잡도를 감당할 수 있고 엄격한 순서 보장이 필요하다면 Kafka를 선택하세요.
AWS Kinesis는 다운타임 없이 샤드 분할과 병합을 동적으로 지원합니다. 파티션 키 메커니즘은 비슷하지만, 운영상 스케일링이 더 유연합니다. AWS 네이티브 환경이고 재배포 없이 처리량을 조정해야 한다면 Kinesis를 선택하세요.
Google Cloud Pub/Sub의 ordering key는 정상 운영 시 리전 내에서 강한 순서 보장을 제공합니다. 하지만 리전 장애나 메시지 재할당을 트리거하는 장시간 클라이언트 연결 끊김 시 순서가 깨질 수 있습니다. 엄격한 순서 보장이 정확성에 필수적이라면 Pub/Sub은 피하세요.
일관성 모델 변경
이 접근법은 강한 일관성에서 Eventual Consitency로 전환합니다. 동기식 lock을 쓰면 환불이 즉시 보이지만, 메시지 큐를 쓰면 처리 지연이 생깁니다—잠재적으로 수 초에서 수 분까지요.
API가 read-your-writes 일관성이 필요하다면 (사용자가 환불 직후 잔액을 확인), 상태 폴링을 구현하세요:
# 상태 엔드포인트
def get_refund_status(refund_id: str):
result = db.query(
"SELECT status, processed_at FROM processed_refunds WHERE refund_id = %s",
(refund_id,)
)
if result:
return {'status': 'completed', 'processed_at': result[0]}
return {'status': 'processing'}
# 클라이언트는 환불 요청 후 이 엔드포인트를 폴링
아키텍처 영향
동기식 lock에서 비동기식 이벤트 기반 흐름으로 전환하는 건 상당한 영향을 미칩니다:
장점:
- lock 경쟁이나 타임아웃 처리가 없음
- 큐 깊이를 통한 백프레셔 기본 제공
- 파이프라인에 처리 단계 추가가 쉬움
- 재시도 로직이 더 단순함
단점:
- 즉각적인 응답을 제공할 수 없음 (환불이 “처리중”)
- 작업 상태를 추적할 별도 시스템 필요
- 요청 흐름이 여러 서비스에 걸쳐 있음
- 컨슈머 지연 모니터링이 운영에 필수적
작동하지 않는 경우
메시지 순서 보장이 모든 분산 lock 시나리오를 대체하지는 못합니다:
- 선출/리더 선택: 메시지 처리가 아니라 능동적 조정이 필요함
- 글로벌 속도 제한: 서비스 간 실시간 조정 필요
- 엔티티 간 원자적 연산: 환불이 주문, 사용자 지갑, 판매자 잔액을 원자적으로 업데이트해야 한다면, 단일 파티션 순서 보장으로는 해결되지 않습니다. 이를 해결하려면 보상 로직이 있는 사가 패턴이나 분산 트랜잭션이 필요한데—둘 다 상당한 복잡도를 추가하며 이 글의 비교 범위를 넘어섭니다.
메시지 시스템은 작업을 비동기적으로 처리되는 단일 엔티티 업데이트로 분해할 수 있을 때 작동합니다. 동기식 엔티티 간 트랜잭션이나 사용자에게 즉각적인 일관성이 필요하다면, 여전히 lock이나 트랜잭션 보장이 필요합니다.
결론: 적재적소의 도구 선택
분산 lock은 단일 기법이 아니라 트레이드오프의 스펙트럼입니다. Redis의 SET NX EX는 레이트 리미팅과 간단한 조정을 밀리초 이하의 레이턴시로 처리합니다. PostgreSQL advisory lock은 이미 관계형 데이터베이스를 쓰고 있다면 내구성과 트랜잭션 일관성을 제공합니다. Zookeeper와 etcd는 클러스터 조정을 위한 강력한 보장을 제공합니다. 메시지 큐는 이벤트 기반 워크플로우에서 lock 자체를 우회합니다.
잘못된 선택은 성능 이상의 비용을 초래합니다. API 레이트 리미팅에 Zookeeper를 돌리면 아무런 이득 없이 운영 복잡도만 높아집니다. 금융 트랜잭션에 Redis lock을 쓰면 장애 조치(failover) 중 데이터 손실 위험이 있습니다. 높은 처리량의 캐싱에 데이터베이스 lock을 쓰면 병목이 생깁니다.
제약 조건에 맞춰 솔루션을 선택하세요:
- Redis: 매우 낮은 레이턴시가 필요하고, 장애 조치 중 lock 손실을 감수할 수 있으며, 간단한 조정이 필요한 경우
- 분산 데이터베이스: 트랜잭션 일관성이 필요하고, 이미 데이터베이스 작업을 관리 중이며, 어느정도의 레이턴시를 허용할 수 있는 경우
- 조정 서비스 (Zookeeper/etcd): 리더 선출, 설정 관리, 클러스터 상태 관리—속도보다 정확성이 중요한 경우
- 메시지 큐: 큐를 통한 직렬화로 락 경합을 완전히 제거할 수 있는 이벤트 기반 아키텍처
알고리즘 선택보다 운영 관점이 성공을 좌우합니다. Redlock을 완벽하게 구현해도 락 획득 시간을 모니터링하지 않고 SLA를 초과하는 타임아웃에 대한 알림을 설정하지 않으면 실패합니다. 데이터베이스 advisory lock은 쿼리 타임아웃 추적 없이는 보이지 않는 데드락이 됩니다. 관찰 가능성—락 보유 시간, 획득 실패, 타임아웃 비율—없이는 분산 시스템을 눈 감고 디버깅하는 셈이죠.
모든 것을 계측하세요: 락 획득 레이턴시, 보유 시간, 타임아웃 빈도, 재시도 패턴. 비정상적인 락 지속 시간이 장애로 확산되기 전에 알림을 설정하세요. 스테이징 환경에서 장애 시나리오를 테스트하세요: 네트워크 파티션, 시계 편차, 락 보유 중 프로세스 크래시.
안정성 요구사항을 충족하는 가장 단순한 솔루션을 선택한 다음, 관찰 가능성을 확보하는 데 집중 투자하세요. 이것이 프로덕션에서 분산 락이 작동하는 방식입니다.