Intro: AI 시대에도 여전히 Clean Code가 중요한 이유
요즘 “코딩은 AI가 다 해준다"고 홍보하는 툴들이 쏟아지고 있습니다. 저도 이것저것 써봤는데, 한 가지 분명한 패턴이 보이더군요. AI는 일종의 ‘진공 상태’에서 코드를 짭니다. 당장 파일 몇 개만 건너뛰어도 마주하게 되는 우리 프로젝트의 지저분한 현실이나 복잡한 맥락은 전혀 고려하지 못하죠.
AI가 코드를 뱉어내는 속도가 빠를수록, 주의를 기울이지 않으면 제 코드베이스가 순식간에 악몽으로 변할 수 있겠다는 생각이 들었습니다. 그래서 다시 기본으로 돌아가 봤습니다. 애초에 우리가 왜 Clean Code를 부르짖기 시작했을까요? ChatGPT가 나오기 훨씬 전, ‘엉클 밥’으로 불리는 로버트 C. 마틴은 그의 책에서 이렇게 말했습니다.
“사실 코드를 짜는 시간보다 읽는 시간이 10배가 넘습니다. 우리는 새로운 코드를 작성하기 위해 끊임없이 예전 코드를 읽고 또 읽어야 합니다.” - 로버트 C. 마틴
AI가 등장했다고 해서 이 비율이 달라지진 않았습니다. 여전히 우리는 기존 코드를 읽고, 이해하고, 이리저리 뜯어보는 데 대부분의 시간을 씁니다. ‘타이핑’은 AI가 대신 해줄지 몰라도, 그 코드가 무슨 짓을 하는지, 전체 구조와 어떻게 맞물리는지, 정말 제대로 동작하는지 검증하는 건 결국 개발자의 몫이니까요.
코드베이스를 젠가 탑이라고 생각해보죠. AI는 그 어느 때보다 빠르게 블록을 건네줍니다. 하지만 기초부터 신중하게 쌓지 않으면, 나중에 블록 하나를 빼려는 순간 와르르 무너져 내릴 겁니다. 사소한 편법들, “일단 돌리고 나중에 정리해야지” 하며 미뤄둔 부채, 모호하게 지은 변수명들이 시간이 지나며 스노우볼처럼 불어나는 셈이죠.
우리의 목표는 변하지 않았습니다. 비즈니스 가치를 ‘지속 가능하게’ 계속 전달하는 것입니다. Clean Code는 단순히 코드를 예쁘게 짜거나 이론을 따지자는 게 아닙니다. 다음 달에도, 다음 분기에도, 내년에도 기능을 문제없이 배포할 수 있는 능력을 유지하자는 생존 전략입니다. 코드베이스가 스파게티가 되어 읽을 수 없게 되면, AI가 신규 코드를 아무리 빨리 짜준들 전체 개발 속도는 ‘0’으로 수렴하게 됩니다.
Clean Code 원칙은 AI 시대에도 여전히 유효할 뿐만 아니라, 오히려 그 어느 때보다 중요해졌습니다. 우리가 코드를 빨리 만들어낼 수 있다는 건, 그만큼 더 빨리 난장판을 만들 수 있다는 뜻이기도 하니까요.
클린 코드의 본질: 협업을 위한 보편적인 약속
애자일 선언문(Agile Manifesto)에서는 지속 가능한 개발과 끊임없는 기술적 우수성을 강조합니다. 클린 코드는 이런 목표와 동떨어진 별개의 개념이 아닙니다. 오히려 이를 달성하기 위한 핵심 수단이죠. 읽기 힘든 코드는 매 스프린트마다 발목을 잡고, 결국 기술 부채라는 빚더미를 안겨줍니다.
경제적 현실: 읽기 vs 쓰기
개발자는 코드를 작성하는 시간보다 읽는 시간에 훨씬 더 많은 에너지를 씁니다. 보자마자 무슨 뜻인지 머릿속으로 한 번 더 해석해야 하는 함수명, 눈을 부릅뜨고 따라가야 하는 중첩된 조건문, Git 히스토리 저편에 묻혀버린 암묵적인 가정들… 이런 요소들은 모든 작업 속도를 갉아먹는 주범입니다.
클린 코드는 근본적으로 세 가지 비용 문제를 해결해 줍니다.
읽기 비용 최소화: 코드는 처음 읽었을 때 바로 이해돼야 합니다. 한번 비교해 보시죠.
def calc(x, y, z):
return (x * y) * (1 + z)
vs.
def calculate_order_total_with_tax(subtotal, quantity, tax_rate):
# 예시: subtotal=$100, quantity=2, tax_rate=0.20 → $240
return (subtotal * quantity) * (1 + tax_rate)
두 번째 버전은 ‘이게 무슨 값이지?’ 하고 추측할 여지를 없애버립니다. 6개월 뒤에 본인이 다시 보거나 동료가 코드를 수정해야 할 때, 명시적인 변수명 덕분에 앞뒤 문맥을 뒤져가며 로직을 역추적할 필요 없이 즉시 의도를 파악할 수 있죠.
의도 명확화: 작성자의 의도가 명확하면 새로 합류한 팀원의 온보딩 속도가 빨라지고, 숨어 있던 버그도 금방 수면 위로 드러납니다. 코드 수정도 훨씬 자신감 있게 할 수 있고요.
문제 분해: 복잡한 문제를 잘 지은 이름을 가진, 한 가지 일만 하는 함수들로 쪼개 놓으면 그 자체로 훌륭한 문서 역할을 합니다. 각 함수는 온갖 로직이 뒤엉킨 거대한 벽이 아니라, 명확한 하나의 아이디어를 대변하게 되는 셈이죠.
프로그래밍에 국한된 문제가 아니다
전문 레스토랑 주방을 생각해 봅시다. 도구와 식재료는 항상 정해진 위치에 있습니다. 그래야 압박감이 심한 상황에서도 누구나 효율적으로 일할 수 있으니까요. 시프트 중간에 투입된 수셰프가 중식도를 찾아 헤매거나, 어떤 통에 향신료이 들어있는지 고민하지 않습니다. 이런 규칙은 셰프 개인의 취향 문제가 아닙니다. 좁은 공간에서 여러 사람이 일할 때 동선이 꼬이거나 사고가 나는 것을 막기 위한 생존 전략입니다.
소프트웨어 개발도 마찬가지입니다. 일관된 네이밍 컨벤션, 예측 가능한 파일 구조, 명확한 관심사의 분리… 이런 공유된 규칙들은 협업에 들어가는 불필요한 비용을 확 줄여줍니다.
AI 개발 도구들도 클린 코드 환경에서 훨씬 더 똑똑하게 동작합니다. Claude Code 같은 도구는 주변 코드가 명확하고 일관된 패턴을 따를 때, 훨씬 더 영양가 있는 제안을 내놓거든요. 결국 사람 간의 협업을 돕는 관행이 AI와의 협업 효율도 높여주는 셈입니다.
규칙을 깨야 할 때
클린 코드가 절대적인 교리는 아닙니다. 쓰고 버릴 일회성 스크립트, 빠르게 검증해 볼 프로토타입, 단발성 마이그레이션 코드에 완벽한 네이밍을 고민할 필요는 없죠. 성능이 극도로 중요한 내부 루프에서는 구현의 흐름을 한눈에 보기 위해 의도적으로 짧은 변수명을 쓰기도 합니다.
핵심은 ‘의식적인 판단’입니다. 내가 지금 기술 부채를 만들고 있다는 사실과 그 이유를 정확히 인지해야 합니다.
하지만 수년 동안 살아남아 팀원들의 손을 타게 될 대부분의 프로덕션 코드는 클린 코드 원칙을 지키는 게 무조건 이득입니다. 함수 이름 하나를 고민하는 데 쓴 5분이, 전체 코드베이스의 수명 주기 동안 수십 시간을 아껴줄 테니까요.
AI 와 Clean Code
AI 코딩 어시스턴트는 세션 간 지식을 유지하지 않습니다. 내일 새 세션을 시작하면 AI는 오늘 작업한 내용을 싹 잊어버리죠. 세션 내에서는 대화 내역을 기억하지만, 요청할 때마다 관련 코드를 컨텍스트로 불러와야 하는 건 마찬가지입니다. 임베딩(semantic search), AST 파싱, 의존성 그래프 분석, LSP 정보 같은 다양한 메커니즘을 사용해 코드베이스에서 파일을 긁어오고, 이걸 컨텍스트 윈도우에 밀어 넣는 식이죠. 결국 코드가 얼마나 깔끔한지에 따라 AI가 참고해야 할 컨텍스트 양이 결정되고, 문제 해결을 위해 머리를 굴릴 공간이 얼마나 남는지가 판가름 납니다.
컨텍스트 비용 문제
집중력 저하(Attention degradation): 모델은 컨텍스트가 너무 길어지면 정보를 정확히 참조하는 데 애를 먹습니다. 연구 결과에 따르면 ‘중간 소실’ 현상이 발생한다고 하죠. 10만 토큰 속에 파묻힌 정보는 기술적으로는 윈도우 안에 들어와 있어도, 모델이 끄집어내서 추론하기가 훨씬 어렵습니다.
토큰 세금(The Token Tax): 지저분한 코드 한 줄 한 줄이 AI의 추론 능력을 갉아먹는 ‘세금’이라는 사실을 종종 잊곤 합니다. Claude Code 같은 도구는 메시지 제한과 컨텍스트 오버헤드가 엄격하거든요. 프로젝트가 난잡하다면 AI에게 ‘쓰레기’를 먹이느라 비싼 비용을 치르는 셈입니다. 코드가 모듈화되어 깔끔하다면 한 번의 프롬프트에 더 많은 핵심 로직을 담을 수 있습니다. 결과적으로 환각(hallucination)은 줄어들고, 그 무서운 “사용량 제한에 도달했습니다” 알림을 보기 전까지 훨씬 빠르게 작업을 반복할 수 있습니다.
컨텍스트가 비대해지면 이런 일이 벌어집니다. 주문 처리 함수에 유효성 검사 로직을 추가해달라고 했다고 칩시다. 깔끔한 코드라면 AI는 함수(50줄)와 검증 유틸리티 모듈(100줄)만 불러옵니다. 하지만 엉망인 코드라면요? 관심사가 뒤섞인 함수(200줄), 여기저기 흩어진 세 가지 검증 패턴, 데이터 타입을 파악하기 위한 DB 모델, 어떤 검증을 적용할지 확인하기 위한 설정 파일까지 다 필요해집니다. 딱 필요한 150 토큰 대신 2,000 토큰어치의 꼬인 의존성을 로딩하게 되는 거죠. 정보가 소음 속에 파묻혀 있으니, AI는 이 케이스에 어떤 패턴을 적용해야 할지 갈피를 못 잡고 엉뚱한 검증 코드를 짜내놓게 됩니다.
로봇 청소기 대입법
간단히 말해, AI와 코딩하는 건 로봇 청소기를 쓰는 것과 비슷합니다.
바닥에 장애물이 널려 있고 전선이 엉켜 있다면 로봇 청소기는 짐만 될 뿐입니다. 빗자루질을 직접 하는 것보다 로봇을 ‘구조’하거나 미리 바닥을 치우는 데 시간을 더 쓰게 되니까요. 반대로 방이 정돈되어 있고 바닥이 평평하다면? 그냥 침대에 누워서 명령만 내리면 끝입니다.
AI도 마찬가지입니다. 코드베이스가 뒤엉킨 의존성과 ‘장애물’ 투성이라면 AI는 턱턱 걸려서 멈춰버립니다. 하지만 아키텍처가 깔끔하고 ‘평평’하다면, 명령만 내리고 작업이 완료되는 걸 지켜보기만 하면 됩니다.
Architecture over Implementation
그렇다면 어떻게 해야 ‘AI 친화적인’ 방을 만들 수 있을까요?
좋은 소식은 이제 여러분이 코드 한 줄 한 줄을 직접 짤 필요가 없다는 겁니다. 역할이 바뀐 거죠. 더 이상 빗자루질을 하는 청소부가 아니라, ‘아키텍트’가 되어야 합니다. 여러분의 주된 책임은 AI가 따를 수 있는 올바른 패턴과 구조를 정의하는 것입니다.
제가 코드베이스의 유지보수성을 지키기 위해 자주 사용하는 방법론들과 개요를 소개합니다.
제안 1: DDD와 Bounded Context
코드를 수정할 때, 개발자는 이 변경이 어디랑 엮여 있는지 파악해야 하죠. 도메인 주도 설계(DDD) 의 Bounded Context가 바로 그 지도를 제공해 줍니다. 인증 코드가 결제 코드와 분리되어 있는 건 단순히 기술적으로 계층을 나눴기 때문이 아닙니다. 서로 다른 규칙이 적용되는 서로 다른 도메인이기 때문입니다.
1. 기술 레이어보다 도메인 정렬 (Domain Alignment)
DDD는 관점을 기술적 구현에서 핵심 비즈니스 로직으로 옮겨줍니다. 기술은 그저 거들 뿐이죠. 이렇게 정렬해 두면 소프트웨어 아키텍처가 비즈니스 요구사항에 맞춰 함께 진화하게 됩니다. 기술적인 결정 때문에 비즈니스 규칙이 망가지는 일이 없는, 탄탄한 구조를 만들 수 있습니다.
2. 보편 언어(Ubiquitous Language): 일관성이 핵심아다
보편 언어란 코드, 문서, 명세서에서 토씨 하나 틀리지 않고 동일한 용어를 쓰는 것을 말합니다.
- 일관성 없음 (고위험): 코드는
UserAccount, 스펙은Customer profile, 프롬프트 요청 시엔Subscriber라고 씁니다. 이러면 AI는 이게 다 같은 대상인지 눈치껏 때려 맞춰야 합니다. - 일관성 있음 (저위험): 모두가
Customer를 씁니다. “유저 구매 내역 추적 필드 좀 추가해 줘"라고 말하는 대신, “Sales 컨텍스트의 Customer Aggregate에 purchaseHistory를 추가해 줘” 라고 말하는 겁니다. 명확한 네이밍이 있어야 명확한 프롬프트도 가능해집니다.
3. Aggregate: 범위 정의하기
Aggregate는 비즈니스 규칙이 항상 준수되도록 보장하는 경계 역할을 합니다. 즉, 데이터가 변경될 때 함께 수정되어야 하는 범위와 일관성이 유지되어야 하는 범위를 정의합니다.
// Order 애그리거트는 내부의 비즈니스 규칙(불변식)을 직접 관리합니다.
class Order {
private lines: OrderLine[] = [];
private total: Money;
// Good: 도메인 모델 내에서 비즈니스 로직을 완결성 있게 처리합니다.
addLine(productId: string, quantity: number, price: Money) {
const line = new OrderLine(productId, quantity, price);
this.lines.push(line);
this.recalculateTotal(); // "총액은 모든 항목의 합계와 같아야 한다"는 규칙 준수
}
private recalculateTotal() {
this.total = this.lines.reduce((sum, line) => sum.add(line.subtotal()), Money.zero());
}
}
// Bad: 외부에서 내부 상태를 직접 조작하게 두면 안 됩니다.
// order.lines.push(new OrderLine(...)); -> 총액 계산 로직이 누락되어 데이터 불일치 발생
4. Context Map: 경계와 관계
Context Map은 서로 다른 도메인들이 어떻게 상호작용하는지 명시적으로 보여줍니다.
- 데이터베이스 주의사항: 컨텍스트끼리 데이터베이스를 공유하면 스키마 마이그레이션이나 트랜잭션 공유 때문에 강한 결합이 생깁니다. 꼭 공유해야 한다면 스키마라도 분리하세요. 공유 DB 마이그레이션은 AI가 생성한 코드가 여러 컨텍스트를 동시에 터뜨리는 주원인입니다.
주요 관계 유형:
- Shared Kernel: 두 컨텍스트가 특정 모델(예:
Money)을 공유합니다. 양쪽 팀이 이 공유 코드를 수정할 때 서로 조율해야 합니다. - Customer-Supplier: 한 컨텍스트(Order)가 다른 컨텍스트(Catalog)의 안정적인 API에 의존하는 구조입니다.
- Anticorruption Layer (ACL): Order 컨텍스트는 Catalog의 내부 모델을 직접 쓰지 않고, 어댑터를 통해 번역해서 사용합니다. AI가 레거시 시스템이나 서드파티 API와 연동할 때 아주 중요합니다.
5. “Shared” 쓰레기통 피하기
그냥 shared나 common 모듈 하나 만들어놓으면, 나중엔 모든 게 서로 의존하는 쓰레기통이 되어버립니다. 뭐 하나 고치면 사방에 파장이 퍼지고, AI 도구들도 도대체 뭘 수정해도 안전한지 판단을 못 하게 되죠.
공통 로직은 명시적인 Shared Kernel(예: /src/shared_kernel)로 빼내되, 최대한 가볍게 유지하세요. 이건 아주 안정적이고 최소한의 계약(Contract)으로 취급해야 합니다. 커널이 작을수록 결합도도 낮아지니까요.
컨텍스트 경계가 무너지고 있다는 위험 신호들:
- AI가 제안하는 수정 사항이 자꾸 한 번에 여러 컨텍스트를 건드린다.
- 똑같은 엔티티 이름이 여러 컨텍스트에 있는데 명확히 구분이 안 된다.
- 간단한 기능 하나 넣는데 여러 컨텍스트 간의 조율이 엄청나게 필요하다.
제안 2: 헥사고날 아키텍처 (Hexagonal Architecture)
헥사고날 아키텍처(포트와 어댑터, Ports and Adapters라고도 함)는 단순하지만 아주 결정적인 문제를 해결해 줍니다. 바로 PostgreSQL을 MySQL로 교체하거나 Express를 Fastify로 갈아탈 때, 비즈니스 로직이 와르르 무너지는 사태를 막는 것입니다.
도메인 격리와 테스트 용이성
핵심 원칙은 명확합니다. 도메인 로직을 인프라 의존성이나 프레임워크로부터 철저히 분리하세요. 비즈니스 규칙 입장에서는 데이터가 DB에서 오든, 메시지 큐에서 오든, HTTP API를 타고 들어오든 전혀 알 필요도, 관심을 가질 필요도 없어야 합니다.
// Bad: 도메인 로직이 인프라와 결합됨
class OrderService {
async createOrder(items: Item[]) {
const order = new Order(items);
// PostgreSQL 클라이언트에 직접 의존
await pgClient.query('INSERT INTO orders...', order);
// RabbitMQ에 직접 의존
await rabbitMQ.publish('order.created', order);
return order;
}
}
// Good: 도메인 로직이 격리됨
class OrderService {
constructor(
private orderRepository: OrderRepository, // Port (인터페이스)
private eventPublisher: EventPublisher // Port (인터페이스)
) {}
async createOrder(items: Item[]): Promise<Order> {
const order = new Order(items);
await this.orderRepository.save(order);
await this.eventPublisher.publish('order.created', order);
return order;
}
}
이러한 격리는 즉각적으로 두 가지 이점을 줍니다:
- 테스트가 정말 쉬워집니다 - 인터페이스만 mocking만 하면 되니 DB나 메시지 큐를 띄울 필요가 없습니다.
- 인프라 변경의 여파가 비즈니스 로직까지 튀지 않습니다 - 도메인 코드는 그대로 둔 채 구현체만 쏙 갈아끼울 수 있습니다.
도메인보다 자주 변하는 인프라
백엔드 시스템의 현실을 한번 봅시다:
- 인프라 변경: DB 마이그레이션, 메시지 브로커 교체, 프레임워크 도입, REST에서 gRPC로 전환 등
- 도메인 변경: 비즈니스 규칙, 가격 정책 로직, 주문 워크플로우 등
인프라는 끊임없이 진화합니다. 반면 도메인 로직은 한번 자리를 잡으면 변경 빈도가 훨씬 낮죠. 헥사고날 아키텍처는 이 ‘변경 빈도의 비대칭성’을 인정합니다. 그래서 인프라는 언제든 갈아끼울 수 있게 열어두고, 도메인 코드는 단단하게 지키는 구조를 취하는 겁니다.
실제로 도메인 로직은 단 한 줄도 건드리지 않고 DB나 프레임워크를 통째로 들어내는 팀들을 봐왔습니다. 코어(Core)가 격리되어 있으니 팀은 오로지 ‘포팅’ 작업에만 에너지를 쏟을 수 있었고, 비즈니스 로직이 망가질까 걱정할 필요가 없었죠. 이게 바로 제대로 된 추상화가 주는 진짜 위력입니다.
의존성의 방향이 핵심이다
기존 레이어드 아키텍처:
도메인 → DB 라이브러리 → PostgreSQL
도메인 → 프레임워크 → Express
헥사고날 아키텍처:
도메인 ← 리포지토리 어댑터 → PostgreSQL
도메인 ← HTTP 어댑터 → Express
헥사고날 아키텍처에서 의존성은 항상 안쪽을 향합니다. 도메인은 인터페이스를 정의할 뿐이고, 인프라가 그것을 구현하는 식이죠. 도메인 코드에서는 인프라 패키지를 절대 import 하지 않습니다.
// 도메인 계층이 계약을 정의함
interface OrderRepository {
save(order: Order): Promise<void>;
findById(id: string): Promise<Order | null>;
}
// 인프라 계층이 이를 구현함
class PostgresOrderRepository implements OrderRepository {
constructor(private pool: pg.Pool) {}
async save(order: Order): Promise<void> {
// PostgreSQL 전용 구현
}
async findById(id: string): Promise<Order | null> {
// PostgreSQL 전용 구현
}
}
선택적 적용: 바운디드 컨텍스트 레벨에서만
제발 모든 곳에 헥사고날 아키텍처를 쓰려고 하지 마세요. 정말 중요한 포인트입니다.
바운디드 컨텍스트 단위로 적용하세요. 즉, 복잡한 비즈니스 로직이 있는 서비스들에 한해서 말이죠:
- 결제 처리 서비스
- 재고 관리 서비스
- 가격 책정 엔진 서비스
다음의 경우에는 적용하지 마세요:
- API 게이트웨이: 단순 라우팅과 조합 역할일 뿐, 도메인 로직이 없습니다.
- Composition services: 여러 서비스의 데이터를 긁어모으는 역할입니다.
- 단순 CRUD 서비스: 레이어를 나눠봤자 오버헤드만 늘고 가치는 없습니다.
- 내부 도구 및 어드민 패널: 아키텍처의 순수성보다는 실용성이 우선입니다.
- 부패 방지 계층 (ACL): 레거시와 신규 시스템 사이의 ‘번역기’라면 ACL 자체가 이미 어댑터입니다. 어댑터를 또다시 헥사고날로 감싸지 마세요. 불필요한 추상화 대신 매핑 로직 그 자체에 집중해야 합니다.
실제로 단순히 요청만 전달하는 API 게이트웨이에 헥사고날을 적용한 사례를 본 적이 있습니다. 결과는 참담했습니다. 얻는 건 하나도 없는데 레이어만 4개나 늘어나서 코드만 미친 듯이 복잡해졌죠. API 게이트웨이에는 보호해야 할 ‘도메인’이 없습니다. 애초에 도메인이 존재하지 않는데 도메인 계층이 왜 필요할까요?
실전 폴더 구조
src/
├── contexts/
│ ├── payment/ # 복잡한 도메인: 헥사고날 적용
│ │ ├── domain/ # 순수 비즈니스 로직
│ │ │ ├── model/ # 엔티티 & 값 객체
│ │ │ ├── service/ # 도메인 서비스 (유스케이스)
│ │ │ └── ports/ # 출력 인터페이스 (리포지토리/게이트웨이)
│ │ ├── adapters/ # 외부 구현체
│ │ │ ├── in/ # Driving: HTTP, CLI, 메시지 큐
│ │ │ └── out/ # Driven: Postgres, Stripe, Redis
│ │ └── index.ts # 컨텍스트 진입점 (DI)
│ │
│ ├── catalog/ # 단순 CRUD: 헥사고날 생략
│ │ ├── models.ts # 단순 DB 모델
│ │ ├── routes.ts # 직접 API 라우팅
│ │ └── services.ts # 기본 쿼리/커맨드 로직
│ │
│ └── shared_kernel/ # 최소한의 명시적 공유 로직
│ └── money.ts # 공유 값 객체
domain 폴더에는 인프라 관련 import가 단 하나도 없어야 합니다. 만약 도메인 코드에서 import pg from 'pg'나 import express from 'express'가 보인다면, 뭔가 잘못하고 있는 겁니다.
제대로 작동하고 있다는 증거
DB나 메시지 큐, HTTP 서버를 띄우지 않고도 전체 도메인 로직을 테스트할 수 있어야 합니다. 테스트 코드는 대략 이런 모습일 겁니다:
describe('OrderService', () => {
it('should create order and publish event', async () => {
const mockRepo = { save: jest.fn() };
const mockPublisher = { publish: jest.fn() };
const service = new OrderService(mockRepo, mockPublisher);
await service.createOrder([item1, item2]);
expect(mockRepo.save).toHaveBeenCalled();
expect(mockPublisher.publish).toHaveBeenCalledWith('order.created', expect.any(Order));
});
});
DB 설정도, 정리도, 네트워크 호출도 필요 없습니다. 테스트가 수 밀리초 안에 끝납니다.
헥사고날 아키텍처는 예쁜 다이어그램을 그리기 위한 것이 아닙니다. 인프라의 격변으로부터 비즈니스 로직을 보호하고, 외부 의존성 없이 코드를 테스트 가능하게 만드는 것이 핵심입니다. 필요한 곳에만 쓰고, 필요 없는 곳은 과감히 건너뛰세요.
제안 3: 모노레포(Mono-repo) 전략을 도입하세요
Bounded Context를 정의하고 나면, 본능적으로 각 도메인마다 별도의 리포지토리를 만들고 싶어집니다. 왠지 깔끔해 보이고 DDD 원칙에도 부합하는 것 같으니까요. 하지만 이런 방식은 겉보기와 달리 득보다 실이 큰, 엄청난 마찰을 만들어냅니다.
멀티레포의 생산성 비용
도메인을 넘나드는 리팩터링이 고통스러워집니다. 여러 컨텍스트가 참조하는 핵심 도메인 엔티티의 이름을 변경한다고 상상해 보세요. 여러 리포지토리를 오가며 PR 타이밍을 조율해야 합니다. 예를 들어 OrderContext가 CustomerId를 참조하고 있는데, CustomerContext 쪽에서 이를 CustomerAccountId로 리팩터링한다면? 리포지토리 간 릴리스 싱크를 맞추느라 진땀을 빼게 될 겁니다.
공유 코드에 패키지 버전 관리라는 짐이 지워집니다. 공통 유틸리티나 Value Object를 공유하려면 이를 내부 패키지로 분리해야 하는데요. 고작 Money 객체 하나 공유하자고 패키지를 퍼블리시하고, 시맨틱 버전을 관리하고, 모든 리포지토리의 의존성을 업데이트해야 하는 상황이 벌어집니다.
의존성 업데이트 작업이 기하급수적으로 늘어납니다. 보안 패치나 프레임워크 업그레이드가 필요할 때마다 모든 리포지토리에 일일이 PR을 날려야 합니다. 한 번에 끝날 업데이트가 거대한 조율 작업으로 변질되는 셈이죠.
DDD에 모노레포가 효과적인 이유
모노레포는 모든 Bounded Context를 하나의 리포지토리에 담되, 디렉터리 구조를 통해 논리적인 분리를 유지합니다.
/
├── apps/
│ ├── order-service/
│ ├── customer-service/
│ └── inventory-service/
├── packages/
│ ├── order-domain/
│ ├── customer-domain/
│ ├── inventory-domain/
│ └── shared-kernel/
└── tools/
apps/에 있는 각 애플리케이션은 배포 가능한 서비스이며, 도메인 패키지들을 import 해서 사용합니다.
// apps/order-service/src/handlers/createOrder.ts
import { Order, OrderId } from '@myapp/order-domain';
import { CustomerId } from '@myapp/customer-domain';
import { Money } from '@myapp/shared-kernel';
워크스페이스 프로토콜(pnpm workspaces, yarn workspaces, 또는 npm workspaces)이 패키지 해석(resolution)을 알아서 처리해 줍니다. 루트 package.json에 워크스페이스 구조를 정의하기만 하면 됩니다.
{
"name": "myapp-monorepo",
"private": true,
"workspaces": [
"apps/*",
"packages/*"
]
}
각 패키지와 앱은 저마다의 package.json으로 의존성을 관리하지만, 워크스페이스를 지원하는 패키지 매니저가 리포지토리 전체의 버전 관리와 중복 제거를 조율해 줍니다.
컨텍스트 간 원자성. Payment 도메인이 Order 도메인과 연동해야 한다면, 하나의 PR에서 모든 변경을 처리할 수 있습니다. CI 파이프라인이 전체를 한꺼번에 검증해 주니까요.
간편한 코드 공유. 공유 유틸리티, 도메인 이벤트, 통합 컨트랙트가 같은 리포지토리에 있습니다. 내부 패키지를 굳이 배포할 필요 없이 필요한 것만 import 하면 그만입니다.
중앙화된 의존성 관리. 보안 업데이트는 루트 레벨에서 딱 한 번만 하면 됩니다. 워크스페이스 도구가 모든 패키지의 버전을 일관되게 맞춰줍니다.
코드베이스 전체 가시성 확보. 모든 도메인을 동시에 검색할 수 있습니다. 컨텍스트 간의 상호작용을 파악하는 건 grep 명령 한 번이면 충분하죠.
모노레포 도구: Nx 파헤쳐보기
최신 도구들 덕분에 모노레포 운영이 훨씬 수월해졌습니다. 엔터프라이즈 애플리케이션과 DDD 구조에는 Nx가 가장 성숙한 선택지입니다.
Nx는 프로젝트의 의존성 그래프를 그려내고 태스크를 똑똑하게 실행합니다. 다음은 최소한의 nx.json 설정 예시입니다.
{
"tasksRunnerOptions": {
"default": {
"runner": "nx/tasks-runners/default",
"options": {
"cacheableOperations": ["build", "test", "lint"]
}
}
}
}
각 패키지에 프로젝트 의존성을 정의합니다.
// packages/order-domain/project.json
{
"name": "order-domain",
"targets": {
"build": {
"executor": "@nx/js:tsc",
"outputs": ["{workspaceRoot}/dist/packages/order-domain"]
},
"test": {
"executor": "@nx/jest:jest"
}
},
"implicitDependencies": ["shared-kernel"]
}
여러분이 shared-kernel을 수정하면, Nx는 order-domain과 이를 의존하는 모든 앱을 다시 빌드해야 한다는 걸 알아챕니다. 변경되지 않은 프로젝트는 캐시된 빌드 결과를 그대로 사용하죠. CI 관점에서 보면 “매번 모든 것을 빌드"하던 방식에서 “변경된 것만 빌드"하는 방식으로 바뀌면서 시간이 대폭 단축됩니다.
Nx는 다음과 같은 기능도 제공합니다.
- 개발자와 CI 서버 간의 리모트 캐싱
- 동시성을 설정할 수 있는 병렬 실행
- 변경 영향도 감지:
nx affected:test명령은 변경된 프로젝트에 대해서만 테스트를 수행
Turborepo는 파이프라인 최적화에 초점을 맞춘 가벼운 대안으로, TypeScript 환경에서 뛰어난 리모트 캐싱 성능을 보여줍니다. 설정은 더 간단하지만 기능은 Nx보다 적은 편입니다.
모노레포 ≠ 모놀리식
모노레포를 쓴다고 해서 모놀리식 애플리케이션을 만드는 건 아닙니다.
모노레포는 버전 관리 전략입니다. 모든 코드가 하나의 리포지토리에 사는 거죠.
모놀리스는 배포 아키텍처입니다. 모든 코드가 하나의 프로세스로 실행되는 겁니다.
모노레포에서도 각 Bounded Context를 독립된 서비스로 배포할 수 있습니다. order-service와 customer-service 디렉터리는 서로 다른 Docker 이미지로 빌드되어 독립적으로 배포되고, 확장되며, 장애가 나도 서로 격리됩니다.
모노레포는 개발의 편의성을 제공할 뿐입니다. 배포 전략은 스케일링 필요성, 팀 구조, 운영 요구사항에 따라 별도로 결정하면 되는 문제입니다.
현실적인 트레이드오프
모노레포가 무조건 정답은 아닙니다. 분명 까다로운 점들이 있습니다.
CI/CD 복잡도가 증가합니다. 서비스를 독립적으로 배포하려면, 어떤 서비스가 변경되었는지 감지해서 해당 Docker 이미지만 빌드하는 로직이 필요합니다. 커밋마다 무지성으로 전체를 다 빌드하는 순진한 CI는 시간 낭비일 뿐이죠. Nx의 affected 명령어 같은 도구나 커스텀 스크립트가 필수입니다.
Clone 사이즈가 커집니다. 수십 개의 서비스와 수년 치 히스토리가 쌓이면 모노레포는 비대해집니다. 초기 Clone 시간이 길어지고 Git 명령어도 느려지죠. 물론 Partial Clone 같은 전략이 도움이 되긴 합니다.
접근 제어가 둔탁해집니다. 멀티레포에서는 특정 리포지토리에만 접근 권한을 줄 수 있습니다. 반면 모노레포에서는 개발자가 보통 전체 코드베이스에 접근하게 되죠. 엄격한 보안 규정이 필요한 경우라면 모노레포는 권한 관리가 까다로울 수 있습니다.
배포 분리가 어려워질 수 있습니다. 서비스마다 릴리스 주기와 리스크 프로필이 다를 수 있습니다. 경계를 엄격하게 유지하지 않으면, 한 서비스의 변경이 불필요하게 다른 서비스의 빌드를 유발하는 “분산형 모놀리스"가 될 위험이 있습니다. 코드를 전혀 공유하지 않는 무관한 서비스들끼리 이런 일이 생기면, 같이 둠으로써 얻는 이득보다 격리를 유지하려는 비용이 더 커지게 됩니다.
Git 히스토리가 시끄러워집니다. 모든 도메인의 커밋이 한곳에 섞입니다. 관련 변경 사항을 찾으려면 커밋 컨벤션을 잘 지켜야 하고 도구의 도움도 받아야 합니다.
대부분의 팀(개발자 50~100명 이하, 서비스 20개 미만)에게는 이런 트레이드오프가 감당할 만한 수준이며, 생산성 향상이란 이점이 훨씬 큽니다. 그 이상의 규모가 되면 계산기가 좀 달라지겠죠. 구글이나 페이스북은 모노레포를 쓰기로 유명하지만, 수십억 라인의 코드를 감당하기 위해 자체 인프라를 구축했다는 점을 기억하세요.
제안 4: 마이크로서비스 vs 모놀리식
마이크로서비스는 만병통치약이 아닙니다. 컨퍼런스 발표나 기술 블로그의 화려한 겉모습에 혹해 준비도 안 된 상태에서 섣불리 마이크로서비스를 도입했다가, 감당 못 할 복잡도 때문에 고생하는 팀들을 수도 없이 봤습니다.
마이크로서비스의 숨겨진 비용
마이크로서비스는 코드의 복잡성을 분산 시스템의 복잡성으로 맞바꾸는 셈입니다.
데이터 흐름이 보이지 않게 됩니다. 모놀리식 환경에서는 디버거 하나면 요청 흐름을 코드 레벨에서 쭉 따라갈 수 있습니다. 하지만 마이크로서비스에서는 사용자 클릭 한 번이 5개 서비스에 걸친 HTTP 호출, 메시지 큐 이벤트, 비동기 작업의 연쇄 반응을 일으킬 수 있습니다. 뭔가 터졌을 때 디버깅하려면 분산 트레이 도구와 여러 로그 스트림을 엮어줄 Correlation ID가 필수적입니다.
테스트 난이도가 기하급수적으로 올라갑니다. 통합 테스트를 하려 해도 서비스 여러 개를 띄우고, 각자 테스트 DB를 관리하고, 서비스 경계 간의 상태까지 맞춰야 합니다. 거대한 통합 환경 없이 서비스 간 상호작용을 검증하려면 Pact 같은 계약 테스트 도구나 소비자 주도 계약(Consumer-driven contracts)이 강제됩니다.
운영 오버헤드가 배로 듭니다. 서비스마다 배포 파이프라인, 모니터링, 로그 수집, 장애 대응 절차를 따로 갖춰야 합니다. 애플리케이션 하나 운영하던 일이 순식간에 서비스 수십 개로 이루어진 함대를 지휘하는 상황으로 바뀝니다.
네트워크 신뢰성이 내 문제가 됩니다. 타임아웃, 재시도 로직, 서킷 브레이커, 서비스 메쉬의 복잡함까지 떠안아야 합니다. DB 쿼리로 ~5ms면 끝나던 작업이 네트워크 호출을 타면서 ~50ms가 걸리거나 아예 실패할 수도 있게 되죠. Istio나 Linkerd 같은 도구가 도와주긴 하지만, 이 또한 관리해야 할 인프라 레이어가 하나 더 늘어나는 셈입니다.
데이터 일관성 유지가 복잡해집니다. 단순한 DB 커밋으로 끝났던 트랜잭션이 분산 트랜잭션, 사가(Saga) 패턴, 결과적 일관성(Eventual Consistency) 같은 어려운 개념으로 변합니다. 서비스 간에는 외래 키(Foreign Key) 제약을 걸 수 없으니, 참조 무결성도 애플리케이션 코드에서 직접 챙겨야 합니다.
모놀리식이 더 나은 경우
다음과 같은 상황이라면 모놀리식으로 시작하세요.
- 도메인 경계가 불분명할 때: 초기 단계의 제품은 방향을 끊임없이 틉니다. 모놀리스 내부에서의 리팩토링은 좀 귀찮은 정도지만, 여러 마이크로서비스에 걸친 리팩토링은 악몽 그 자체입니다.
- 팀 규모가 작을 때 (< 10명): 마이크로서비스를 조율하는 비용이 코드베이스를 공유해서 얻는 이득보다 큽니다. 오히려 개발 속도만 느려질 뿐입니다.
- 독립적인 확장이 필요 없을 때: 애플리케이션 전체가 함께 확장되어야 한다면, 마이크로서비스는 이점 없이 복잡도만 높일 뿐입니다.
- 개발 속도가 최우선일 때: 이론적인 확장성보다는 당장의 기능 배포 속도가 더 중요할 때입니다.
- 보안 요구사항이 동일할 때: 앱의 모든 부분이 동일한 수준의 데이터 민감도를 가진다면, 수십 개의 연결 통로를 막는 것보다 하나의 보안 경계를 관리하는 게 훨씬 간단합니다.
마이크로서비스가 필요한 경우
다음 상황에서는 마이크로서비스를 고려해 볼 만합니다.
- 도메인 경계가 명확하고 안정적일 때: 사용자 관리, 결제 처리, 콘텐츠 전송 시스템 간의 교집합이 거의 없고, 각자 다른 이유로 변경이 발생할 때입니다.
- 독립적인 확장이 필요할 때: 비디오 트랜스코딩 서비스가 API 게이트웨이보다 50배 더 많은 리소스를 필요로 하는 경우입니다.
- 여러 팀이 독립적으로 움직여야 할 때: 팀 A가 팀 B의 코드 리뷰나 배포 일정을 기다리지 않고 자신의 서비스를 배포할 수 있어야 합니다.
- 특정 기술 요구사항이 있을 때: 추천 엔진은 Python의 ML 생태계를 써야 하고, 애플리케이션 API 계층은 Node.js나 Kotlin을 유지하고 싶을 때입니다.
- 민감 데이터를 격리해야 할 때: 결제 처리나 신원 관리 로직을 전용 서비스로 분리하면, 전체 코드베이스를 감사(Audit)할 필요 없이 해당 서비스만 엄격한 규정을 준수하면 됩니다.
언제 나눠야 할까?
단순한 감이 아니라 구체적인 신호가 보일 때 모듈을 별도 서비스로 떼어내세요.
- 확장성의 불일치: 특정 모듈이 다른 모듈보다 10배 이상의 트래픽을 처리해서 독립적인 인프라가 필요할 때
- 팀 간의 충돌: 3개 이상의 팀이 하나의 코드베이스를 건드리면서 잦은 머지 Conflict가 발생할 때
- 안정성의 차이: 어떤 도메인은 6개월 넘게 변경이 없는데, 다른 쪽은 매일 배포하며 빠르게 변할 때
- SLA의 차이: 일부 기능은 99.99%의 가동 시간이 필요하지만, 다른 부분은 어느 정도 다운타임을 허용할 때
유연한 코드베이스를 위한 패턴
‘모듈러 모놀리스(Modular Monolith)‘를 구축하세요. 단일 배포 단위 내에서도 강력한 논리적 경계를 세우는 겁니다. 기술 계층이 아니라 비즈니스 도메인별로 구조를 잡으세요. 각 모듈은 다음 원칙을 지켜야 합니다.
논리적으로 데이터를 소유하세요. 다른 모듈은 해당 모듈의 서비스 계층을 통해서만 데이터에 접근해야 하며, 절대 직접 DB 쿼리를 날려선 안 됩니다. 이렇게 하면 지금은 공유 DB를 쓰더라도 나중에 ‘서비스당 DB’ 구조로 분리하기 쉬워집니다.
// ❌ 이렇게 하지 마세요: 모듈 간 직접 DB 접근
const user = await db.query('SELECT * FROM users WHERE id = ?', userId);
const payment = await db.query('SELECT * FROM payments WHERE user_id = ?', userId);
// ✅ 이렇게 하세요: 모듈 API를 통한 접근
const user = await UserService.getById(userId);
const payment = await PaymentService.getByUserId(userId);
명확한 공개 API를 노출하세요. 어떤 함수가 외부용(Public)이고 어떤 것이 내부 구현용인지 정의해야 합니다.
// user-management/index.js
export { getById, authenticate, updateProfile } from './services/user-service';
// 내부 헬퍼 함수, 리포지토리 함수, 모델 등은 export 하지 않음
빌드 타임에 경계를 강제하세요. Nx 같은 도구를 사용하면 허가되지 않은 import를 막을 수 있습니다.
// nx.json - 의존성 제약 설정
{
"projects": {
"payment-processing": {
"tags": ["domain:payment"],
"implicitDependencies": []
},
"user-management": {
"tags": ["domain:user"],
"implicitDependencies": []
}
},
"targetDefaults": {
"lint": {
"options": {
"depConstraints": [
{
"sourceTag": "domain:payment",
"onlyDependOnLibsWithTags": ["domain:payment", "shared"]
},
{
"sourceTag": "domain:user",
"onlyDependOnLibsWithTags": ["domain:user", "shared"]
}
]
}
}
}
}
이렇게 설정하면 payment-processing이 실수로 user-management의 내부 코드를 import 하는 것을 막아줍니다. 경계를 위반하면 빌드 자체가 실패하니까요.
가장 어려운 부분: 데이터 마이그레이션
서비스를 쪼갠다는 건 결국 데이터베이스를 쪼갠다는 뜻입니다. 대부분의 팀이 바로 이 지점에서 고전합니다.
경계를 넘어서는 데이터는 비정규화하세요. 만약 payment-processing에서 사용자 이메일 주소가 필요하다면, DB 조인을 하는 대신 결제 서비스 쪽에 데이터를 복제해 두세요.
// 변경 전: 단일 DB 조인 사용
SELECT p.*, u.email
FROM payments p
JOIN users u ON p.user_id = u.id
// 변경 후: 결제 서비스에 비정규화(이메일 필드 추가)
SELECT p.*, p.user_email // 이메일이 payments 테이블로 복사됨
FROM payments p
외래 키를 서비스 호출로 대체하세요. 참조 무결성 체크가 DB 제약조건에서 애플리케이션 로직으로 이동합니다.
// 변경 전: DB가 사용자 존재 여부 강제
CREATE TABLE payments (
user_id INT REFERENCES users(id)
);
// 변경 후: 애플리케이션이 서비스 호출로 검증
@Transactional
async function createPayment(userId, amount) {
const user = await userServiceClient.getById(userId);
if (!user) throw new Error('User not found');
return db.payments.insert({ userId, amount });
}
제안 5: CQRS 패턴
CQRS(Command Query Responsibility Segregation)는 쓰기 모델과 읽기 모델을 분리하는 패턴입니다. 쓰기 작업은 비즈니스 규칙이 담긴 도메인 객체를 사용하고, 읽기 작업은 조회에 최적화된 전용 DTO를 사용하는 식이죠.
복잡한 조회 요구사항 때문에 도메인 객체가 뷰 전용 필드로 오염되는 경우가 많습니다. 예를 들어 사용자 목록에 “총 구매 금액"을 보여주기 위해 User 엔티티에 totalPurchase 속성을 추가하는 식인데, 이건 DDD 원칙을 무너뜨리는 지름길입니다.
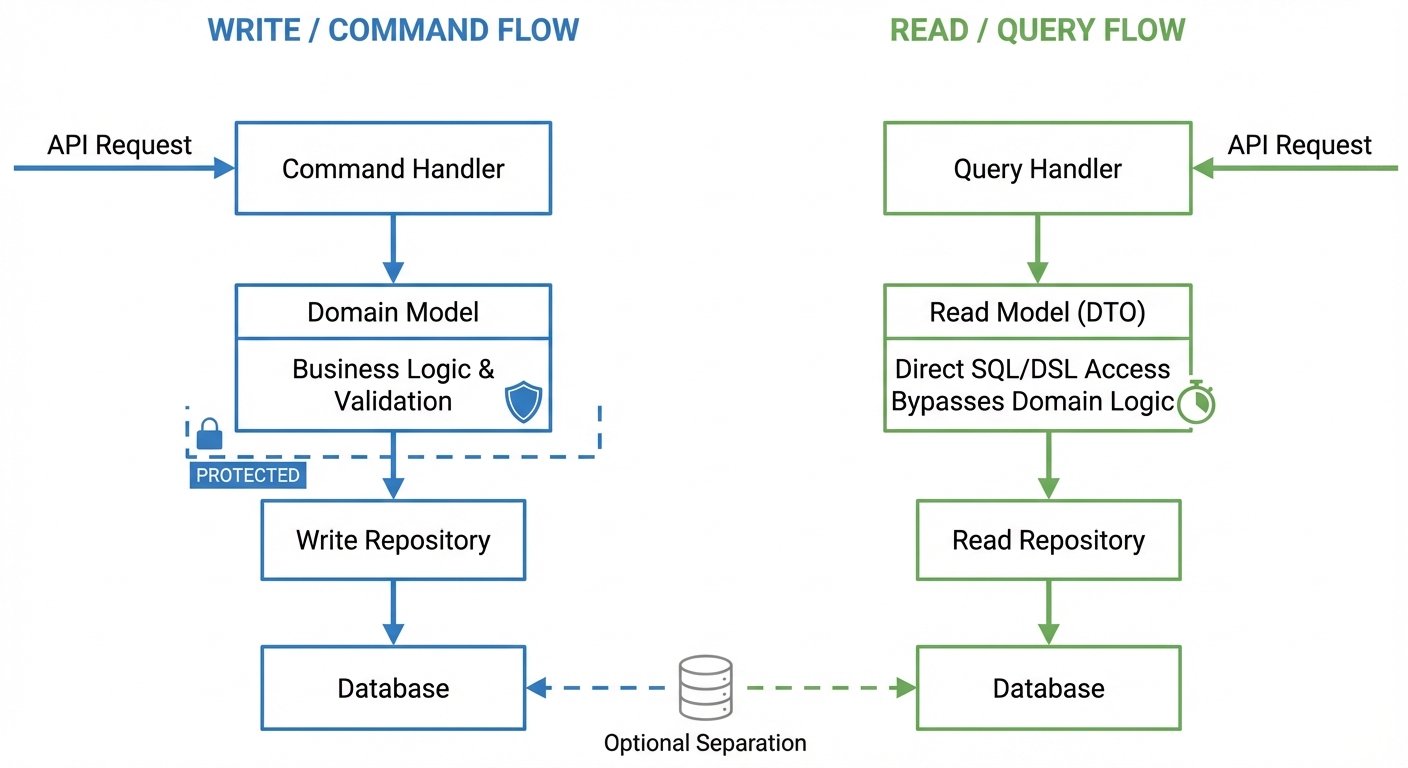
도메인 객체 보호하기
// ❌ 뷰 관련 관심사로 오염된 도메인 객체
class User {
id: string;
email: string;
// 도메인 모델에 있어서는 안 될 필드들
totalPurchaseAmount?: number; // 관리자 대시보드용
lastLoginDate?: Date; // 분석용
orderCount?: number; // 리포트용
}
// ✅ 깔끔한 도메인 객체
class User {
id: string;
email: string;
changeEmail(newEmail: string) {
// 이메일 변경을 위한 비즈니스 로직
}
}
// ✅ 뷰를 위한 별도의 읽기 모델
interface UserDashboardView {
userId: string;
email: string;
totalPurchaseAmount: number;
lastLoginDate: Date;
orderCount: number;
}
프롬프트 작성이나 코드 리뷰 시 이 원칙을 확실히 하세요. 쓰기에는 도메인 객체를, 읽기에는 DTO를 사용하는 겁니다.
복잡한 쿼리에는 DSL/SQL 사용하기
정산이나 리포팅 같은 복잡한 도메인에서는 여러 테이블을 조인하고 집계해야 합니다. 이걸 억지로 도메인 객체로 처리하려 하지 말고, 순수 데이터 조회를 위해 직접 쿼리를 날리는 게 낫습니다.
// ✅ 복잡한 뷰를 위한 직접 쿼리
class SettlementQueryRepository {
async getMonthlySettlement(merchantId: string, year: number, month: number) {
return this.db.query(`
SELECT
m.merchant_id,
m.merchant_name,
COUNT(o.order_id) as order_count,
SUM(o.amount) as total_amount,
SUM(o.fee) as total_fee,
SUM(o.amount - o.fee) as net_amount
FROM merchants m
JOIN orders o ON m.merchant_id = o.merchant_id
WHERE m.merchant_id = $1
AND EXTRACT(YEAR FROM o.created_at) = $2
AND EXTRACT(MONTH FROM o.created_at) = $3
GROUP BY m.merchant_id, m.merchant_name
`, [merchantId, year, month]);
}
}
이런 쿼리에는 Raw SQL을 쓸 수도 있지만, Kysely 같은 타입 안전 쿼리 빌더를 사용할 수도 있습니다.
// ✅ Kysely를 활용한 타입 안전한 대안
async getMonthlySettlement(merchantId: string, year: number, month: number) {
return this.db
.selectFrom('merchants as m')
.innerJoin('orders as o', 'm.merchant_id', 'o.merchant_id')
.select([
'm.merchant_id',
'm.merchant_name',
(eb) => eb.fn.count('o.order_id').as('order_count'),
(eb) => eb.fn.sum('o.amount').as('total_amount'),
(eb) => eb.fn.sum('o.fee').as('total_fee'),
])
.where('m.merchant_id', '=', merchantId)
.where(sql`EXTRACT(YEAR FROM o.created_at)`, '=', year)
.where(sql`EXTRACT(MONTH FROM o.created_at)`, '=', month)
.groupBy(['m.merchant_id', 'm.merchant_name'])
.execute();
}
쿼리 빌더를 쓰면 컴파일 타임에 타입을 체크할 수 있고 동적 쿼리 구성(문자열 연결 없이 조건부 필터 추가 등)이 쉬워집니다. Raw SQL은 더 직관적이지만 타입 안전성을 잃게 되죠. 팀의 우선순위에 맞춰 선택하면 됩니다.
성능의 핵심: 쿼리 패턴에 맞는 인덱스를 추가해야 합니다. 정산 쿼리의 경우 인덱스 컬럼 순서가 중요합니다. 특정 가맹점을 먼저 필터링한다면 (merchant_id, created_at) 순서가 맞고, 전체 가맹점을 대상으로 기간 조회를 한다면 (created_at, merchant_id)가 필요하겠죠. 반드시 EXPLAIN ANALYZE로 실행 계획을 까보고 쿼리 패턴을 점검하세요.
저장소 수준의 분리
트래픽이 많은 시스템이라면 쓰기용 DB와 읽기용 DB를 물리적으로 분리하는 방법도 있습니다.
// 쓰기: 정규화된 테이블, 트랜잭션 처리
class OrderCommandRepository {
constructor(private writeDb: Database) {}
async createOrder(order: Order) {
await this.writeDb.transaction(async (tx) => {
await tx.insert('orders', order);
await tx.insert('order_items', order.items);
});
}
}
// 읽기: 역정규화된 뷰, 조회 최적화
class OrderQueryRepository {
constructor(private readDb: Database) {}
async getOrderListView(filters: OrderFilters) {
// Materialized View 조회
return this.readDb.query('order_list_view', filters);
}
}
쓰기 DB에서 읽기 DB로 데이터를 흘려보내는 방법은 다음과 같습니다:
- CDC (Change Data Capture): 1초 미만의 지연 시간을 보장합니다. 데이터베이스별 도구가 필요합니다(PostgreSQL용 Debezium, DynamoDB Streams 등). 운영 복잡도는 올라가지만 거의 실시간 동기화가 가능하죠.
- 이벤트 스트림: 감사 로그(audit log)를 구축하고 다양한 읽기 전용 뷰를 만들 수 있습니다. 인프라(Kafka/RabbitMQ)와 애플리케이션 레벨의 발행 로직이 추가로 필요합니다.
- 폴링(Polling): 가장 단순한 방법입니다. 5~30초마다 쓰기 DB를 찔러봐서 변경 사항을 가져옵니다. 변경이 없을 때도 자원을 낭비하지만 특별한 인프라가 필요 없다는 게 장점입니다.
PostgreSQL의 Materialized View를 쓴다면 갱신 전략이 중요합니다. 그냥 REFRESH MATERIALIZED VIEW를 돌리면 갱신 중에 뷰가 락에 걸려 조회가 먹통이 됩니다. 운영 환경에선 절대 금물이죠. REFRESH MATERIALIZED VIEW CONCURRENTLY를 써야 합니다. 유니크 인덱스가 필요하고 시간은 좀 더 걸리지만, 읽기 작업을 방해하지 않습니다. 매번 쓸 때마다 트리거로 갱신하면 쓰기 부하가 심해지니, 대부분의 경우 스케줄링된 갱신(5~15분마다 크론잡으로 CONCURRENTLY 실행)을 권장합니다.
다음과 같은 경우에 저장소 분리를 고려하세요:
- 읽기 쿼리 때문에 쓰기 지연 시간이 눈에 띄게 늘어날 때
- 읽기와 쓰기 DB의 스케일링 전략이 다를 때 (쓰기는 트랜잭션을 위해 스케일업, 읽기는 부하 분산을 위해 스케일아웃이 필요할 때)
- 조회 복잡도가 너무 높아서 정규화된 쓰기 모델과 충돌하는 역정규화 스키마가 필요할 때
결과적 일관성(Eventual Consistency)의 트레이드오프
저장소를 분리하면 읽기 데이터가 최신이 아닐 수 있음을 받아들어야 합니다. 읽기 DB는 동기화 주기에 따라 몇 초에서 몇 분 전의 쓰기 DB 상태를 보여주니까요.
정산 리포트처럼 어제 마감된 데이터를 보여주는 건 괜찮습니다. 하지만 실시간 재고 확인이나 이상 거래 탐지(Fraud Detection)에서 낡은 데이터를 쓰면 비즈니스 사고가 터집니다. 강한 일관성이 필요한 곳에는 저장소 분리를 적용하지 마세요.
읽기 최적화와 일관성 보장이 둘 다 필요하다면, DB를 분리하지 말고 Read Replica를 활용하세요. 물론 동기식 복제를 하더라도(이건 내구성을 위한 거지 일관성을 위한 게 아닙니다) 레플리카엔 지연이 생길 수 있습니다. 정말 최신 데이터가 필요한 중요한 조회라면 쓰기 DB를 직접 찔러야 합니다.
async getOrderStatus(orderId: string, requiresFreshData: boolean) {
if (requiresFreshData) {
return this.writeDb.query('SELECT * FROM orders WHERE id = $1', [orderId]);
}
return this.readDb.query('SELECT * FROM order_list_view WHERE id = $1', [orderId]);
}
이렇게 하면 캐싱 효과는 못 보지만, critical path에서의 일관성 문제는 확실히 해결됩니다.
CQRS를 쓰지 말아야 할 때
단순한 CRUD 작업에는 CQRS를 쓰지 마세요. 읽기 모델과 쓰기 모델이 똑같다면—예를 들어 편집하는 필드 그대로 보여주는 기본 사용자 프로필—분리해봤자 이득 없이 보일러플레이트 코드만 늘어납니다.
일단 공유 모델로 시작하세요. CQRS로 쪼개는 건 후의 일입니다:
- 테이블 간 조인이 너무 복잡해질 때
- 도메인 객체에는 없는 필드가 읽기 모델에 필요할 때
- 성능 모니터링 결과, 읽기 쿼리가 쓰기 작업에 악영향을 주는 게 보일 때
섣부른 CQRS 도입은 불필요한 추상화만 낳습니다. 뷰의 요구사항이 분리를 필요로 할 때, 그때 적용해도 늦지 않습니다.
제안 6: 타입 안전성
동적 타입 언어에서 AI가 코드를 생성할 때, 실제 객체에는 user.emailAddress만 있는데 user.email을 참조하는 실수를 종종 저지릅니다. JavaScript나 일반적인 Python에서는 이 코드가 런타임에 가서야 터집니다. 하지만 TypeScript나 Python의 타입 힌트를 사용하면 IDE가 즉시 잡아낼 수 있습니다.
타입이 없는 경우 (JavaScript):
function sendNotification(user, message) {
// AI가 이렇게 생성할 수 있지만, user.email은 존재하지 않습니다
sendEmail(user.email, message);
logActivity(user.id, 'notification_sent');
}
타입이 있는 경우 (TypeScript):
interface User {
userId: string;
emailAddress: string;
displayName: string;
}
function sendNotification(user: User, message: string): void {
// IDE가 즉시 경고: 'email' 속성이 'User' 타입에 없습니다
sendEmail(user.email, message); // ❌ 컴파일 에러
// AI는 올바른 속성을 사용해야 합니다
sendEmail(user.emailAddress, message); // ✅ 정상
logActivity(user.userId, 'notification_sent');
}
타입은 잘못된 객체 참조, 없는 속성 접근, 틀린 함수 시그니처 같은 오류 전체를 런타임 이전에 제거해 줍니다. 타입 시스템이 컴파일을 거부하면, AI가 존재하지 않는 메서드를 만들어내는 ‘환각’도 원천 차단되는 셈입니다.
타입이 AI의 출력을 제약하는 방식
복잡한 데이터 변환이나 매핑 로직을 짤 때, AI는 종종 중첩된 속성에 잘못 접근하거나 인자 순서를 엉뚱하게 넣곤 합니다.
mypy를 돌리거나 타입 체크가 되는 IDE를 사용하면 코드가 실행되기도 전에 이런 문제를 잡을 수 있습니다. 컴파일 타임의 피드백 루프는 ‘테스트-수정’ 사이클보다 훨씬 빠릅니다.
- 즉각적인 피드백: CI/CD 파이프라인이 터지기 전에 IDE에서 빨간 밑줄로 바로 확인 가능합니다.
- 더 나은 자동완성: 타입 정보 덕분에 AI가 이후 코드의 문맥을 더 정확하게 파악합니다.
- 반복 작업 감소: 기초적인 실수를 고치기 위해 프롬프트로 ‘티키타카’ 하는 횟수가 줄어듭니다.
TypeScript 프로젝트라면 strict 모드를 켜고, husky와 biome을 사용하는 걸 추천합니다.
AI를 위한 효과적인 타입 패턴
TypeScript와 Python의 타입 힌트는 실용적인 타협점을 제공합니다. Java처럼 코드가 지나치게 장황해지지 않으면서도 필요한 곳에 확실한 타입 안전성을 챙길 수 있죠.
모든 외부 데이터에 인터페이스 정의하기
API, 데이터베이스, 혹은 사용자 입력 등 외부에서 들어오는 데이터는 반드시 명시적인 타입이 있어야 합니다.
// API 응답
interface ApiResponse<T> {
data: T;
status: number;
error?: string;
}
interface ProductData {
id: string;
name: string;
price: number;
inStock: boolean;
}
async function fetchProduct(productId: string): Promise<ApiResponse<ProductData>> {
// AI는 어떤 구조를 기대하고 리턴해야 하는지 정확히 알게 됩니다
const response = await api.get(`/products/${productId}`);
return response.data;
}
상태 관리에는 식별된 유니언(Discriminated Unions) 사용하기
이 패턴은 AI가 특정 상태에 존재하지 않는 속성에 접근하는 것을 막아줍니다. 흔한 AI 실수가 바로 status가 success인지 확인도 안 하고 state.data에 접근하려 드는 것입니다.
type RequestState =
| { status: 'idle' }
| { status: 'loading' }
| { status: 'success'; data: ProductData }
| { status: 'error'; error: string };
function handleRequest(state: RequestState): void {
// AI가 자주 만드는 실수 - 상태 확인 없이 데이터 접근
displayProduct(state.data); // ❌ 'data' 속성이 모든 유니언 타입에 존재하지 않음
// 식별된 유니언은 적절한 검사를 강제함
if (state.status === 'success') {
displayProduct(state.data); // ✅ 타입 좁히기(Narrowing)로 데이터 존재 보장
} else if (state.status === 'error') {
showError(state.error); // ✅ 타입 좁히기로 에러 존재 보장
}
}
타입 시스템이 없다면 AI는 첫 번째 버전처럼 코드를 짤 겁니다. 컴파일은 되겠지만, 런타임에 state가 loading이나 error일 때 여지없이 뻗어버리겠죠.
재사용 컴포넌트에는 제네릭(Generics) 활용하기
제네릭은 작업 전반에 걸쳐 타입 일관성을 유지해 줍니다.
from typing import TypeVar, Generic, List, Optional
T = TypeVar('T')
class Repository(Generic[T]):
def __init__(self, items: List[T]):
self._items = items
def find_by_id(self, item_id: str, get_id: callable) -> Optional[T]:
for item in self._items:
if get_id(item) == item_id:
return item
return None
def find_all(self) -> List[T]:
return self._items.copy()
# 사용 예시
user_repo = Repository[User]([user1, user2])
user = user_repo.find_by_id("123", lambda u: u.id) # 타입 체커는 이것이 Optional[User]임을 인지함
제네릭 T는 타입 일관성을 보장합니다. 리포지토리를 어떤 타입으로 인스턴스화하든 그 타입이 모든 메서드에 흐르게 되죠. AI가 실수로 타입을 섞거나 엉뚱한 구조를 리턴할 틈을 주지 않습니다.
명세서로서의 타입 정의
잘 정의된 타입은 AI에게 훌륭한 가이드가 됩니다. AI에게 “사용자 설정을 업데이트하는 메서드를 추가해줘"라고 요청했을 때, AI가 UserPreferences 타입을 볼 수 있다면 어떤 필드가 가용한지 정확히 알 수 있습니다.
interface UserPreferences {
theme: 'light' | 'dark';
notifications: {
email: boolean;
push: boolean;
sms: boolean;
};
language: string;
}
class UserService {
// AI는 타입 구조를 보고 정확한 코드를 생성할 수 있습니다
updatePreferences(userId: string, preferences: Partial<UserPreferences>): void {
// 타입 시스템은 유효한 필드만 접근하도록 보장합니다
if (preferences.theme) {
this.validateTheme(preferences.theme); // AI는 theme이 'light' 혹은 'dark'임을 알고 있습니다
}
if (preferences.notifications?.email !== undefined) {
this.updateEmailNotifications(userId, preferences.notifications.email);
}
}
}
이런 타입 정의가 없다면, AI는 preferences.colorScheme나 preferences.emailNotifications 같이 그럴싸하지만 실제로는 틀린 코드를 생성할 수 있습니다.
타입 안전성의 한계
타입은 구조적인 오류는 잘 잡지만, 모든 문제를 해결해 주진 못합니다.
같은 타입의 매개변수 순서 변경 (Parameter Swapping): 두 매개변수의 타입이 같다면, AI가 순서를 바꿔 넣어도 타입 체커는 모릅니다.
function sendEmail(subject: string, body: string): void { ... }
// 둘 다 문자열이라 타입 체커는 통과시킴
sendEmail(emailBody, emailSubject); // ✅ 타입은 맞음, ❌ 의미상 틀림
정말 중요한 로직이라면, 래퍼 타입을 써서 타입 레벨에서 구분을 강제하세요.
class EmailSubject {
constructor(public readonly value: string) {}
}
class EmailBody {
constructor(public readonly value: string) {}
}
function sendEmail(subject: EmailSubject, body: EmailBody): void {
// 구현부에서는 subject.value와 body.value를 사용
}
// 사용 예시
sendEmail(new EmailSubject("Hello"), new EmailBody("Message text"));
sendEmail(new EmailBody("Message text"), new EmailSubject("Hello")); // ❌ 타입 에러
비즈니스 로직 오류: 타입은 AI가 알고리즘적으로는 맞지만 비즈니스 요구사항과는 다른 코드를 짜는 것까진 못 막습니다. “100달러 이상 품목에 할인 적용"이 요구사항인데 AI가 “50달러 이상"으로 짰다면, 타입은 만족하지만 로직은 틀린 거죠.
지나치게 복잡한 타입: 제네릭을 너무 깊게 중첩하거나, 복잡한 조건부 타입, 난해한 타입 변환을 쓰면 AI가 헷갈려 하거나 생성된 코드를 사람이 이해하기 어려워집니다. 타입을 이해하기 위해 코드를 여러 번 다시 읽어야 한다면, AI와 유지보수 담당자를 위해 단순화하는 게 좋습니다.
타입은 구조를 제약하고 인터페이스 불일치를 잡아줄 뿐, 코드 리뷰나 테스트, 도메인 지식을 대체할 수는 없습니다.
실전 적용 가이드
가장 가치가 높은 영역부터 시작하세요.
- API 경계: 모든 엔드포인트의 요청/응답 타입
- 데이터베이스 모델: 스키마와 일치하는 엔티티 타입
- 비즈니스 로직 함수: 핵심 연산의 입력/출력 타입
- 상태 관리: 타입 안전성이 보장된 리듀서와 액션
첫날부터 100% 타입 커버리지를 고집할 필요는 없습니다. 컴포넌트 간의 인터페이스, 즉 AI가 제멋대로 가정하기 딱 좋은 지점들에 집중하세요.
타입 힌트와 런타임 검증을 조합해 보세요. Python의 pydantic이나 TypeScript의 zod 같은 라이브러리가 유용합니다.
from pydantic import BaseModel, validator
from typing import List
class OrderItem(BaseModel):
product_id: str
quantity: int
price: float
class OrderRequest(BaseModel):
items: List[OrderItem]
customer_id: str
shipping_address: str
@validator('items')
def items_not_empty(cls, v):
if not v:
raise ValueError('Order must contain at least one item')
return v
# AI가 생성하는 부분, 타입이 정확성을 보장함
def create_order(request_data: dict) -> Order:
# Pydantic은 런타임에 검증하고, 타입은 생성 시점에 AI를 가이드함
validated_request = OrderRequest(**request_data)
return Order(
order_id=generate_id(),
items=validated_request.items,
customer_id=validated_request.customer_id
)
정적 타입은 코드 생성 시점과 IDE에서 오류를 잡습니다. 런타임 검증은 API 요청, 파일 업로드, 사용자 입력 등 외부 소스의 데이터 오염을 막아줍니다. 둘 다 쓰세요. 타입은 개발 중에 AI를 가이드하고, 검증은 운영 환경의 시스템을 보호합니다.
구조적 오류를 막는 것도 중요하지만, AI가 짠 코드와 사람이 짠 코드의 스타일을 일관되게 유지하는 것 또한 장기적인 유지보수를 위해 필수적입니다. 바로 여기서 자동화된 린팅과 포맷팅이 등장합니다.
제안 7: 린팅과 포맷팅 자동화
코드 스타일이 들쑥날쑥하면 코드 리뷰할 때 불필요한 ‘노이즈’만 생깁니다. AI가 생성한 코드는 기존에 학습한 패턴을 그대로 모방하는 경향이 있거든요. 그러니 스타일은 도구를 써서 기계적으로 강제해야 합니다. 포맷팅 맞추느라 아까운 리뷰 시간이나 AI 토큰을 낭비하지 마세요.
Linter로 AI 코드 걸러내기
AI가 짠 코드도 자동화된 스타일 검사가 필수입니다. 리뷰 요청 전에 린터부터 한번 돌려보세요.
# AI로 코드를 생성한 뒤, 즉시 검사 수행
$ biome check --write ./src # JavaScript/TypeScript
$ ruff check --fix . # Python
이 명령어 한 번이면 다음 문제들을 즉시 잡아냅니다.
- 사용하지 않는 import 구문
- 들쑥날쑥한 들여쓰기와 공백
- 빠진 세미콜론
- 라인 길이 제한 위반
- 줄 끝에 남은 불필요한 공백
언어별 추천 도구
JavaScript/TypeScript: Biome
Biome은 린팅과 포맷팅 기능을 하나로 합친 도구인데, ESLint와 Prettier 조합보다 성능이 압도적으로 좋습니다. 설정 파일 하나면 되고, 의존성도 없습니다.
{
"linter": {
"enabled": true,
"rules": {
"recommended": true
}
},
"formatter": {
"enabled": true,
"indentStyle": "space",
"indentWidth": 2
}
}
Python: Ruff
Ruff는 Flake8, Black, isort 같은 여러 도구를 Rust로 작성된 단 하나의 바이너리로 대체해 버립니다. 규칙 카테고리 설정도 간단합니다. E/W는 pycodestyle, F는 pyflakes, I는 import 정렬, N은 네이밍 규칙을 담당하죠.
[tool.ruff]
line-length = 100
select = ["E", "F", "I", "N", "W"]
fix = true
Pre-Commit 자동화
#!/bin/sh
# .husky/pre-commit
npm run lint --fix || {
echo "Linting failed. Fix errors before committing."
exit 1
}
포맷팅에 AI 토큰을 태우지 마세요
AI에게 코드 정렬을 시키느니 린터를 돌리는 게 훨씬 빠르고 저렴하며 확실합니다. 만약 AI가 계속 스타일 가이드를 어기는 코드를 짠다면, 시스템 프롬프트를 수정해서 해결해야지 AI를 포맷터 대용으로 쓰려고 하면 안 됩니다.
자동화 전략
린팅은 여러 단계에서 수행해야 합니다.
- Pre-commit: Git 훅을 걸어 포맷팅이 엉망인 커밋을 원천 차단합니다. 엉터리 코드가 저장소에 들어오는 걸 입구 컷 하는 거죠.
- CI/CD: 린팅 에러가 하나라도 있으면 빌드를 실패 처리합니다. 팀 전체가 규칙을 지킬 수밖에 없게 만드는 겁니다.
린팅으로 스타일 일관성을 잡았다면, 이제 기능이 제대로 동작하는지가 중요해집니다. AI가 코드를 빠르게 찍어낼 수는 있지만, 제대로 된 테스트 없이는 검증되지 않은 로직을 대량으로 배포하는 시한폭탄을 안고 가는 셈이니까요.
제안 8: 테스트 전략
AI는 200줄짜리 CRUD 서비스를 불과 30초 만에 만들어냅니다. 반면, 사람이 이걸 꼼꼼하게 리뷰하려면 20분은 족히 걸리죠. 수동 코드 리뷰만으로는 이 속도를 감당할 수 없습니다. 자동화된 검증이 필수라는 얘기입니다.
CI/CD에서 테스트 강제하기
AI가 새로운 API 엔드포인트나 데이터베이스 쿼리를 작성했다면, 머지하기 전에 반드시 테스트 코드를 포함하도록 하세요. 이걸 CI/CD 파이프라인에서 강제하는 겁니다. 만약 핵심 경로(critical path)의 브랜치 커버리지가 설정한 기준치 밑으로 떨어지면 빌드가 실패하도록 설정하세요.
이때 단순히 ‘라인 커버리지’만 지표로 삼으면 안 됩니다. 코드를 실행만 하고 실제로는 아무것도 검증하지 않는 껍데기 테스트로 점수를 조작하기 쉽거든요. 버그가 터졌을 때 실제로 문제가 되는 경로들에 대한 ‘브랜치 커버리지’에 집중해야 합니다.
테스트 코드는 “이 코드가 무슨 일을 해야 하는가"를 정의하는 계약서 역할을 합니다. AI가 생성한 코드가 100% 이해되지 않을 때, 테스트 코드가 우리가 무엇을 기대해야 하는지 명확히 알려주는 셈이죠.
테스트 코드 먼저 리뷰하기
구현 코드보다는 테스트 코드 리뷰에 에너지를 쏟으세요.
테스트가 무엇을 검증하고 있는지 다음 사항들을 체크해 보세요:
- 엣지 케이스는 커버하고 있는가?
- 단언문이 실제 비즈니스 요구사항과 일치하는가?
- DB 연동에 대한 통합 테스트는 있는가?
- 에러 상황도 테스트하고 있는가?
AI가 작성한 테스트에는 치명적인 함정이 있습니다. AI는 요구사항이 아니라, 자기가 짠 코드가 ‘어떻게 동작할 것 같다’고 생각하는 대로 테스트를 작성합니다. 즉, 우리가 원하지 않는 동작인데도 테스트는 초록불이 뜨게 만들 수 있다는 거죠.
리뷰할 때 반드시 잡아야 할 예시를 보여드리겠습니다:
# AI가 생성한 테스트 - 멀쩡해 보이지만 '잘못된' 동작을 테스트함
def test_create_order():
product = create_product(stock=5)
order = order_service.create_order(product_id=product.id, quantity=3)
assert order.id is not None
assert order.quantity == 3
# AI가 재고 감소 확인을 빼먹음!
# 버그: 주문이 생성되어도 재고가 그대로임
실제로 필요한 테스트는 이렇습니다:
def test_create_order_decrements_inventory():
product = create_product(stock=5)
order = order_service.create_order(product_id=product.id, quantity=3)
assert order.id is not None
assert order.quantity == 3
assert product.stock == 2 # AI가 놓친 결정적인 검증 로직
Playwright를 활용한 E2E 테스팅
원래 E2E 테스트는 유지보수하기 정말 까다롭죠. 하지만 AI 에이전트를 활용하면 수동 스크립팅에서 의도 기반 테스팅으로 판을 뒤집을 수 있습니다.
- AI 기반 생성: “로그인부터 결제까지의 핵심 경로"처럼 자연어로 사용자 여정을 설명하면, AI가 Playwright 스크립트와 POM(Page Object Model)을 알아서 잡아줍니다.
- 자가 치유(Self-Healing) 및 디버깅: 테스트가 실패하면 에러 로그나 Trace Viewer 데이터를 AI에게 던져주세요. 단순한 셀렉터 변경인지 레이스 컨디션인지 AI가 기가 막히게 구분해서 “자가 치유” 패치를 내놓습니다.
- 아키텍처 정렬: AI에게 경계를 확실히 하도록 시키세요. “DB 쿼리를 직접 날리지 말고
UserServiceAPI를 통해 테스트 데이터를 셋업해"라고 지시해서, 테스트가 내부 스키마에 종속되지 않도록 막아야 합니다. - 엣지 케이스 발견: 우리가 미처 생각지 못한 실패 지점을 AI에게 브레인스토밍하게 시키세요. 네트워크 지연이나 불완전한 입력 같은 상황을 찾아내서 해피 패스 바깥의 영역까지 빠르게 커버리지를 넓힐 수 있습니다.
개발 워크플로우
다음과 같이 워크플로우를 설정하세요:
- AI가 구현 코드와 테스트를 함께 생성
- 개발자는 테스트 코드의 완전성과 정확성을 집중적으로 리뷰
- CI가 전체 테스트 스위트를 자동으로 실행
- 테스트 통과 및 필수 커버리지 충족 없이는 머지 불가
이렇게 하면 리뷰의 초점이 사람이 진짜 가치를 더할 수 있는 곳으로 이동합니다. 생성된 코드에서 오타나 찾고 있는 게 아니라, 요구사항을 제대로 이해했는지, 동작이 올바른지 테스트를 통해 검증하는 데 집중하게 되는 거죠.