PostgreSQL 통계의 사각지대를 드러낸 고객 클레임
모든 일은 고객의 클레임 한 건에서 시작되었습니다. 워크플로우의 핵심 부분이 응답하지 않는다는 내용이었죠. 로그를 까보니 병목 구간은 평소라면 아무 문제 없었을 평범한 쿼리였는데, 이 녀석이 갑자기 타임아웃을 내고 있었습니다. 원인을 파악하기 위해 우리는 PostgreSQL 쿼리 플래너(Query Planner)의 내부를 깊숙이 파고들어야 했습니다. 그리고 그곳에서 특정 데이터 분포 패턴이 통계 추정(statistics estimation)의 희귀한 버그를 건드리고 있다는 사실을 발견했습니다.
이 글은 그 해결 과정을 기록한 문서입니다. 내용이 다소 긴 이유는 버그 자체가 미묘하기도 하거니와, 왜 이런 일이 발생하는지 이해하려면 PostgreSQL 옵티마이저가 의사결정을 내리는 과정을 따라가 봐야 하기 때문입니다. 이유 없이 쿼리 실행 계획(Query Plan)이 꼬이는 걸 본 적이 있거나, 해시 조인(Hash Join)이 분명 유리해 보이는데 왜 PostgreSQL이 굳이 중첩 루프(Nested Loop)를 선택하는지 궁금했다면, 이 글이 도움이 될 겁니다.
기술적인 내용이 많음에도 끝까지 읽어주신다면, 일반적인 튜닝 가이드나 문서에서는 찾아보기 힘든 유형의 성능 문제를 이해하는 통찰력을 얻어가실 수 있을 겁니다.
조인 쿼리가 느려졌습니다… 그런데 ‘가끔’만요
버그 리포트는 대부분의 운영 환경 미스터리가 그렇듯 갑작스럽게 날아왔습니다. 수년간 문제없이 잘 돌아가던 기능이 갑자기 타임아웃을 내기 시작한 거죠. 더 골치 아픈 건, 동일한 코드가 돌아가는 수십 개의 운영 환경 중 딱 한 곳에서만 이런 일이 발생했다는 점입니다.
아키텍처는 단순했습니다. 시스템은 작업을 여러 워커(Worker)에게 분산 처리합니다. 실행 중에 각 워커는 개별 결과를 PostgreSQL에 저장하고, 모든 워커가 작업을 마치면 집계(Aggregation) 단계에서 조인 쿼리를 실행해 최종 통계를 계산합니다.
Elastic APM과 로그를 확인해 보니 뭔가 이상한 점이 보였습니다. 대량 Insert(Bulk Insert)가 완료된 직후에 실행되는 집계 쿼리가 60초 넘게 걸리며 타임아웃을 유발하고 있었습니다. 하지만 몇 분 뒤에 똑같은 쿼리를 수동으로 다시 돌려보면 1초도 안 돼서 끝나는 것이었습니다.
쿼리 자체는 다음과 같은 구조의 표준적인 4개 테이블 조인이었습니다.
A <-> B <-> C <-> D
테이블 A는 1개 행, B는 약 1,000개, C는 1001,000개, D는 110개 행을 가지고 있었습니다. 조인 관계 때문에 집계 전 중간 결과 집합은 수백만 행으로 불어날 수 있는 구조였죠.
이론상으로는 아무 문제가 없어야 합니다. PostgreSQL의 해시 조인은 이런 규모를 효율적으로 처리하도록 설계되었으니까요. 모든 외래 키(Foreign Key)에는 인덱스도 걸려 있었습니다. 다른 환경에서도 비슷한 데이터 볼륨으로 동일한 쿼리가 문제없이 돌고 있었고요.
하지만 우리는 데이터 생성 직후에는 설명할 수 없을 만큼 느리다가, 몇 분 뒤에는 미스터리하게 빨라지는 쿼리를 마주하고 있었습니다. 그것도 딱 이 환경에서만요.
쿼리 플래너는 뭐라고 했을까?
저는 빠른 실행과 느린 실행 양쪽 모두에 대해 EXPLAIN (ANALYZE, BUFFERS)를 돌려봤습니다.
-- 쿼리 구조
SELECT *
FROM table_a a
JOIN table_b b ON a.id = b.a_id
JOIN table_c c ON b.id = c.b_id
JOIN table_d d ON c.id = d.c_id
WHERE a.job_id = $1;
실행 계획 간의 주요 차이점은 다음과 같았습니다.
빠른 실행 (Fast execution):
- 전체적으로 중첩 루프(Nested Loop) 조인 사용
- 행(Row) 추정치가 실제 값과 거의 일치 (오차 10-20% 이내)
- 총 비용(Cost) 추정: ~15,000
느린 실행 (Slow execution):
- C→D 조인 구간에서 해시 조인(Hash Join) 선택
- C→D 조인의 행 추정치: 500행
- C→D 조인의 실제 행 개수: 45,000행
- 해시 테이블이
work_mem을 초과하여 디스크 스필(Disk Spill) 발생 - 총 비용(Cost) 추정: ~12,000 (빠른 계획보다 오히려 낮음!)
플래너는 해시 조인이 더 저렴할 것이라 계산했지만, 세 번째 조인 단계에서 행 개수를 엄청나게 과소평가하는 바람에 오버사이즈된 해시 테이블을 만들었고, 결국 디스크로 넘쳐버렸습니다(Spill). 디스크 스필이 발생할 때마다 I/O 오버헤드로 인해 몇 초씩 시간이 추가되었습니다.
결정적인 증거(Smoking gun)는 pg_stat_user_tables에 있었습니다. table_c는 8일 동안이나 통계 갱신(Analyze)이 되지 않았고, 그사이 해당 job_id와 관련된 데이터는 엄청나게 불어난 상태였습니다. 플래너는 썩은 통계 정보를 바탕으로 의사결정을 내리고 있었던 겁니다.
4개 테이블 모두에 ANALYZE를 실행하자 쿼리는 즉시 안정화되었습니다. 이후 실행부터는 일관되게 중첩 루프 조인을 선택했고 200ms 이내에 완료되었습니다.
범인: 해시 조인 대신 선택된 중첩 루프
EXPLAIN ANALYZE 결과를 보면 PostgreSQL이 조인 알고리즘을 바꾸는 걸 볼 수 있습니다. 대개는 해시 조인을 선택했지만, 대량 Insert 직후에는 중첩 루프 조인으로 전환했습니다.
중첩 루프 조인은 한쪽 테이블의 각 행에 대해 다른 쪽 테이블을 반복적으로 스캔합니다. 데이터셋이 크고 조인 컬럼에 선택도(Selectivity)가 좋은 인덱스가 없다면, 이건 성능 킬러가 됩니다. 반면 해시 조인은 해시 테이블을 한 번 빌드하고 그걸 조회(Probe)하기 때문에 이런 패턴에서는 압도적으로 빠릅니다.
PostgreSQL은 조인 한쪽의 결과 행이 적을 것이라고 추정할 때 중첩 루프를 선택합니다. 대량 Insert 직후, 오래된 통계 정보 때문에 플래너가 헛다리를 짚은 거죠.
조인 알고리즘 다시 보기 (Refresher)
데이터베이스 시스템에는 크게 세 가지 조인 알고리즘이 있으며, 각각 성능 특성이 다릅니다. 잘못된 알고리즘 선택은 쿼리가 몇 밀리초 만에 끝날지, 아니면 몇 시간 동안 돌지 결정짓는 차이를 만듭니다.
중첩 루프 조인 (Nested Loop Join)
중첩 루프 조인은 가장 단순한 알고리즘입니다. 외부 테이블(드라이빙 테이블)의 각 행에 대해 내부 테이블의 모든 행을 스캔하며 조인 조건을 검사합니다.
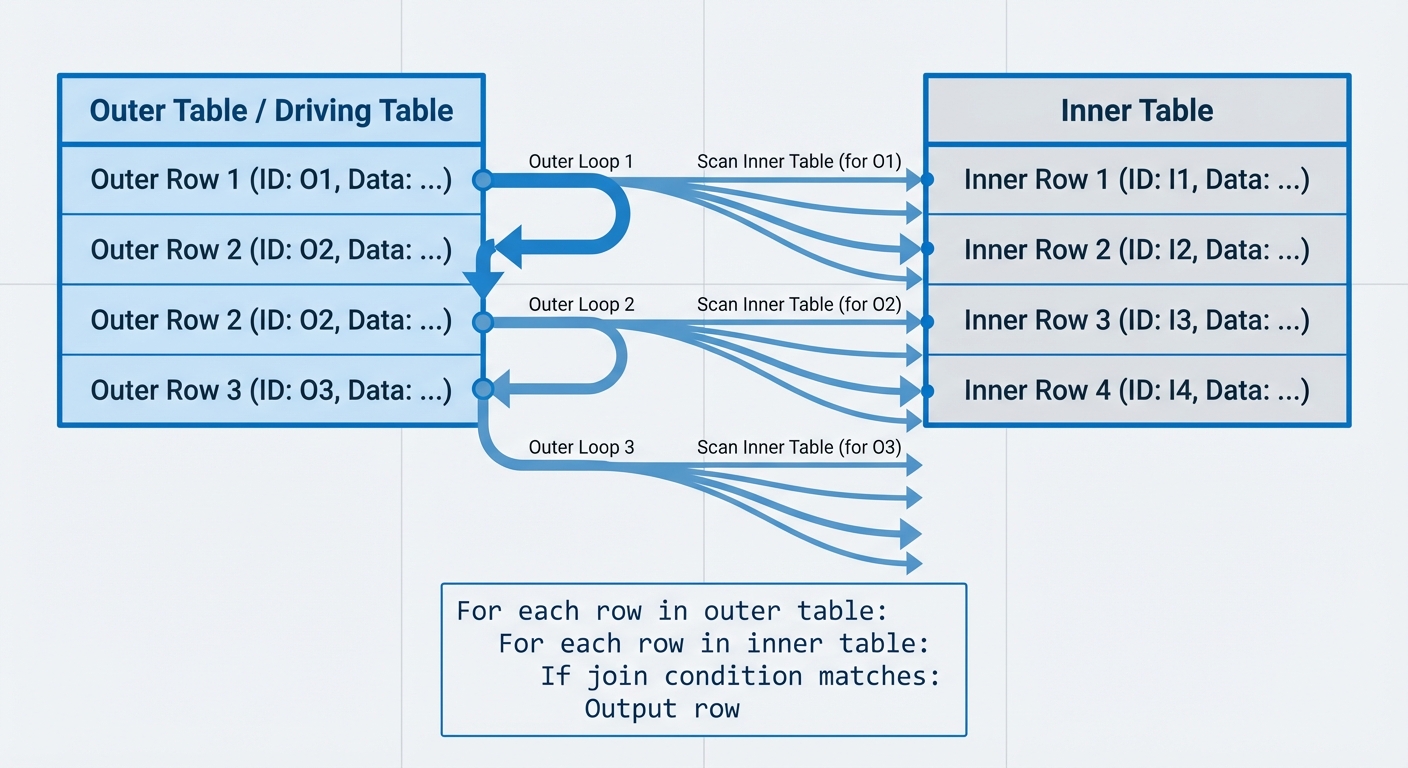
복잡도: O(n*m) (n은 외부 테이블 행 수, m은 내부 테이블 행 수)
For each row in outer table:
For each row in inner table:
If join condition matches:
Output row
드라이빙 테이블의 선택은 중요하지만, 여러분이 생각하는 그 이유는 아닐 수 있습니다. 100행을 10,000행에 대조하든, 10,000행을 100행에 대조하든 비교 횟수는 1,000,000번으로 같습니다. 진짜 이득은 내부 테이블에 인덱스가 있을 때 발생합니다. 100 × O(log 10,000) ≈ 1,300 연산 대 10,000 × O(log 100) ≈ 66,000 연산의 차이가 되니까요. 인덱스가 없다면 드라이빙 테이블 선택은 주로 캐시 지역성(Cache locality)이나 외부 테이블의 필터 조건을 얼마나 효과적으로 푸시 다운(Push down)할 수 있는지에 영향을 미칩니다.
인덱스 중첩 루프 조인 (Index Nested Loop Join)
실무에서 데이터베이스가 위에서 말한 ‘순진한(Naive)’ 중첩 루프를 쓰는 경우는 드뭅니다. 내부 테이블의 조인 키에 인덱스가 있다면 알고리즘은 인덱스 중첩 루프 조인이 됩니다.
For each row in outer table:
Use index to find matching rows in inner table (O(log m))
Output matches
복잡도: O(n × log m) (내부 테이블에 B-tree 인덱스가 있을 경우)
이 변형은 운영 쿼리에서 매우 흔하게 보입니다. 꽤 큰 테이블이라도 중첩 루프 조인이 잘 돌아가는 이유가 바로 이겁니다. 인덱스가 내부 테이블 풀 스캔(Full Scan)을 제거해주니까요.
언제 유리한가:
- 작은 외부 테이블과 인덱스된 내부 테이블을 조인할 때
- 필터 조건으로 인해 외부 테이블에서 소수의 행만 선택될 때
- 전체 비교 횟수가 감당 가능한 수준인 작은 데이터셋일 때
언제 망하는가: 내부 조인 키에 인덱스 없이 대용량 테이블을 조인할 때. 100만 × 100만 무인덱스 조인은 1조 번의 비교 연산을 의미합니다.
해시 조인 (Hash Join)
해시 조인은 입력 테이블 중 작은 쪽을 이용해 해시 테이블을 만들고(Build), 큰 쪽 테이블을 스캔하며 해시 테이블을 조회(Probe)합니다.
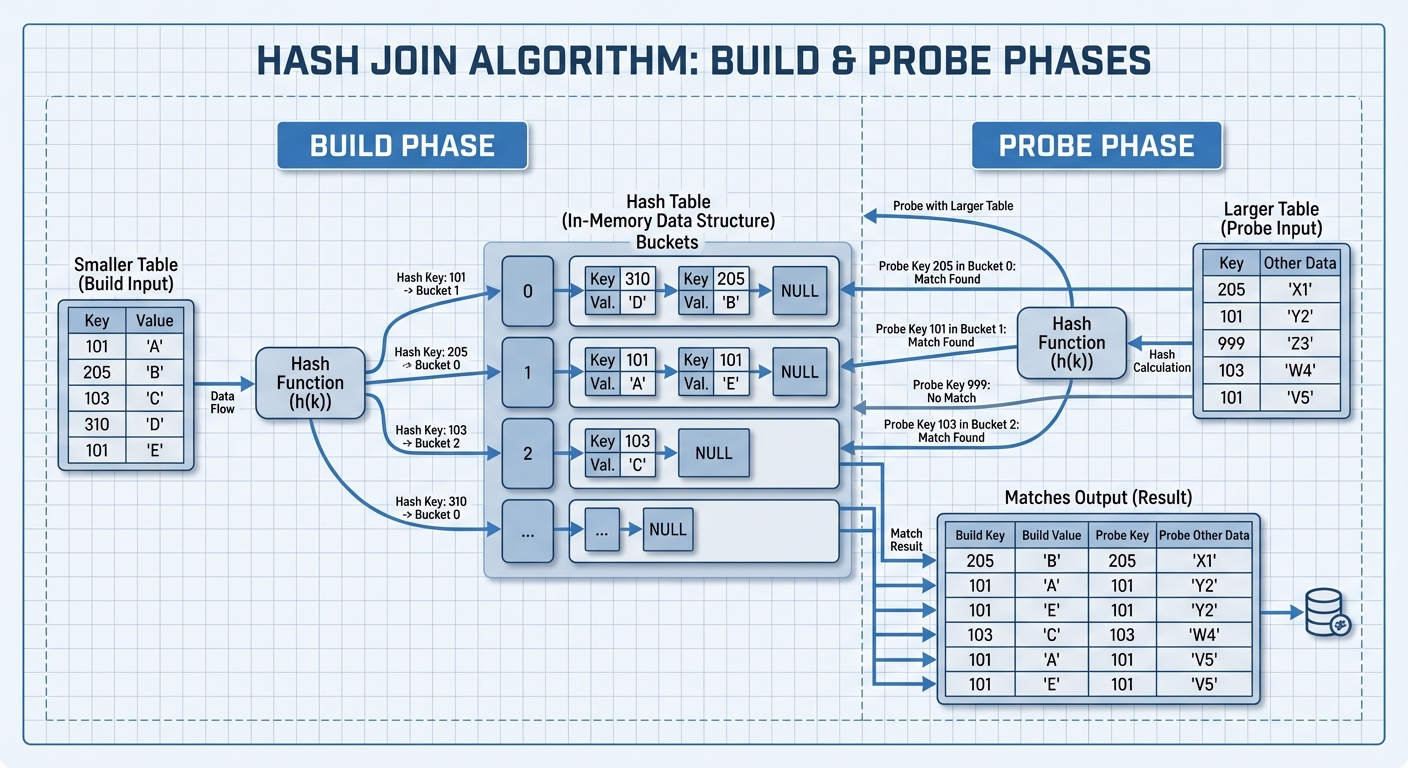
복잡도: O(n+m) - 전체 행 수에 비례(Linear).
빌드(Build) 단계:
- 작은 테이블을 스캔
- 각 행의 조인 키를 해싱
- 해시 테이블 버킷에 행 저장
조회(Probe) 단계:
- 큰 테이블을 스캔
- 각 행의 조인 키를 해싱
- 해시 테이블에서 일치하는 행 조회
- 일치하는 결과 출력
메모리와 하이브리드 해시 조인
PostgreSQL은 work_mem 파라미터로 해시 테이블 크기를 제어합니다. 해시 테이블이 메모리에 들어간다면 해시 조인은 엄청나게 빠릅니다. 하지만 빌드 입력이 work_mem을 초과하면, PostgreSQL은 배칭(Batching)을 사용하는 하이브리드 해시 조인으로 전환합니다.
- 해시 함수를 사용해 두 입력 테이블을 여러 배치로 파티셔닝
- 각 배치 쌍을 순차적으로 처리
- 각 배치의 해시 테이블은
work_mem안에 들어감
이 배칭 방식은 메모리가 제한적일 때도 예측 가능한 성능을 유지해 주지만, 데이터를 여러 번(배치당 한 번) 훑어야 하고 임시 디스크 공간이 필요합니다.
언제 유리한가:
- 대용량 동등 조인(Equi-join,
table_a.id = table_b.id같은 조건) - 해시 테이블을 위한 충분한 메모리가 있을 때
- 조인 키에 인덱스가 없을 때
한계:
- 동등 조인에서만 작동 (
<,>, 등의 비동등 조건 불가) - 배칭을 위한 충분한
work_mem이나 디스크 공간 필요 - 결과를 리턴하기 전에 빌드 단계가 반드시 완료되어야 함 (첫 행 응답 속도 느림)
머지 소트 조인 (Merge Sort Join)
머지 소트 조인은 두 입력이 조인 키를 기준으로 정렬되어 있어야 합니다. 그 후 머지 소트(Merge Sort)의 병합(Merge) 단계처럼 단일 패스로 두 입력을 합칩니다.
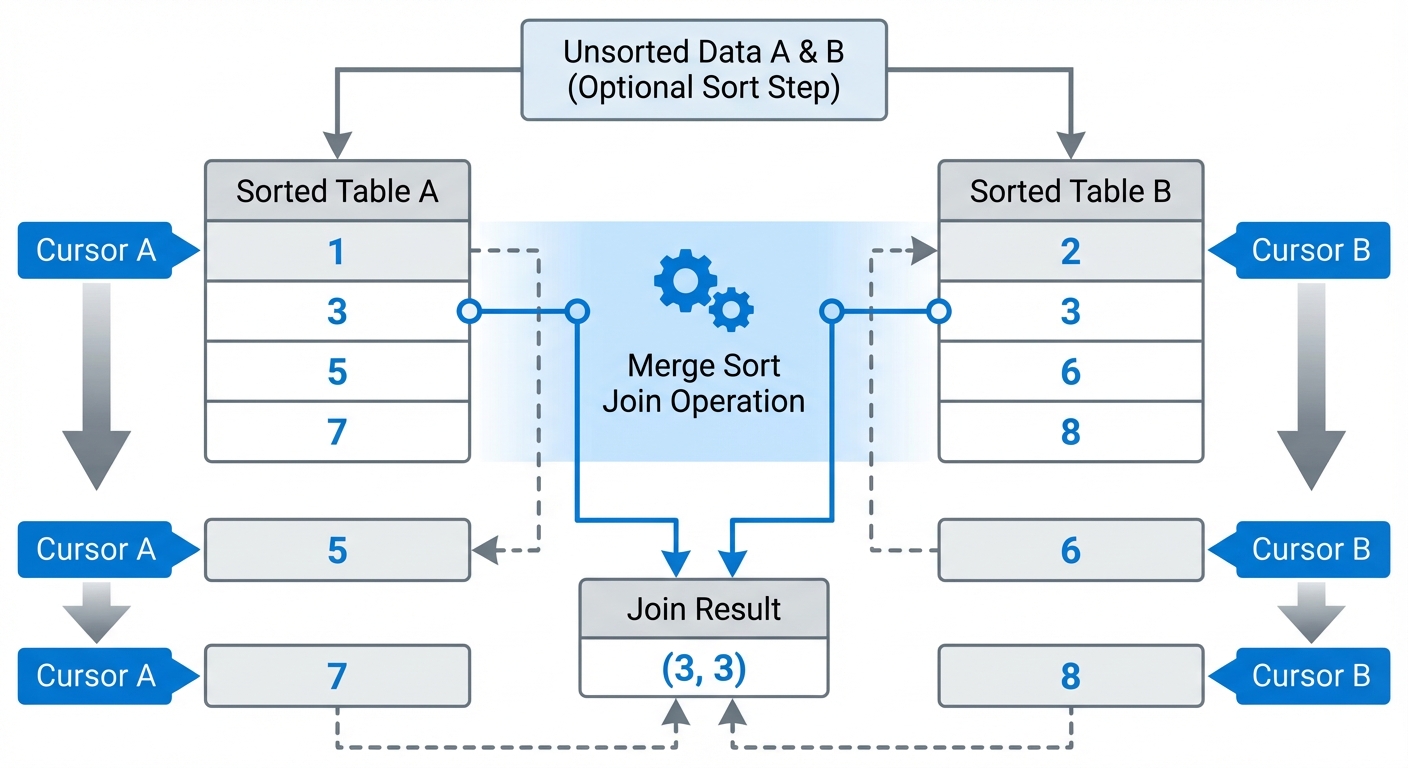
복잡도: 두 입력을 정렬하는 비용 O(n log n + m log m) + 병합 단계 O(n+m).
데이터가 이미 정렬되어 있다면(인덱스나 이전 연산 덕분에), 정렬 비용은 사라지고 O(n+m)만 남습니다.
알고리즘:
- 두 테이블을 조인 키로 정렬 (정렬 안 되어 있을 시)
- 각 정렬된 테이블에 포인터 유지
- 현재 행들을 비교
- 일치하면 출력하고 두 포인터 전진
- 일치하지 않으면 더 작은 값을 가진 쪽 포인터 전진
중복 처리
동일한 조인 키를 가진 행이 여러 개일 때(다대다 조인), 알고리즘은 일치하는 행들의 카르테시안 곱(Cartesian product)을 만들어야 합니다. 이를 위해 마크/복원(Mark/Restore) 작업이 필요합니다. 한쪽 입력에 위치를 표시(Mark)해두고, 다른 쪽의 일치하는 행들을 스캔한 뒤, 다음 매칭을 위해 마크 위치로 되돌아가는 방식입니다. 중복 그룹이 크다면 행을 메모리에 버퍼링해야 할 수도 있습니다.
언제 유리한가:
- 데이터가 이미 정렬되어 있거나 인덱스를 통해 정렬된 순서로 읽을 수 있을 때
- 어차피
ORDER BY절 때문에 정렬된 결과가 필요할 때 (비용 상각) - 부등호 연산자(<, >, <=, >=)를 사용하는 조인 조건일 때
- 해시 조인을 쓰기엔 테이블이 너무 커서 메모리가 감당 안 될 때
트레이드오프: 데이터가 미리 정렬되어 있지 않다면 정렬 비용이 비쌉니다. 하지만 ORDER BY 때문에 정렬된 결과가 필요하다면, 그 비용은 전체 쿼리 비용에 녹아듭니다.
이제 알고리즘 선택이 왜 중요한지 이해했으니, 다음 질문은 PostgreSQL이 어떤 알고리즘을 쓸지 ‘어떻게’ 결정하느냐입니다.
광기 속으로: PostgreSQL 쿼리 플래너
PostgreSQL은 쿼리를 실행하기 전에 여러 실행 전략을 평가하고 각 전략의 비용을 추정합니다. 쿼리 플래너의 임무는 가장 비용이 낮은 경로를 고르는 것입니다. 그게 시퀀셜 스캔(Sequential Scan)이든, 인덱스 스캔이든, 중첩 루프 조인이든, 해시 조인이든 말이죠.
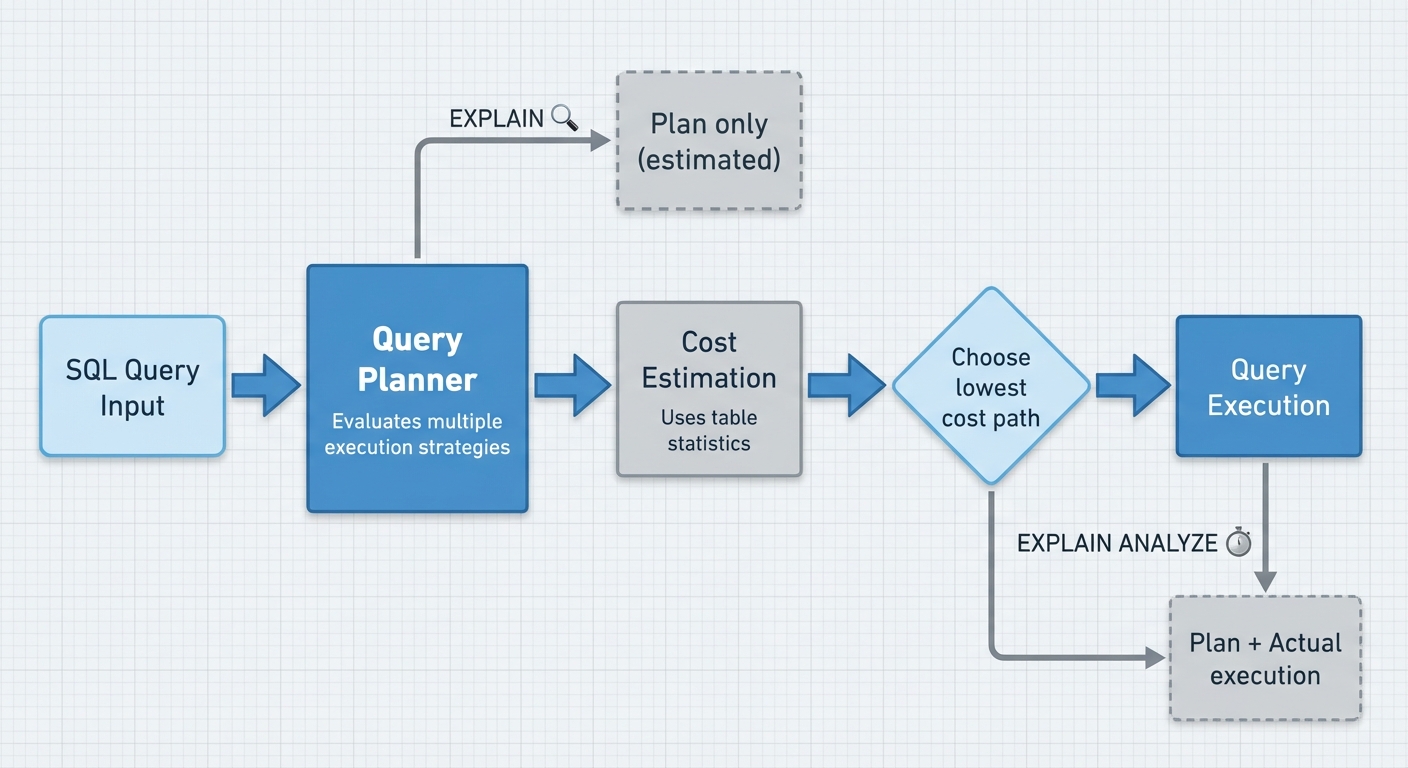
EXPLAIN vs EXPLAIN ANALYZE
EXPLAIN은 쿼리를 실행하지 않고 플래너의 실행 계획만 보여줍니다. 테이블 통계에 기반한 추정 비용, 행 개수, 전략 등이 나옵니다.
EXPLAIN ANALYZE는 쿼리를 실제로 실행하고 계획과 실제 실행 지표를 함께 보여줍니다. SELECT 쿼리의 추정치와 실제 값을 비교할 때는 이걸 써야 합니다. DML 작업(INSERT/UPDATE/DELETE)에 사용할 때는 주의하세요. 트랜잭션으로 감싸서 롤백하지 않으면 실제로 데이터가 변경됩니다.
EXPLAIN (ANALYZE, BUFFERS, FORMAT TEXT)
SELECT * FROM table_a a
JOIN table_b b ON a.id = b.a_id
WHERE a.job_id = 123;
주요 옵션
ANALYZE: 쿼리를 실행하고 실제 소요 시간과 행 개수를 보여줍니다. 이게 없으면 추정치만 보게 됩니다.
BUFFERS: 버퍼 사용량을 보여줍니다. 공유 버퍼(캐시)에서 몇 블록을 읽었는지, 디스크 I/O가 얼마나 발생했는지 알 수 있습니다. I/O 병목을 찾을 때 필수입니다.
FORMAT: TEXT (기본값, 사람이 읽기 좋음), JSON, XML, YAML. 프로그램으로 파싱할 땐 JSON을 쓰고, 눈으로 볼 땐 TEXT를 쓰세요.
VERBOSE: 출력 컬럼 목록이나 테이블 별칭(Alias) 같은 추가 정보를 보여줍니다. 별칭 문제나 컬럼 가지치기(Pruning) 이슈를 디버깅할 때 유용합니다.
TIMING: ANALYZE와 함께 기본적으로 켜져 있습니다. 각 노드의 실제 실행 시간을 측정합니다. 수백만 번 반복되는 루프가 있는 쿼리에서는 타이밍 오버헤드가 커질 수 있으니 끌 수도 있습니다(TIMING FALSE).
실행 계획 읽는 법
실행 계획의 각 줄은 하나의 연산 노드를 나타냅니다. 들여쓰기는 부모-자식 관계를 보여주며, 안쪽 노드가 바깥쪽 노드보다 먼저 실행됩니다.
Nested Loop (cost=0.56..123.45 rows=10 width=64) (actual time=0.032..0.089 rows=8 loops=1)
-> Index Scan using table_a_job_id_idx on table_a a (cost=0.28..8.30 rows=10 width=32) (actual time=0.015..0.021 rows=8 loops=1)
Index Cond: (job_id = 123)
Buffers: shared hit=3
-> Index Scan using table_b_pkey on table_b b (cost=0.28..11.50 rows=1 width=32) (actual time=0.006..0.006 rows=1 loops=8)
Index Cond: (a_id = a.id)
Buffers: shared hit=16
Cost: 첫 번째 숫자(0.56)는 시작 비용(첫 행을 리턴하기까지의 비용)입니다. 두 번째 숫자(123.45)는 모든 행을 처리했을 때의 총비용입니다. 비용은 누적됩니다. 상위 노드의 총비용은 하위 노드의 비용을 포함합니다. 비용 단위는 seq_page_cost, random_page_cost, cpu_tuple_cost 설정에 기반합니다. 절대적인 시간이 아니라 계획 간의 상대적인 비교 지표로 보세요.
Rows: 플래너가 이 노드에서 리턴할 것이라 예상하는 행 개수입니다. 실제 행 개수와 비교해 보세요.
Width: 예상되는 평균 행 크기(바이트)입니다.
Actual time: 실제 실행 시간(밀리초)입니다. 첫 번째 숫자는 첫 행이 나올 때까지, 두 번째는 전체 시간입니다. 둘 다 루프당(per loop) 시간입니다.
Rows (actual): 실제로 리턴된 행 개수입니다. 이 값이 추정치(Rows)와 크게 다르다면, 플래너가 낡은 통계를 보고 있을 확률이 높습니다.
Loops: 이 노드가 실행된 횟수입니다. 중요: actual time에 loops를 곱해야 해당 노드의 총 소요 시간이 나옵니다. 0.1ms 걸리는 인덱스 스캔이 100,000번 루프를 돌면 = 10,000ms = 10초가 걸린 겁니다.
Buffers: 버퍼 하나는 8KB입니다. shared hit(캐시 읽기), shared read(디스크 I/O), shared dirtied(변경됨), temp read/temp written(work_mem 초과 시)을 보여줍니다. shared hit=3은 캐시에서 24KB를 읽었다는 뜻입니다. shared read가 높으면 디스크 I/O 병목이고, temp 작업이 보이면 work_mem 고갈을 의미합니다.
병렬 계획 (Parallel Plans)
최신 PostgreSQL은 비싼 쿼리에 대해 병렬 실행을 사용합니다. Parallel Seq Scan이나 Gather 노드를 찾아보세요. 만약 Workers Planned보다 Workers Launched가 적다면, PostgreSQL이 백그라운드 워커를 충분히 할당하지 못한 겁니다. max_parallel_workers_per_gather(쿼리당 제한)와 max_parallel_workers(시스템 전체 제한), 그리고 현재 시스템 부하를 확인해 보세요.
무엇을 봐야 하는가
- 추정치 불일치: 추정 행 수와 실제 행 수가 10배 이상 차이 나면 플래너가 잘못된 판단을 한 겁니다. 2-3배 정도는 괜찮지만, 10배가 넘어가면 통계 문제거나 플래너가 이해하기 힘든 복잡한 조건절이 있는 겁니다.
- 대용량 테이블의 시퀀셜 스캔: 작은 테이블이나 대부분의 행을 가져올 때는 괜찮지만, 인덱스 스캔을 기대했는데 시퀀셜 스캔이 떴다면 적신호입니다.
- 루프 횟수가 많은 중첩 루프: 각 반복마다 내부 쿼리를 다시 실행합니다. 내부 쿼리가 비싼데 루프가 10,000번 돈다면 큰일 난 겁니다.
- 높은 버퍼 읽기:
shared read가 지배적이라면 디스크를 치고 있는 겁니다. 인덱스를 추가하거나shared_buffers를 늘리는 걸 고려하세요.
테이블 통계: 쿼리 계획의 기초
쿼리 플래너는 pg_stats에 있는 통계 정보를 이용해 비용을 추정합니다. 이 정보는 ANALYZE 명령어가 수집합니다. 모든 카디널리티(Cardinality) 추정은 이 통계에서 나옵니다.
-- 특정 테이블과 컬럼의 통계 보기
SELECT
schemaname,
tablename,
attname,
null_frac,
n_distinct,
most_common_vals,
most_common_freqs,
histogram_bounds,
correlation
FROM pg_stats
WHERE tablename = 'your_table'
AND attname = 'your_column';
ANALYZE table_name을 실행하면 이 통계가 갱신됩니다. 오토바큠(Autovacuum)이 자동으로 처리해 주지만, 대량 데이터 변경 후에는 수동 ANALYZE가 필요할 수 있습니다.
주요 통계 설명
null_frac: 컬럼 내 NULL 값의 비율(0.0 ~ 1.0)입니다. 0.15라면 15%가 NULL이라는 뜻입니다. IS NULL, IS NOT NULL 조건의 선택도에 직접적인 영향을 줍니다.
n_distinct: 고유 값(Distinct values)의 추정 개수입니다. 양수면 실제 개수이고, 음수면 전체 행 수 대비 비율입니다. 10,000행 테이블에 n_distinct = -0.5라면, abs(-0.5) * 10000 = 5,000개의 고유 값이 있다고 추정합니다. 조인 카디널리티와 GROUP BY 연산 추정에 매우 중요합니다.
most_common_vals (MCV): 컬럼에서 가장 자주 등장하는 값들의 배열입니다. default_statistics_target 설정(기본값: 100)이 수집 개수에 영향을 주지만, 실제 저장되는 개수는 데이터 분포에 따라 다릅니다. 데이터가 한쪽으로 쏠려 있다면 MCV가 많을 것이고, 고르다면 적거나 없을 겁니다. 플래너는 이 값들에 대해 통계적 추정이 아닌 정확한 빈도를 사용합니다.
most_common_freqs: most_common_vals에 대응하는 빈도입니다. 빈도가 0.08이면 해당 값이 전체 행의 8%를 차지한다는 뜻입니다.
histogram_bounds: MCV에 포함되지 않는 값들에 대한 버킷 경계값 배열입니다. MCV와 히스토그램 값은 상호 배타적입니다. PostgreSQL은 ‘동등 깊이(Equi-depth)’ 히스토그램을 사용합니다. 즉, 각 버킷은 값의 범위가 아니라 포함된 행의 개수가 비슷하도록 나뉩니다. 따라서 데이터 분포에 따라 버킷의 폭이 달라집니다. 버킷 개수는 대략 default_statistics_target - num_mcv_entries입니다. MCV가 대부분의 값을 커버한다면 히스토그램이 아예 없을 수도 있습니다. 플래너는 각 버킷 내에서는 데이터가 균등하게 분포한다고 가정합니다.
correlation: 물리적 디스크 순서와 논리적 컬럼 순서가 얼마나 일치하는지를 나타내는 -1과 1 사이의 값입니다. 1.0은 완벽하게 정렬됨, -1.0은 완벽하게 역순, 0은 상관관계 없음을 의미합니다. ~0.5 이상이나 ~-0.5 이하면 범위 쿼리에서 인덱스 스캔이 유리하고, 0에 가까우면 랜덤 I/O 비용 때문에 시퀀셜 스캔이 선택될 가능성이 높습니다. 이 통계는 단일 컬럼 인덱스에 적용되며 ANALYZE 때마다 다시 계산됩니다.
왜 중요한가
플래너가 WHERE status = 'active'를 평가할 때:
- ‘active’가
most_common_vals에 있는지 확인하고, 있다면most_common_freqs의 정확한 빈도를 사용합니다. - MCV에 없다면
histogram_bounds를 이용해 어느 버킷에 속하는지 파악하고 선택도를 추정합니다. - MCV도 히스토그램도 적용되지 않으면
1 / n_distinct(균등 분포 가정)로 넘어갑니다. - 조건이 NULL을 필터링한다면
null_frac을 보정합니다. - 인덱스 접근 비용을 계산할 땐
correlation을 참고합니다.
오래되거나 누락된 통계는 나쁜 쿼리 계획의 주원인입니다. 실제 고객은 100만 명인데 통계상 1,000명이라고 되어 있다면, 플래너는 조인 비용을 터무니없이 낮게 잡고 비효율적인 알고리즘을 선택할 겁니다.
조인 전략은 어떻게 결정되는가
PostgreSQL 플래너는 가능한 각 조인 전략에 대해 통계와 내부 비용 파라미터를 기반으로 총비용을 추정한 뒤, 가장 싼 것을 고릅니다.
결정을 주도하는 비용 파라미터들
PostgreSQL은 여러 연산을 비교 가능한 비용 단위로 변환하기 위해 몇 가지 파라미터를 사용합니다. 이 단위들은 차원이 없는 상대적인 값이지, 실제 시간(초)이 아닙니다.
seq_page_cost(기본값: 1.0) - 순차적인 페이지 읽기 비용random_page_cost(기본값: 4.0) - 랜덤 페이지 읽기 비용cpu_tuple_cost(기본값: 0.01) - 한 행을 처리하는 비용cpu_operator_cost(기본값: 0.0025) - 연산자 하나를 평가하는 비용
랜덤 I/O와 순차 I/O의 4:1 비율은 회전하는 하드 디스크(HDD)의 성능 특성을 반영한 겁니다. SSD에서는 이 비율을 1.5~2.0 정도로 조정하면 랜덤 액세스가 훨씬 빠르다는 점이 반영되어 더 나은 계획이 나오곤 합니다.
조인 전략 비용 모델
각 조인 알고리즘은 고유한 비용 계산 모델을 가집니다.
중첩 루프: 비용 ≈ outer_cost + (outer_rows × inner_cost_per_lookup). 내부 비용은 인덱스 존재 여부에 따라 달라집니다(외부 행마다 풀 스캔 vs 인덱스 룩업). 선택도 높은 필터와 내부 인덱스가 있다면 이 방식이 압도적으로 저렴할 수 있습니다.
해시 조인: 비용에는 내부 릴레이션으로 해시 테이블을 만드는 비용(한 번 스캔 + 해싱 CPU 비용)과 외부 행마다 이를 조회하는 비용이 포함됩니다. 메모리가 중요합니다. 해시 테이블이 work_mem을 넘겨서 디스크 스필이 발생하면, 막대한 I/O 비용이 추가되어 계획상 비용이 급증합니다.
머지 조인: 두 입력을 정렬하는 비용(이미 정렬되지 않은 경우) + 정렬된 릴레이션을 한 번씩 순차적으로 훑는 비용입니다. 양쪽이 조인 키로 이미 정렬되어 있다면(인덱스 등) 매우 효율적입니다.
PostgreSQL 소스 코드의 실제 비용 함수는 시작 비용, 조건절(Qualification), 병렬 워커 오버헤드 등 더 많은 요소를 고려합니다.
조인 공간 탐색
N개의 테이블이 있다면 수많은 조인 순서가 가능합니다. PostgreSQL은 최대 12개 테이블(geqo_threshold로 제어)까지는 동적 계획법(Dynamic Programming)을 사용해 모든 대안을 탐색합니다. 이 한계치를 넘어가면 계획 시간이 너무 길어지는 걸 막기 위해 유전 알고리즘(GEQO)으로 전환합니다.
탐색 공간을 제약하는 몇 가지 파라미터가 있습니다.
join_collapse_limit- 함께 최적화할 FROM/JOIN 항목의 최대 개수from_collapse_limit- 서브쿼리를 별도로 최적화하기 전까지 허용하는 테이블 개수enable_nestloop,enable_hashjoin,enable_mergejoin- 테스트 목적으로 특정 전략을 끄는 옵션
enable_hashjoin = off로 설정하면 플래너가 다른 전략을 쓰도록 강제할 수 있어, 해시 조인이 문제인지 격리해서 확인해 볼 때 유용합니다.
통계: 비용 추정의 기초
행 개수(Row count) 추정치는 모든 비용 계산의 원동력입니다. 플래너는 다음과 같은 테이블 통계에 의존합니다.
- 행 개수와 테이블 크기
- 고유 값 개수 (n_distinct)
- 빈번한 값과 빈도를 보여주는 MCV 리스트
- 값 분포를 보여주는 히스토그램 버킷
- 물리적/논리적 순서의 상관관계 (Correlation)
플래너가 다음 쿼리를 어떻게 추정할지 생각해 보세요.
SELECT * FROM orders o
JOIN customers c ON o.customer_id = c.id
WHERE c.country = 'US';
플래너는 country 컬럼의 MCV 리스트를 확인합니다. ‘US’가 있다면 저장된 빈도를 사용합니다. 없다면 히스토그램을 보거나 고유 값에 대해 균등 분포를 가정합니다. 실제로는 고객의 50%가 ‘US’인데 통계상으로는 5%라고 되어 있다면, 플래너는 해시 테이블 크기를 과소평가할 것이고, 효율적인 해시 조인 대신 머지 조인을 잘못 선택할 수도 있습니다.
계획이 왜 틀어지는가
통계 오류는 나쁜 계획 선택으로 이어집니다. 1,000행에서 100만 행으로 커졌는데 ANALYZE가 안 된 테이블이 있다면, 플래너는 아주 작은 테이블에 최적화된 전략을 고를 겁니다. MCV나 히스토그램이 없으면 플래너는 균등 분포를 가정하는데, 데이터가 심하게 쏠려 있고 통계마저 낡았다면 심각한 오판을 하게 됩니다. 성능 저하의 폭은 어떤 조인 방식이 선택되었는지, 그리고 행 추정치가 실제와 얼마나 차이 나는지에 따라 결정됩니다.
이 모든 이야기는 결국 ANALYZE 프로세스로 귀결됩니다. 이 녀석이 그 중요한 통계를 수집하니까요.
PostgreSQL Analyzer: 통계 생성기
ANALYZE는 테이블 데이터를 샘플링하여 쿼리 플래너를 위한 통계를 만듭니다. 히스토그램, 최빈값, NULL 비율 같은 이 통계들이 비용 추정의 근거가 되고, 조인 순서와 접근 방식을 결정합니다. PostgreSQL의 오토바큠 데몬이 이걸 자동으로 처리하지만, 필요하다면 수동으로 실행할 수도 있습니다(대량 로드 직후나 오토바큠이 못 따라갈 때 등).
트리거 로직
오토바큠 워커는 주기적으로(autovacuum_naptime, 기본 1분) 각 테이블이 분석(Analyze) 필요한지 체크합니다. 공식은 다음과 같습니다.
autovacuum_analyze_threshold + autovacuum_analyze_scale_factor * reltuples
reltuples는 pg_class에 있는 추정 행 개수입니다. pg_stat_user_tables의 n_mod_since_analyze(마지막 분석 이후 변경된 행 수)가 이 임계치를 넘으면 ANALYZE가 실행됩니다.
기본 설정:
autovacuum_analyze_threshold: 50행autovacuum_analyze_scale_factor: 0.10 (10%)
100만 행 테이블이라면 100,050건의 변경이 있어야 재분석됩니다. 만약 매일 10,000행을 업데이트하는데 특정 패턴으로만 업데이트한다면, 통계는 10일 동안 낡은 상태로 유지됩니다. 분포가 바뀌어 실행 계획이 망가지기에 충분한 시간이죠. 플래너는 낡은 분포를 믿고 인덱스 룩업 대신 시퀀셜 스캔을 하거나, 해시 조인 대신 중첩 루프를 고를 수 있습니다.
임계치가 테이블 크기에 비례해서 커진다는 게 문제입니다. 1,000만 행 테이블은 100만 건 넘게 변경되어야 통계가 갱신됩니다. ANALYZE 자체도 비용(샘플링 I/O)이 들기 때문에 무작정 자주 할 순 없습니다. 하지만 업데이트가 특정 범위에 집중되는 테이블(시계열 데이터, 상태 값이 변하는 컬럼 등)에서는 통계가 현실과 동떨어져 쿼리 성능을 갉아먹을 수 있습니다.
참고로 reltuples 자체도 추정치입니다. 마지막 바큠 이후 테이블이 엄청 커졌다면 임계치 계산에도 낡은 메타데이터가 쓰여 분석이 더 지연될 수 있습니다.
업데이트 패턴이 집중되는 테이블이라면, 스케일 팩터를 낮춰서 분포 변화를 더 빨리 포착하게 하세요.
ALTER TABLE orders SET (autovacuum_analyze_scale_factor = 0.05);
이렇게 하면 임계치가 50 + 5%로 낮아져서, 쿼리 계획에 영향을 줄 만한 분포 변화가 생겼을 때 더 자주 분석하게 됩니다.
PostgreSQL ANALYZE의 내부 메커니즘
PostgreSQL의 ANALYZE 작업은 전체 테이블을 뒤지는(Full Scan) 게 아니라 확률적 샘플링(Probabilistic Sampling) 방식을 사용합니다. 덕분에 리소스 사용량을 예측 가능한 수준으로 유지하면서 데이터 분포 모델을 만들 수 있습니다.
고정 샘플 크기 vs 풀 스캔
ANALYZE 프로세스는 각 테이블에서 대략 $300 \times \text{default_statistics_target}$ 개의 행을 선택하는 샘플링 알고리즘을 따릅니다. 기본 타깃이 100이라면, 테이블이 100만 행이든 1억 행이든 상관없이 약 30,000행을 샘플링합니다. 이 고정된 샘플 크기 덕분에 테이블이 커져도 분석 비용이 선형적으로 늘어나지 않습니다. 물론 샘플링된 행들이 디스크 블록 여기저기에 흩어져 있다면 시간은 좀 더 걸리겠지만, 전체 힙(Heap)을 시퀀셜 스캔하는 것보다는 훨씬 가볍습니다.
통계 타깃: 샘플 크기와 저장소
default_statistics_target 파라미터는 통계 모델의 정밀도를 조절하는 핵심 레버입니다. 두 가지 내부 동작을 결정합니다.
- 샘플링 깊이: 엔진은 타깃 × 300개의 행을 분석해 분포 프로필을 만듭니다.
- 모델 해상도:
pg_statistic시스템 카탈로그에 저장될 컬럼당 최빈값(MCV)과 히스토그램 버킷의 최대 개수를 결정합니다.
타깃을 높이면 플래너에게 더 정교한 정보를 줄 수 있지만, 분석 시간이 길어지고 카탈로그 저장 공간을 더 씁니다. 컬럼 레벨에서 정밀도와 성능의 균형을 맞출 수 있습니다.
-- 자주 필터링되는 컬럼의 통계 상세도 높이기
ALTER TABLE orders ALTER COLUMN status SET STATISTICS 200;
-- 별로 중요하지 않은 컬럼은 낮추기
ALTER TABLE logs ALTER COLUMN log_level SET STATISTICS 50;
새 타깃을 반영하려면 수동 ANALYZE를 실행해야 합니다.
메모리와 저장소 제약
메모리 고갈과 시스템 카탈로그 비대화를 막기 위해, PostgreSQL은 분석 데이터의 물리적 크기에 제한을 둡니다.
/* PostgreSQL 소스 (analyze.c):
* 분석 중 과도한 메모리 사용과 pg_statistic 행의 크기 증가를 막기 위해,
* WIDTH_THRESHOLD보다 넓은 varlena 데이터(압축 해제 후!)는 무시합니다.
* 이는 MCV나 고유 값 계산에서 합당한데, 너무 넓은 값은 중복될 확률이 낮고
* 최빈값이 될 확률은 더더욱 낮기 때문입니다.
*/
#define WIDTH_THRESHOLD 1024
1024바이트를 넘는 값은 통계 수집 단계에서 잘립니다. 큰 텍스트 필드나 복잡한 JSON 문서가 있는 컬럼은 정확한 MCV 통계를 얻지 못할 수 있고, 이는 플래너가 일반적인 선택도 가정으로 후퇴하게 만들어 쿼리 계획에 영향을 줄 수 있습니다.
성능 특성
ANALYZE의 실행 프로필은 데이터의 일부에 접근하는 효율성에 달려 있습니다. 소요 시간은 다음 요소들의 함수입니다.
- 블록 산포도(Block Scattering): 샘플 행을 가져오기 위해 얼마나 많은 디스크 블록을 건드려야 하는가.
- 통계 타깃: 타깃이 높으면 메모리에서 처리해야 할 행 개수가 늘어납니다.
- I/O 처리량: 스토리지 레이어의 랜덤 액세스 읽기 속도.
- 컬럼 메타데이터: 특정 데이터 타입이나 넓은 값을 처리하는 계산 오버헤드.
일반적인 설정에서 적당한 크기의 테이블이라면 1초 미만에 끝납니다. VLDB(초대용량 데이터베이스) 환경에서는 샘플 크기는 고정이라도 데이터가 물리적으로 넓게 퍼져 있어 샘플링 단계에서 I/O 대기 시간이 길어질 수 있습니다.
참고: PostgreSQL ANALYZE Documentation
진짜 원인이 밝혀지다
대량 Insert 직후, PostgreSQL의 통계 테이블(pg_stats)은 새로 들어온 job_id에 대해 예상 행 개수를 0으로 잡고 있었습니다. 50,000행을 넣었지만, 전체 테이블 크기에 비하면 너무 작아서 오토바큠 ANALYZE 임계치를 넘지 못했기 때문입니다.
왜 ‘0’ 추정치가 중첩 루프를 부르는가
예상 행 개수가 0이면 중첩 루프 비용 계산은 0행 × (인덱스 룩업 1회 비용) ≈ 0이 됩니다. 반면 해시 조인은 결과가 없더라도 해시 테이블을 만드는 기본 오버헤드가 있습니다. 계산기 두드려 보니 중첩 루프가 압도적으로 싸게 나온 거죠. 플래너는 낡은 통계를 바탕으로 지극히 합리적인 결정을 내린 겁니다. 결과 집합이 정말 작다면 중첩 루프가 최적이니까요. 문제는 실제 결과가 전혀 작지 않았다는 점입니다.
오토바큠 임계치 문제
PostgreSQL의 기본 오토바큠은 변경된 행(Insert + Update + Delete)의 수가 다음을 초과할 때 ANALYZE를 트리거합니다.
변경된_행 > (전체_행 × 0.1) + 50
테이블이 100,000행일 때 50,000행 Insert는 ANALYZE를 트리거했습니다.
50,000 > (100,000 × 0.1) + 50
50,000 > 10,050 ✓ ANALYZE 발동
하지만 테이블이 500만 행으로 커지자, 똑같은 50,000행 Insert가 임계치를 넘지 못했습니다.
50,000 > (5,000,000 × 0.1) + 50
50,000 > 500,050 ✗ ANALYZE 발동 안 함
Insert 양은 그대로인데 테이블이 커지면서, 예전엔 확실히 트리거되던 통계 갱신이 이제는 임계치 밑으로 숨어버린 겁니다.
참고로 오토바큠은 청소(Vacuum, 죽은 튜플 정리)와 통계 갱신(Analyze)의 임계치가 따로 돕니다. Vacuum 임계치만 넘으면 청소는 하는데 통계는 갱신 안 할 수도 있습니다.
왜 수년간 잘 되다가 터졌나
테이블은 10만 행 수준(5만 행 넣으면 ANALYZE 됨)에서 시작해 500만 행 이상(이제 안 됨)으로 자라났습니다. 50만 행을 넘어서는 시점부터 서서히 문제가 잉태되고 있었던 거죠. 50만 행의 10%가 5만 행이니까요.
이 문제는 다음과 같은 특성을 가진 운영 환경에서만 나타났습니다.
- 기존 데이터가 큼 (수백만 행)
- 꾸준한 대량 Insert가 발생하지만 전체 크기에 비하면 상대적으로 작음
- Insert 직후, 다른 작업이 ANALYZE를 트리거하기 전에 쿼리가 실행됨
자가 치유(Self-Healing)의 함정
쿼리는 시간이 지나면 개입 없이도 다시 빨라졌습니다. 이후 다른 Insert, Update, Delete가 누적되어 결국 ANALYZE가 실행되면 통계가 갱신되었으니까요. 그러면 플래너는 job_id에 대해 50,000행을 제대로 추정하고 해시 조인을 선택했습니다.
문제는 간헐적이었습니다. 대량 Insert와 다음 ANALYZE 트리거 사이의 ‘마의 구간’에서만 발생했죠. 테이블 활동량에 따라 이 구간은 몇 시간에서 며칠이 될 수도 있었습니다. 슬로우 쿼리 로그에는 찍히는데, 엔지니어가 조사하러 들어갔을 땐 이미 통계가 갱신되어 성능이 정상으로 돌아온 뒤였던 겁니다.
조인 전략 선택에 영향을 주는 또 다른 요소가 있습니다. 바로 메모리 설정입니다.
work_mem 변수
work_mem 설정은 쿼리 연산(정렬, 해싱)당 사용할 수 있는 메모리를 제한합니다. PostgreSQL이 해시 조인을 하려는데 해시 테이블이 work_mem 안에 들어간다고 판단하면, 비용 계산은 주로 CPU 연산 위주가 됩니다. 하지만 메모리가 모자랄 것 같으면, 임시 파일 디스크 I/O 비용을 추가하여 해시 조인을 훨씬 비싸게 평가합니다.
-- 메모리 사용량을 보여주는 EXPLAIN 예시
Hash Join (cost=... rows=...)
Hash Cond: (a.id = b.a_id)
-> Seq Scan on table_a
-> Hash (cost=... rows=...)
Buckets: 16384 Batches: 1 Memory Usage: 512kB
-> Seq Scan on table_b
Batches: 1은 해시 테이블이 메모리에 쏙 들어갔다는 뜻입니다. Batches > 1이라면 디스크 스필이 발생해서 데이터를 여러 번 읽었다는 뜻입니다. work_mem이 4MB인데 사용량이 512kB라면 여유롭게 메모리 안에서 처리된 겁니다.
모든 쿼리에서 디스크 스필을 감지하려면 임시 파일 로깅을 켜세요.
SET log_temp_files = 0; -- 모든 임시 파일 생성 로그 기록
비용 모델
플래너는 다음 파라미터를 사용해 메모리 연산과 디스크 연산의 무게를 잽니다.
seq_page_cost(기본 1.0): 디스크 페이지 순차 읽기 비용cpu_operator_cost(기본 0.0025): 행이나 표현식 하나 처리 비용
기본값 비율(1.0 vs 0.0025)을 보면 플래너가 디스크 I/O에 엄청난 페널티를 준다는 걸 알 수 있습니다. 디스크로 넘치는(Spill) 해시 조인은 인메모리 방식보다 훨씬 비싸게 계산되고, 그래서 플래너는 종종 중첩 루프나 머지 조인으로 선회합니다.
트레이드오프
높은 work_mem (예: 512MB):
- 복잡한 쿼리가 인메모리 연산으로 빨라짐
- 여러 연결이 동시에 메모리를 많이 쓰면 OOM(Out of Memory) 킬 당할 위험 있음
- 쿼리 하나가
work_mem을 여러 번 쓸 수 있음(정렬이나 해시마다 하나씩). 해시 조인 3번 하면 3 × work_mem 사용 가능.
낮은 work_mem (예: 4MB):
- 다수 연결에 대해 메모리 사용량 예측 가능
- 적당한 크기의 해시 조인도 자주 디스크 스필 발생
- 쿼리는 느려지지만 시스템 동작은 안정적
work_mem 사이징은 가용 메모리, 연결 수, 쿼리 복잡도를 모두 고려해야 합니다. 워크로드 패턴을 보고 보수적으로 시작하세요. 조인이 많은 쿼리는 단순 OLTP보다 예산이 더 필요합니다.
조인을 최적화하는데 전략 선택이 이상하다면, work_mem이 쿼리 패턴과 맞는지 확인해 보세요. 특정 세션에만 적용할 수도 있습니다.
SET work_mem = '256MB';
-- 쿼리 실행
왜 PostgreSQL에는 쿼리 힌트(Hint)가 없는가
MySQL, Oracle, SQL Server는 쿼리 힌트를 지원합니다. PostgreSQL은 아닙니다.
이건 의도적인 설계 결정입니다. PostgreSQL 팀은 OptimizerHintsDiscussion 위키 페이지에 그 이유를 밝혀뒀습니다.
/* PostgreSQL Wiki - OptimizerHintsDiscussion 발췌:
- 애플리케이션 코드 유지보수성 저하: 힌트 때문에 쿼리 리팩토링이 힘들어짐
- 업그레이드 방해: 지금 유용한 힌트가 업그레이드 후에는 성능 족쇄가 됨
- 나쁜 DBA 습관 조장: 진짜 문제를 찾는 대신 힌트부터 붙임
- 데이터 크기 변화에 대응 불가: 테이블이 작을 때 맞던 힌트가 커지면 틀림
- 실제로 성능 향상 실패: 대부분의 경우 옵티마이저가 더 똑똑함
- 쿼리 플래너 개선 방해: 힌트를 쓰면 문제를 리포트하지 않음
*/
핵심 우려는 힌트가 데이터 변화에 따라 쉽게 깨진다는(Brittle) 겁니다. 선택도 1%일 때 인덱스 스캔을 강제한 힌트는, 데이터가 변해 80%가 일치하게 되면 재앙이 됩니다. 1월에 쿼리를 살렸던 힌트가 3월엔 성능을 죽일 수 있습니다.
PostgreSQL의 접근 방식은 개발자가 힌트로 땜질하게 하는 대신, 플래너의 비용 모델을 고치고 통계 수집을 개선하는 것입니다.
물론 코어에는 없지만 pg_hint_plan 같은 확장이 존재하긴 합니다. 하지만 코어 팀의 우려는 여전히 유효합니다.
그럼에도 플래너가 멍청한 결정을 할 땐 해결책이 필요합니다. 여기 실질적인 해법들이 있습니다.
해결책 1: 수동 ANALYZE
오토바큠을 기다리지 말고 대량 Insert 직후에 즉시 ANALYZE를 때리세요.
두 가지 방법이 있습니다.
-- 테이블 전체 분석
ANALYZE table_name;
-- 특정 컬럼만 분석 (더 빠름)
ANALYZE table_name (job_id);
전체 테이블 분석은 모든 컬럼을 샘플링하느라 I/O 오버헤드가 큽니다. job_id처럼 쿼리 계획에 결정적인 컬럼을 안다면 그것만 분석하세요.
ANALYZE가 갱신하는 것:
히스토그램, 최빈값(MCV), 고유 값 개수(n_distinct), 상관관계(Correlation) 등 플래너가 믿고 의지하는 통계들입니다. 최신 통계 없이는 플래너가 시퀀셜 스캔과 인덱스 사용 사이에서 똥볼을 찹니다.
언제 트리거할까:
기본 오토바큠은 10% + 50행 변경 시 돕니다. 10만 행 테이블에 5만 행(50%)을 넣으면 바로 돌겠지만, 500만 행 테이블에 5만 행(1%)은 어림도 없습니다. 수동 ANALYZE는 오토바큠 주기를 기다리지 않고 통계를 즉시 최신화합니다.
pg_stat_user_tables를 모니터링하세요.
SELECT schemaname, relname, n_mod_since_analyze, last_analyze
FROM pg_stat_user_tables
WHERE relname = 'table_name';
n_mod_since_analyze가 전체 행 수 대비 높다면 통계가 썩은 겁니다.
워크플로우 통합:
대량 Insert 완료 -> ANALYZE 실행 -> 통계 의존 쿼리 실행 순서로 갑니다.
import psycopg2
conn = psycopg2.connect(...)
conn.autocommit = True # ANALYZE는 트랜잭션 블록 밖에서 실행해야 함
try:
with conn.cursor() as cur:
# 트랜잭션 내에서 대량 Insert
conn.autocommit = False
cur.execute("BEGIN")
execute_bulk_insert(cur, batch_data)
cur.execute("COMMIT")
# 트랜잭션 밖에서 ANALYZE
conn.autocommit = True
cur.execute("ANALYZE table_name (job_id)")
# 이제 쿼리는 신선한 통계를 사용함
cur.execute("SELECT job_id, COUNT(*) FROM table_name GROUP BY job_id")
results = cur.fetchall()
except Exception as e:
logger.error(f"Batch processing failed: {e}")
raise
큰 테이블이라면 락 점유를 최소화하기 위해 트랜잭션 밖에서 실행하세요.
성능 특성:
ANALYZE는 SHARE UPDATE EXCLUSIVE 락을 잡습니다. 읽기/쓰기는 허용하지만, 스키마 변경이나 다른 ANALYZE는 막습니다. 소요 시간은 테이블 크기와 default_statistics_target에 따라 다릅니다.
- 소형 (<10만): 밀리초
- 중형 (100만
1000만): 15초 - 대형 (>1억): 수십 초
default_statistics_target이 높으면 통계 품질은 좋아지지만 시간이 더 걸립니다. 필요하다면 컬럼별로 조정하세요.
ALTER TABLE table_name ALTER COLUMN job_id SET STATISTICS 1000;
오토바큠도 동시에 돌 수 있지만, 수동 ANALYZE가 끝날 때까지 기다립니다.
트레이드오프:
배포 스크립트나 배치 잡, CI/CD 파이프라인을 수정해야 합니다. 깜빡하면 오토바큠이 돌 때까지 성능이 조용히 나락으로 갑니다.
주기적인 배치 패턴이 있다면 pg_cron 같은 스케줄러를 고려해 보세요. n_mod_since_analyze 알람도 걸어두고요. ANALYZE는 운영 중에 돌려도 안전하지만, 피크 타임에 초대형 테이블 전체를 분석하는 건 피하는 게 좋겠죠.
해결책 2: 세션 레벨 플래너 제어
SET 명령어로 런타임에 플래너를 조종할 수 있습니다. 특정 전략을 끄고 쿼리를 돌린 뒤 원상복구 하는 식입니다.
SET enable_nestedloop TO off;
SELECT *
FROM table_a a
JOIN table_b b ON a.id = b.a_id
JOIN table_c c ON b.id = c.b_id
JOIN table_d d ON c.id = d.c_id
WHERE a.job_id = $1;
SET enable_nestedloop TO on;
enable_nestedloop를 off로 한다고 해서 중첩 루프가 완전히 금지되는 건 아닙니다. 비용에 엄청난 페널티(10^10)를 줘서, 정말 대안이 없을 때만 쓰게 만드는 겁니다.
사용 사례
- 최적화된 복잡한 쿼리: 테스트를 통해 특정 조인 패턴이 답이라는 걸 알았을 때
- 리포트 생성: 여러 관련 쿼리에 대해 일관된 계획이 필요할 때
- 배치 처리: 전체 세션이 비슷한 작업을 수행할 때
트랜잭션 범위 설정 (추천)
SET LOCAL을 트랜잭션 안에서 쓰면 커밋이나 롤백 시 자동으로 설정이 풀립니다.
BEGIN;
SET LOCAL enable_nestedloop TO off;
SELECT * FROM table_a a
JOIN table_b b ON a.id = b.a_id
WHERE a.job_id = $1;
COMMIT; -- 여기서 설정 자동 리셋
수동 복구보다 훨씬 안전합니다. JDBC 예시:
Connection conn = dataSource.getConnection();
try {
conn.setAutoCommit(false);
Statement stmt = conn.createStatement();
stmt.execute("SET LOCAL enable_nestedloop TO off");
PreparedStatement ps = conn.prepareStatement(
"SELECT * FROM table_a a JOIN table_b b ON a.id = b.a_id WHERE a.job_id = ?"
);
ps.setLong(1, jobId);
ResultSet rs = ps.executeQuery();
// 결과 처리
conn.commit(); // 설정 자동 리셋
} catch (Exception e) {
conn.rollback(); // 롤백 시에도 리셋됨
} finally {
conn.close();
}
커넥션 풀 안전성
세션 설정은 연결이 닫히거나 리셋될 때까지 유지됩니다. 커넥션 풀을 쓴다면 설정을 복구하지 않았을 때 다른 요청이 변형된 플래너 설정을 물려받는 대참사가 일어날 수 있습니다.
SET LOCAL을 쓰면 트랜잭션 종료 시 리셋되므로 안전합니다. 트랜잭션 없이 SET을 써야 한다면 finally 블록에서 반드시 복구하세요.
conn = pool.get_connection()
try:
conn.execute("SET enable_nestedloop TO off")
result = conn.execute(complex_query)
conn.execute("SET enable_nestedloop TO on")
except:
conn.execute("SET enable_nestedloop TO on")
raise
finally:
conn.close()
ORM 통합
대부분의 ORM은 플래너 제어를 직접 지원하지 않습니다. MyBatis 같은 경우 쿼리 앞에 @Update로 SET 명령을 날릴 수 있지만 순서 보장이 까다롭습니다. 위에서 본 트랜잭션 스코프 SET LOCAL 방식이 ORM 작업을 감쌀 때 가장 확실합니다.
가능한 제어 옵션들
enable_nestedloop,enable_hashjoin,enable_mergejoin- 조인 전략enable_seqscan,enable_indexscan,enable_bitmapscan- 스캔 방식
전체 목록은 PostgreSQL 런타임 설정 문서를 참고하세요.
언제 피해야 하는가
이 방식은 쿼리 힌트보다 덜 정교합니다. 쿼리 내의 특정 조인 하나만 콕 집어서 중첩 루프를 끌 수는 없습니다. 그런 정밀 제어가 필요하다면 pg_hint_plan이 답입니다. SET 명령 자체는 매우 가벼우니(마이크로초 단위) 성능 걱정은 안 해도 됩니다.
해결책 3: pg_hint_plan 확장 (Extension)
pg_hint_plan 확장은 PostgreSQL에 오라클 스타일의 쿼리 힌트를 추가해 줍니다. 서드파티 확장이므로 서버에 설치해야 하고 shared_preload_libraries에 추가한 뒤 재시작해야 합니다. RDS나 Cloud SQL 같은 관리형 서비스에서는 지원 여부를 확인해야 합니다.
설치 요구사항
postgresql.conf에 추가:
shared_preload_libraries = 'pg_hint_plan'
재시작 후 실행:
CREATE EXTENSION pg_hint_plan;
기본 힌트 문법
주석 블록을 사용해 힌트를 줍니다.
/*+ HashJoin(a b) HashJoin(b c) HashJoin(c d) */
SELECT *
FROM table_a a
JOIN table_b b ON a.id = b.a_id
JOIN table_c c ON b.id = c.b_id
JOIN table_d d ON c.id = d.c_id
WHERE a.job_id = $1;
이 힌트는 각 조인 단계(a⋈b, 그 결과⋈c, 그 결과⋈d)마다 해시 조인을 강제합니다.
조인 순서 제어
조인 방법뿐 아니라 순서도 지정할 수 있습니다.
/*+ Leading((a (b (c d)))) HashJoin(a b c d) */
SELECT *
FROM table_a a
JOIN table_b b ON a.id = b.a_id
JOIN table_c c ON b.id = c.b_id
JOIN table_d d ON c.id = d.c_id
WHERE a.job_id = $1;
Leading 힌트는 조인 트리 구조를 정의합니다. 안쪽부터 바깥쪽으로: c와 d를 먼저 조인, 그 결과와 b를 조인, 마지막으로 a와 조인.
사용 가능한 힌트 유형
조인 방법:
HashJoin(table1 table2)- 해시 조인 강제NestLoop(table1 table2)- 중첩 루프 강제MergeJoin(table1 table2)- 머지 조인 강제
스캔 방법:
SeqScan(table)- 시퀀셜 스캔 강제IndexScan(table index)- 특정 인덱스 강제IndexOnlyScan(table index)- 인덱스 온리 스캔 강제
조인 순서:
Leading((table1 (table2 table3)))- 조인 트리 지정
힌트 검증
EXPLAIN으로 힌트가 먹혔는지 확인하세요.
EXPLAIN /*+ SeqScan(orders) */ SELECT * FROM orders WHERE customer_id = 123;
디버그 로깅을 켜면 파싱 내용을 볼 수 있습니다.
SET pg_hint_plan.debug_print = on;
유효하지 않은 힌트는 기본적으로 조용히 무시됩니다. 계획이 안 바뀌면 로그를 확인하세요.
ORM 호환성
힌트는 SQL 주석이므로 ORM을 통과합니다.
@Query(value = "/*+ HashJoin(e d) */ " +
"SELECT e FROM Employee e " +
"JOIN e.department d " +
"WHERE d.name = :name")
List<Employee> findByDepartmentName(@Param("name") String name);
장점
- 애플리케이션 코드 로직 변경 없이 정밀 제어 가능
- 커넥션 풀이나 ORM 환경에서도 동작
- 오라클 마이그레이션 시 친숙한 문법
- 특정 문제 쿼리만 핀셋 교정 가능
단점
- 서버 사이드 설치 필요 (관리형 DB에서 제약)
- 데이터가 변하면 힌트가 썩음 (오늘의 해시 조인이 내일의 재앙)
- 유지보수 부채: 힌트 하나하나가 수동 최적화 건임
- 네이티브 기능이 아니라 이식성 떨어짐
pg_hint_plan은 정말 외과 수술 같은 정밀함이 필요하고, 유지보수 비용을 감당할 수 있을 때만 쓰세요. 더 넓은 범위의 변경은 세션 설정이나 쿼리 리라이트(Rewrite)가 더 낫습니다.
이제 장기적인 안정성을 위한 운영 모범 사례를 봅시다.
운영 모범 사례 (Operational Best Practices)
운영 시스템은 적절한 설정과 지속적인 모니터링이 생명입니다.
default_statistics_target
ANALYZE 시 얼마나 많은 샘플을 수집할지 결정합니다 (기본 100).
값을 높이면(200-500) 고유 값이 많거나 데이터가 쏠린 컬럼에서 더 정확한 히스토그램을 얻을 수 있습니다. 대가는 pg_statistic 테이블 크기 증가와 ANALYZE 시간 증가입니다.
전역 설정을 바꾸기 전에 특정 컬럼만 조정해 보세요.
-- n_distinct 추정치가 정확한지 확인
SELECT schemaname, tablename, attname, n_distinct,
(SELECT COUNT(DISTINCT column_name) FROM your_table) as actual_distinct
FROM pg_stats
WHERE tablename = 'your_table' AND attname = 'problem_column';
-- 특정 컬럼만 타깃 상향
ALTER TABLE users ALTER COLUMN email SET STATISTICS 200;
ANALYZE users;
EXPLAIN에서 특정 컬럼의 카디널리티 추정이 엉망이거나, pg_stats.n_distinct가 실제 COUNT(DISTINCT)와 너무 다르다면 해당 컬럼의 타깃을 높이세요.
work_mem
정렬과 해시 테이블에 쓸 메모리입니다. 핵심: 연결당이 아니라 연산당입니다. 쿼리 하나가 정렬 2번, 해시 조인 1번 하면 work_mem의 3배를 씁니다.
너무 낮으면 디스크 스필이 발생하고, 너무 높으면 동시 접속이 몰릴 때 메모리가 터집니다.
-- 임시 파일 사용량 확인 (디스크 스필)
SELECT datname, temp_files,
pg_size_pretty(temp_bytes) as temp_size
FROM pg_stat_database
WHERE datname = current_database();
해석: temp_bytes가 지속적으로 높다면(처리 데이터의 1% 이상이라면), work_mem이 너무 낮은 겁니다. temp_files는 0인데 메모리 압박이 심하다면 work_mem이 너무 높은 겁니다.
천장(Ceiling) 계산: 100개 연결이 각각 2-3개 연산을 하고 work_mem=64MB라면, 이론상 최대 100 × 3 × 64MB = 19.2GB를 쓸 수 있습니다. 물론 동시에 다 돌진 않겠지만, 이게 최악의 시나리오입니다.
보수적으로 시작해서(4-16MB) 모니터링하며 늘려가세요.
통계 신선도 모니터링
데이터가 늘고 하드웨어가 바뀌면 설정도 적응해야 합니다.
-- 통계 썩은 테이블 찾기
SELECT schemaname, relname,
last_analyze,
last_autoanalyze,
n_live_tup
FROM pg_stat_user_tables
WHERE last_analyze < NOW() - INTERVAL '7 days'
AND n_live_tup > 10000
ORDER BY n_live_tup DESC;
ANALYZE 후 실행 계획이 바뀌는지 보세요. 갑자기 바뀐다면 데이터 분포가 이동했다는 신호입니다. 대형 테이블의 통계 나이에 알람을 거세요.
쿼리 성능 추이를 보려면 pg_stat_statements를 켜세요.
-- postgresql.conf
shared_preload_libraries = 'pg_stat_statements'
-- 총 실행 시간 기준 가장 느린 쿼리 확인
SELECT query, calls, total_exec_time, mean_exec_time
FROM pg_stat_statements
ORDER BY total_exec_time DESC
LIMIT 20;
단순하게 시작하고 증거를 보고 조정하라
PostgreSQL 기본값은 대부분의 워크로드에서 합리적입니다. 모니터링에서 명확한 문제가 보이기 전까진 설정을 건드리지 마세요.
pg_stat_database에서 임시 파일 스필이 보이면 work_mem을 조금씩(4MB → 8MB → 16MB) 늘리세요. EXPLAIN에서 특정 컬럼 추정치가 이상하면 그 컬럼의 통계 타깃을 높이세요. 한 번에 하나씩 바꾸고 측정하세요.
세 명의 엔지니어가 달라붙어야 유지되는 완벽하게 튜닝된 데이터베이스보다는, 약간 덜 최적화되었더라도 안정적으로 돌아가는 데이터베이스가 낫습니다. 이번 대량 Insert 이슈도 그랬습니다. 플래너의 통계 모델을 이해하기 전까진 난해했지만, 해결책은 복잡한 인프라가 아니라 ‘제때 통계 갱신하기’라는 단순한 원칙이었습니다.