서론
동일한 GPU 두 개를 같은 장비에 꽂고 똑같은 워크로드를 돌려보면, 종종 두 번째 GPU가 뒤처지는 현상을 보게 됩니다. 모델도 같고 드라이버도 같으며 데이터마저 동일한데 처리량(throughput)은 다르게 나타나는 것이죠. 발열 문제도 아니고 BIOS 프로파일 설정이 잘못된 것도 아닙니다. 사실 두 번째 GPU는 버스 수준에서 자원을 제대로 공급받지 못하고 있는 상태인데, 그 원인은 GPU 카드 자체가 아닌 다른 곳에 있습니다.
우리 대부분은 드라이버나 커널 모듈 위에서 작업하기 때문에 x86 시스템이 CPU, RAM, 그리고 PCIe 장치 간에 데이터를 실제로 어떻게 이동시키는지 들여다볼 일이 거의 없습니다. 하지만 처리량 비대칭 문제를 디버깅하거나, 인터럽트 선호도(interrupt affinity)를 튜닝하거나, 도대체 왜 irqaffinity가 중요한지 의문이 들기 시작하는 순간, 하드웨어 토폴로지는 더 이상 추상적인 개념으로 머물지 않게 됩니다.
이 글에서는 현대의 PCIe 트래픽을 처리하는 메커니즘인 제어용 MMIO와 대용량 데이터 전송용 DMA를 먼저 살펴봅니다. 이를 바탕으로 일반적인 소비자용 메인보드에서 왜 ‘두 번째 GPU’가 첫 번째 GPU보다 훨씬 낮은 대역폭으로 동작하게 되는지, 그리고 이 문제를 어떻게 해결할 수 있는지 상세히 알아보겠습니다.
x86 통신 채널의 이해
현대 x86 시스템은 구성 요소 간의 데이터 이동을 위해 주로 세 가지 통신 메커니즘을 사용합니다.
CPU-메모리 버스
CPU-메모리 버스는 프로세서와 RAM을 잇는 전용 연결 통로입니다. 현대의 CPU는 여러 개의 채널(플랫폼에 따라 보통 2~8개)을 가진 메모리 컨트롤러를 내장하고 있습니다. 예를 들어, 듀얼 채널 DDR4-3200 구성은 이론상 CPU에 51.2 GB/s의 대역폭을 제공합니다. 이 버스는 다른 장치와 공유하지 않는 전용 경로입니다.
PCIe: 포인트 투 포인트(Point-to-Point) 직렬 인터페이스
PCIe(Peripheral Component Interconnect Express)는 현대 x86 시스템의 혈관과 같습니다. GPU, NVMe SSD, 네트워크 카드 등이 데이터를 주고받는 주 통로죠. 모든 장치가 하나의 라인을 공유하며 순서를 기다려야 했던 구형 PCI 버스와 달리, PCIe는 각 장치에 고속 전용 레인(Lane)을 포인트 투 포인트로 연결해 줍니다. 한 슬롯의 트래픽이 다른 슬롯의 대역폭을 갉아먹지 않으며, 모든 링크는 전이중(Full-duplex) 방식으로 작동합니다.
이 모든 전용 레인은 결국 CPU 내부에 있는 게이트웨이인 루트 컴플렉스(Root Complex) 로 모입니다. 루트 컴플렉스는 PCIe 패브릭을 시스템 메모리와 연결하는 역할을 하죠. 모든 PCIe 장치는 이곳을 뿌리로 하는 트리 구조에 매달려 있습니다. 흔히 GPU가 “CPU에 직접 연결되었다"고 말할 때, 이는 중간 스위치 없이 루트 컴플렉스의 포트에 해당 슬롯이 배선되어 있다는 뜻입니다.
사양
PCIe 레인: PCIe 연결은 여러 개의 레인(x1, x4, x8, x16)으로 구성됩니다. 각 레인은 총 4개의 와이어(송신용 1쌍, 수신용 1쌍의 차동 쌍)로 이루어집니다. 레인 수가 많을수록 대역폭도 비례해서 늘어납니다.
- x1: 1개 레인
- x4: 4개 레인(4배 대역폭)
- x16: 16개 레인(16배 대역폭)
일반적으로 GPU는 x16을, NVMe SSD는 x4를 사용합니다. x4 카드는 x16 슬롯에도 장착할 수 있습니다.
PCIe 세대
세대별로 레인당 대역폭은 거의 두 배씩 증가합니다.
- PCIe 3.0: 레인당 ~1 GB/s (x4 = ~4 GB/s, x16 = ~16 GB/s)
- PCIe 4.0: 레인당 ~2 GB/s (x4 = ~8 GB/s, x16 = ~32 GB/s)
- PCIe 5.0: 레인당 ~4 GB/s (x4 = ~16 GB/s, x16 = ~64 GB/s)
이 수치는 128b/130b 인코딩 오버헤드(원시 비트 전송률에서 ~1.5% 감소)를 고려한 실제 처리량입니다. PCIe 4.0 x4 NVMe SSD가 8 GB/s를 낼 수 있는 반면, PCIe 3.0 x4는 4 GB/s가 한계인 이유입니다.
DMA: 직접 메모리 접근(Direct Memory Access)
DMA를 사용하면 CPU의 개입 없이도 장치가 RAM을 읽고 쓸 수 있습니다. CPU가 데이터를 바이트 단위로 복사하는 대신, 장치가 직접 메모리에 접근하는 방식입니다.
작동 과정은 다음과 같습니다.
- CPU가 장치에 “메모리 주소 0x12345000에 64KB를 써라"고 명령합니다.
- 장치가 PCIe 연결을 통해 물리 메모리에 직접 데이터를 씁니다.
- 작업이 끝나면 장치가 인터럽트(interrupt)를 통해 완료 신호를 보냅니다.
- CPU가 결과를 처리합니다.
CPU는 명령을 내리고 완료 처리를 할 뿐, 실제 데이터 전송은 하지 않습니다. 100GbE 네트워크 카드나 NVMe SSD처럼 초당 기가바이트 단위의 데이터를 옮기는 고성능 장치에겐 필수적입니다. DMA가 없다면 모든 패킷이나 디스크 블록을 복사하느라 CPU가 병목 현상의 주범이 되었을 겁니다.
장치 간 DMA(P2P, 예를 들어 NVMe에서 GPU VRAM으로 직접 전송하거나, 한 GPU가 다른 GPU에 쓰는 방식)도 원리적으로는 가능하며, 하드웨어 토폴로지가 허용하면 NCCL 같은 라이브러리가 이를 활용합니다. 하지만 이 글의 나머지 부분에서는 데이터가 시스템 RAM을 거쳐 가는 정석적인 경로를 중심으로 다룰 것입니다. 운영체제가 이를 선호하고, 대부분의 소비자용 플랫폼에서 강제하는 방식이기 때문입니다. 그 이유는 다음과 같습니다.
- 루트 컴플렉스의 경계: 데이터가 서로 다른 루트 컴플렉스 사이(예: NUMA 서버의 소켓 간)를 이동해야 한다면 하드웨어 아키텍처상 RAM을 거쳐야 할 수 있습니다. 단일 CPU 내부라도 여러 루트 컴플렉스가 존재할 수 있습니다.
- 운영체제 정책: 운영체제는 가시성과 리소스 관리 차원에서 데이터가 RAM을 통과하길 원합니다. SSD에서 읽은 데이터는 더 빠르게 재사용할 수 있도록 페이지 캐시(page cache) 에 머물며, 커널은 이 과정에서 무결성 검사를 수행할 수 있습니다. 윈도우는 ACS(Access Control Services) 를 통해 장치 간 직접 통신을 차단하는 경우가 많고, 리눅스는 IOMMU와 SWIOTLB(bounce buffers) 를 이용해 DMA가 실제 메모리에 닿기 전 검증 과정을 거칩니다.
이런 “유턴"의 실질적인 대가는 메모리 대역폭 경합입니다. SSD → RAM → GPU든 GPU → RAM → GPU든 데이터가 RAM을 우회하면 시스템 메모리 대역폭을 두 번 소비하게 됩니다. 결과적으로 CPU 작업과 우회하는 I/O 트래픽이 동일한 DDR 채널을 차지하려고 다투게 되어 전체 시스템 처리량이 떨어지게 됩니다.
이제 기본적인 통신 메커니즘을 알아봤으니, 다음으로는 장치들이 PCIe를 통해 연결되는 두 가지 주요 방식을 살펴보겠습니다.
직통 vs 우회: PCIe 연결 방식
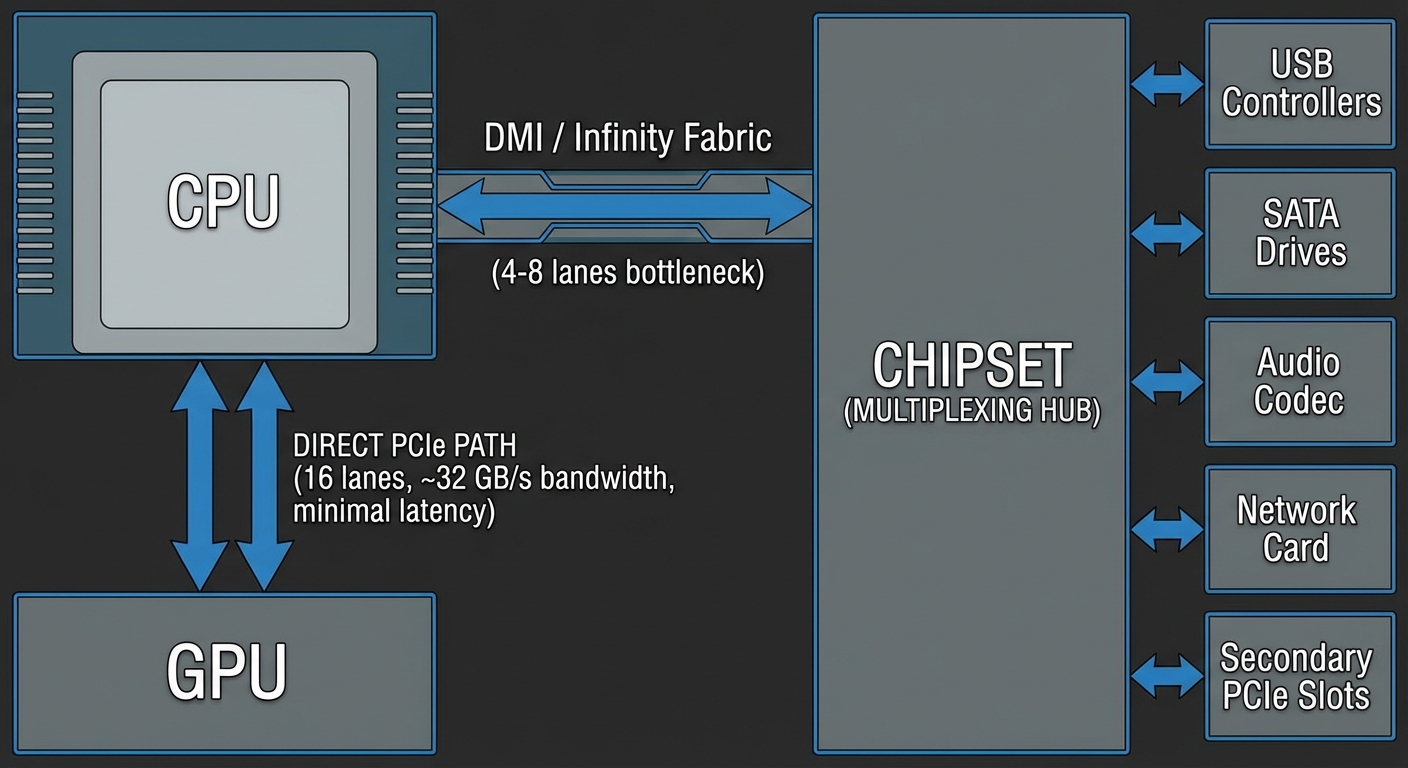
CPU 직통 연결 (CPU-Direct Connections)
메인스트림 플랫폼의 CPU는 1620개의 PCIe 레인을 소켓에 직접 연결합니다. 인텔의 경우 이 레인들은 CPU 다이(die)에서 직접 나오며, AMD 라이젠의 경우 컴퓨트 칩렛이 아닌 I/O 다이에서 나옵니다. HEDT나 워크스테이션 플랫폼은 이보다 훨씬 많은 레인을 제공하는데, 스레드리퍼(Threadripper)나 에픽(EPYC)은 48128개의 직통 레인을 제공하죠.
CPU 직통 연결은 병목 현상 없이 전체 대역폭을 온전히 제공합니다. PCIe 4.0 x16 연결은 방향당 ~31.5 GB/s의 대역폭을 제공합니다(전이중 방식 지원, 하지만 대부분의 작업에서 양방향 대역폭을 동시에 꽉 채우는 경우는 드뭅니다). 첫 번째 GPU를 첫 번째 PCIe x16 슬롯에 꽂는 이유는 이 직통 레인에 대한 독점적 권한을 보장하기 위해서입니다. 고급형 메인보드에서는 두 번째 x16 슬롯도 CPU 직통으로 연결되는 경우가 있습니다. PCIe 바이퍼케이션(Bifurcation) 기술을 사용하면 하나의 x16 연결을 x8/x8로 나눌 수 있는데, 각각 절반의 대역폭을 갖게 됩니다. 듀얼 GPU 환경에서도 GPU 작업이 PCIe 대역폭을 완전히 소모하는 일은 거의 없으므로, x8/x8 구성으로 인한 성능 저하는 보통 0~5% 정도로 미미한 수준입니다.
칩셋: 멀티플렉싱 허브 (Multiplexing Hub)
칩셋은 USB 컨트롤러(보통 10개 이상의 포트), SATA 드라이브, 오디오 코덱, 네트워크 인터페이스, 보조 PCIe 슬롯, 기타 레거시 I/O 장치 등 수많은 입출력 장치를 하나로 묶는 역할을 합니다.
칩셋은 전용 링크를 통해 CPU와 통신합니다. 인텔의 DMI 3.0은 ~4 GB/s를 제공하며(PCIe 3.0 x4와 유사한 대역폭이지만 칩셋 전용 프로토콜 최적화가 적용됨), DMI 4.0은 이를 두 배인 ~8 GB/s로 끌어올렸습니다. AMD의 칩셋 연결 방식은 플랫폼마다 다르지만, 일반적으로 중급형 보드에서 PCIe 4.0 x4를 사용하여 ~8 GB/s를 제공합니다.
칩셋에 연결된 모든 장치는 이 링크를 공유합니다.
왜 이런 아키텍처인가?
제조 원가는 I/O 복잡도와 비례합니다. 각 PCIe 레인은 SerDes(직렬/병렬 변환) 로직, PHY 레이어, CPU 패키지와 메인보드의 물리적 배선, 추가적인 핀 수를 필요로 합니다. 레인이 많아질수록 다이 면적은 커지고 수율은 떨어지죠. 100개의 직통 PCIe 레인을 가진 CPU를 만든다면 가격이 감당할 수 없을 만큼 비싸질 뿐만 아니라, 메인보드도 거대해져야 할 겁니다.
대부분의 I/O 장치는 동시에 최대 대역폭을 사용하지 않습니다. 1Gbps 네트워크 카드는 최대 가동 시 ~125 MB/s를 사용하고, USB 3.2 Gen 2 장치는 최대 ~1.2 GB/s, SATA SSD는 약 ~600 MB/s 정도를 씁니다. 이 장치들이 동시에 최대 대역폭을 점유하는 경우는 드뭅니다. 칩셋은 이러한 통계적 멀티플렉싱을 활용합니다. 가끔씩만 대역폭이 필요한 여러 장치를 하나로 묶어 처리하는 방식이죠. 실제 작업 환경에서도 칩셋의 평균 점유율은 10~30% 수준에 머뭅니다.
문제는 칩셋의 대역폭을 넘어설 때 발생합니다. 칩셋에 연결된 M.2 슬롯(보통 소비자용 보드에서 두 번째, 세 번째 슬롯. 첫 번째는 대개 CPU 직통입니다)끼리 파일을 복사하면서 동시에 영상 스트리밍과 다운로드를 수행하면 장치들이 대역폭을 두고 다투게 되고, 처리량은 비례해서 떨어집니다. DMI 링크가 병목이 되면서 전송 속도가 곤두박질치는 모습을 보게 될 겁니다.
이게 왜 중요한가: RAID 어레이를 칩셋 NVMe 슬롯에 구성하거나, SATA 드라이브 간 파일을 복사하면서 10GbE 전송을 수행하거나, 스토리지 작업 중에 고사양 USB 3.2 장치를 무겁게 사용하는 등 여러 개의 고대역폭 작업을 동시에 실행할 때 칩셋 대역폭이 한계에 도달합니다. 게임, 웹 서핑, 혹은 빠른 드라이브 하나를 쓰는 영상 편집 같은 단일 작업 흐름에서는 칩셋 제한에 도달할 일이 거의 없습니다. iostat을 확인했을 때 칩셋에 연결된 장치들의 총합 처리량이 7 GB/s를 넘어서기 시작한다면, 이미 한계점에 다다른 것입니다.
결론적으로, 반드시 높은 대역폭이 필요한 장치는 CPU 직통 레인을 사용합니다. 나머지는 모두 칩셋 링크를 공유하며, 총합 수요가 용량을 넘어서기 전까지는 이 방식이 매우 효율적으로 작동합니다.
현재에 이르기까지
이러한 구분은 처음부터 완성된 형태가 아니었습니다. 초기 PC는 거의 모든 주변기기를 칩셋으로 연결했는데, 당시에는 하드 드라이브나 기가비트 이더넷, USB 2.0 등이 공유 대역폭 안에서 충분히 원활하게 돌아갔기에 문제가 없었습니다. 상황이 변한 건 개별 장치 하나가 칩셋 전체가 감당할 수 있는 대역폭보다 더 많은 양을 요구하기 시작하면서부터입니다. NVMe SSD 하나만으로도 기존 칩셋의 한계를 넘어서고, 요즘의 x16 GPU는 차원이 다른 대역폭을 원하니까요. 칩셋 링크를 무작정 늘리는 대신, 실제 고대역폭이 필요한 장치(GPU 슬롯, 주력 NVMe)를 위해 CPU 직통 레인을 별도로 두고, 나머지는 공유 허브에 남겨두는 방식이 정착되었습니다. 이것이 오늘날 우리가 마주하고 있는 아키텍처입니다. 핵심 경로(Hot path)를 위한 소수의 CPU 직통 레인과, 나머지를 모두 받아내는 칩셋 업링크의 공존인 셈이죠.
칩셋 병목 현상 (Chipset Bottleneck)
칩셋에 연결된 모든 장치—두 번째 GPU, NVMe 드라이브, USB 컨트롤러, 이더넷, SATA 포트 등은 CPU로 가는 단일 업링크(uplink)를 공유합니다.
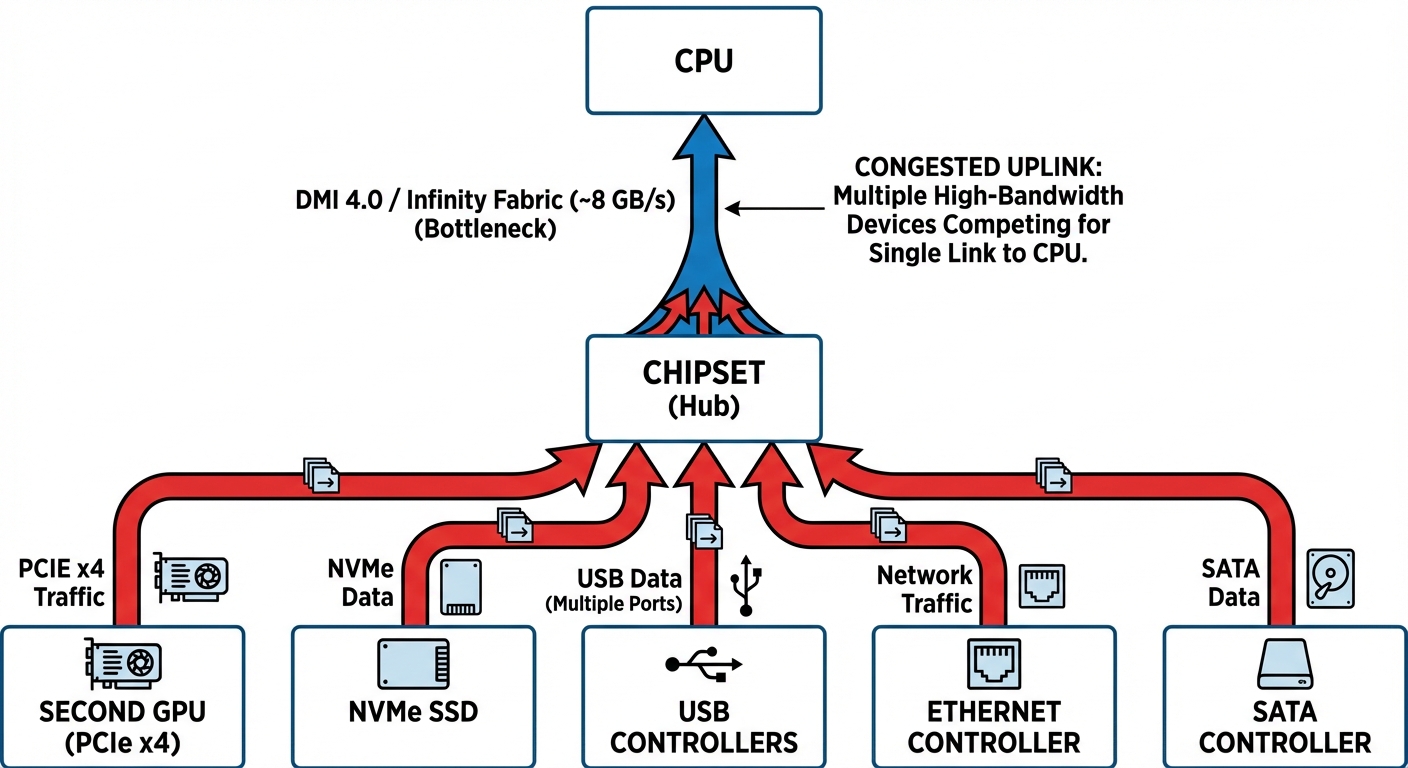
이 업링크 자체는 일종의 PCIe 링크(인텔은 DMI, AMD는 전용 PCIe 링크라고 부름)인데, 보통 PCIe 4.0 x4에서 x8 정도의 대역폭, 즉 양방향으로 ~8–16 GB/s 수준입니다. 이 숫자가 바로 칩셋에 붙은 모든 장치가 공유하는 최대 한계치입니다. 만약 두 번째 GPU가 칩셋 뒤에 있다면, 이 GPU는 NVMe, USB, SATA, 온보드 NIC와 같은 통로를 두고 경쟁해야 하는 셈이죠.
AI 학습에서 이 문제가 치명적인 이유
게임은 PCIe 트래픽이 간헐적입니다. GPU가 장면 데이터를 로드하고 내부적으로 프레임을 렌더링한 뒤, 완성된 프레임을 다시 보내는 식이죠. 반면, AI 학습은 지속적으로 높은 대역폭을 소모합니다. 데이터셋이 스토리지에서 RAM으로 스트리밍되고, 배치(batch) 데이터가 GPU 메모리로 이동하며, 기울기(gradient)나 체크포인트가 저장되기 위해 다시 흐릅니다.
두 번째 GPU와 NVMe 드라이브가 모두 칩셋에 연결되어 있다면, 최악의 경우 데이터 흐름은 다음과 같습니다.
장치 → 칩셋 → DMI → CPU → RAM → CPU → DMI → 칩셋 → 장치
모든 구간이 동일한 업링크를 두고 싸워야 하며, RAM 구간은 메모리 대역폭을 두 번이나 잡아먹게 됩니다.
GPU 레인 vs 칩셋 대역폭
칩셋에 연결된 GPU는 보통 x4 모드로 작동하는데, PCIe 4.0 기준으로 양방향 약 8 GB/s 수준입니다. GPU의 x4 레인이 먼저 병목이 될지, 칩셋 업링크가 먼저 포화될지는 어떤 쪽이 더 좁으냐에 달려 있습니다. 업링크가 좁으면(x4) 디스크 읽기와 GPU 전송이 겹치는 순간 대역폭이 바닥납니다. 업링크가 좀 더 넓으면(x8) 적당한 I/O 부하 상황에서는 GPU의 x4 링크 자체가 제한 요소가 됩니다. 어느 쪽이든 두 번째 GPU가 손해를 보는 구조입니다.
이중 페널티 (업로드 + 다운로드)
양방향 통신 모두 같은 업링크를 통과합니다.
업로드 (CPU → GPU): 학습 배치 데이터가 RAM → 칩셋 → GPU로 이동하는 동안, NVMe 읽기 작업이 동시에 스토리지 → 칩셋 → RAM으로 밀고 들어옵니다.
다운로드 (GPU → CPU): 기울기와 체크포인트가 GPU → 칩셋 → RAM으로 넘어가고, 이어서 체크포인트를 저장하기 위해 RAM → 칩셋 → 스토리지로 데이터가 나갑니다.
만약 NVMe 드라이브까지 칩셋에 물려 있다면(일반적인 데스크탑 구성이죠), 스토리지 읽기, GPU 데이터 전송, 그리고 기타 칩셋 I/O(USB, SATA, 일부 NIC)가 모두 그 ~8-16 GB/s 대역폭을 두고 치열하게 경쟁합니다. CPU에 직접 연결된 GPU는 이 문제를 완전히 피할 수 있습니다. 스토리지 읽기만 칩셋을 거치고, GPU 데이터는 전용 CPU 레인을 타고 이동하기 때문입니다.
프리페칭(Prefetching)이 이 문제를 완화해 줍니다. PyTorch 같은 최신 프레임워크는 GPU가 연산하는 동안 다음 배치 데이터를 미리 RAM으로 가져오는 멀티 프로세스 데이터 로더를 사용합니다. 프리페치 워커가 충분하고 RAM 속도가 빠르다면 I/O가 연산과 겹치면서 병목이 상쇄됩니다. 칩셋 연결 GPU가 대역폭 계산상으로 예상되는 수치보다 실제 성능이 잘 나오는 이유가 바로 이것입니다.
기본 NVMe 드라이브를 CPU 직결 M.2 슬롯에 꽂는 것도 도움이 됩니다. 이렇게 하면 스토리지 트래픽이 칩셋 경쟁에서 완전히 빠지게 되거든요. 두 번째 GPU가 여전히 공유 허브를 거쳐 x4로 작동하더라도, 최소한 디스크 읽기 작업과 대역폭을 나눠 가질 일은 없어집니다.
추론(Inference)에서는 왜 상관없을까?
추론은 I/O를 거의 쓰지 않습니다. 모델을 한 번 로드하면 끝이고, 입력 데이터도 수 KB에서 수 MB 정도로(수 GB에 달하는 학습 배치와 비교하면 매우 작죠) 작으며, 역전파(backward pass)도 없습니다. 연산이 지배적인 작업에서는 대역폭이 거의 중요하지 않습니다. 1 MB짜리 추론 입력 데이터는 8 GB/s 환경에서 0.125ms 만에 전송되는데, 이는 추론 연산 시간에 비하면 무시할 수 있는 수준입니다.
모든 학습 작업이 I/O 바운드(I/O-bound)인 것도 아닙니다. 데이터셋이 첫 번째 에폭(epoch) 이후 RAM에 전부 올라가 있거나, 모델의 연산 대비 데이터 비율이 높거나(데이터는 적고 연산은 많은 대형 트랜스포머 등), 혼합 정밀도(mixed precision)를 사용한다면 칩셋 위치로 인한 성능 저하는 거의 체감되지 않습니다. 진짜 고통스러운 건 대역폭을 많이 타는 작업들입니다. 고해상도 비전 모델, 영상 파이프라인, 지속적으로 스트리밍되는 데이터셋, 빈번한 체크포인트 저장이 필요한 모델들이죠. 바로 그런 상황에서 여러분의 두 번째 GPU가 “게으르다(lazy)“는 소리를 듣게 되는 겁니다.
실전에서의 레인 할당
두 번째 GPU가 칩셋을 거치는지 여부는 전적으로 메인보드 설계에 달려 있습니다. 일반적인 데스크탑 CPU는 CPU와 직접 연결되는 고정된 PCIe 레인 예산을 가집니다. 보통 그래픽카드용으로 16레인, NVMe용으로 몇 개, 그리고 칩셋과 연결되는 좁은 업링크용 레인이 할당되죠. 세부적인 개수나 세대는 출시 때마다 바뀌지만, 구조는 늘 비슷합니다. 즉, CPU 직결 레인이라는 한정된 프리미엄 자원과, 그 뒤에 배치된 칩셋 공유 레인이라는 넓은 자원으로 나뉘는 셈입니다.
칩셋을 통해 레인을 늘릴 수는 있지만, 칩셋에 연결된 모든 장치는 CPU와 연결된 단 하나의 링크를 통해 대역폭을 나눠 써야 합니다. CPU 직결 레인은 전용 대역폭을 제공하는 반면, 칩셋 레인은 공용 파이프를 공유하는 구조죠.
주요 대역폭 수치 (방향당):
- PCIe 3.0 x8: ~7.88 GB/s
- PCIe 4.0 x8: ~15.75 GB/s
- PCIe 5.0 x8: ~31.5 GB/s
PCIe 3.0 x16은 PCIe 4.0 x8과 같은 대역폭(~15.75 GB/s)을 제공합니다. 따라서 레인 개수만큼이나 세대(Generation)도 중요합니다. x4로 동작하는 GPU는 같은 세대의 x16으로 동작하는 GPU보다 대역폭이 4배 적으며, 칩셋을 통해 연결된 GPU는 거의 항상 x4 속도로 제한됩니다.
바이퍼케이션(Bifurcation): x16 슬롯 하나를 둘로 쪼개기
CPU의 16개 그래픽 레인은 물리적으로 하나의 블록입니다. 기본적으로 보드는 이 16개를 모두 첫 번째 PCIe 슬롯에 몰아줍니다. 바이퍼케이션(Bifurcation) 은 이 블록을 전기적으로 쪼개는 기술입니다. 가장 흔히 x8/x8로 나누어, 두 번째 물리 슬롯이 칩셋을 거치지 않고 CPU 직결 레인 8개를 직접 가져다 쓰게 하죠. 이를 위해서는 CPU 지원(최신 데스크탑 CPU는 지원함)과 보드 펌웨어 지원(제조사가 실제로 슬롯을 적절한 레인에 배선하고 BIOS 옵션을 노출해야 함)이 모두 필요합니다.
바이퍼케이션이 없으면 첫 번째 슬롯이 CPU 레인 16개를 독점하고, 두 번째 x16 슬롯은 칩셋의 x4 레인으로 밀려납니다. 앞서 말한 칩셋 병목 현상이 여기서 발생하죠. 바이퍼케이션을 사용하면 두 GPU 모두 CPU와 x8로 직접 연결됩니다.
주의할 점은, 바이퍼케이션을 활성화하면 PCIe 세대가 한 단계 낮아지는 보드가 있다는 것입니다 (예: Gen 4 x16이 Gen 3 x8/x8이 되는 경우). 반드시 매뉴얼을 확인하세요.
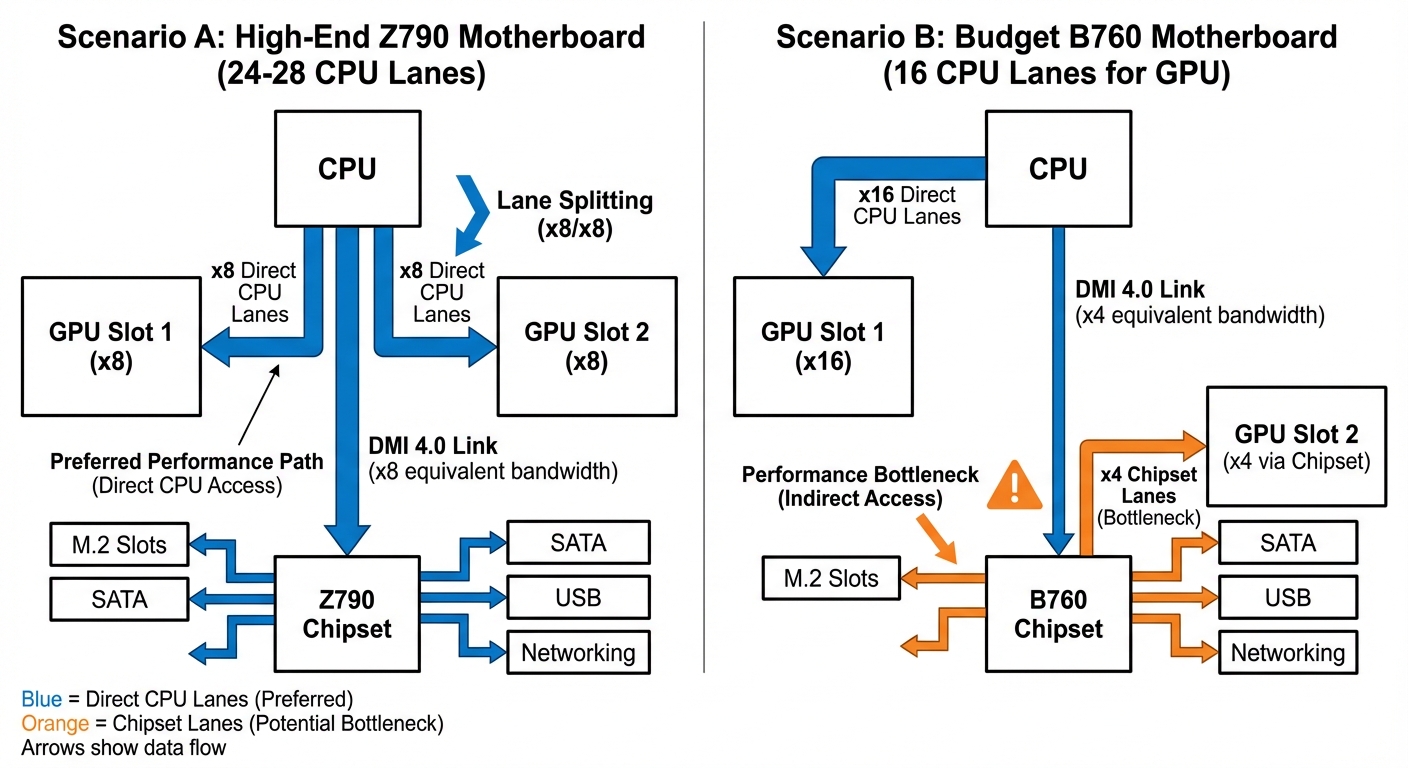
하이엔드 vs 보급형 칩셋 등급
이 패턴은 인텔과 AMD 모두, 그리고 모든 세대에서 동일합니다.
하이엔드 칩셋(각 제조사의 플래그십 등급) 은 대체로 바이퍼케이션을 지원하며, 최신 PCIe 세대의 칩셋 레인을 더 많이 제공합니다. 보통 CPU 직결 레인을 활용한 듀얼 GPU x8/x8 구성이 가능합니다.
보급형 칩셋 은 바이퍼케이션 지원 여부가 제품마다 다릅니다. 같은 칩셋 등급이라도 보드 제조사 판단에 따라 결정되기 때문입니다. 칩셋 레인은 CPU 레인보다 한 세대 뒤처지는 경우도 많습니다. 바이퍼케이션을 지원하지 않으면, 두 번째 슬롯은 무조건 칩셋 x4 레인으로 고정됩니다.
제조사의 마케팅 용어는 세대마다 바뀌지만, 의사 결정 구조는 변하지 않습니다. 사용 중인 보드의 PCIe 블록 다이어그램을 찾아 확인해 보세요. 두 번째 x16 슬롯이 (바이퍼케이션을 통해) CPU로 향하는지, 아니면 칩셋으로 연결되는지 말이죠.
시나리오 A: 바이퍼케이션 사용 시
- GPU 1: CPU 직결 x8 레인
- GPU 2: CPU 직결 x8 레인
- M.2 슬롯: 전용 CPU 레인 또는 칩셋 레인 사용
두 GPU가 서로 다른 배치를 병렬로 처리하는 멀티 GPU AI 작업 환경에서는 x8 대역폭으로도 충분합니다. 병목 현상은 GPU 간에 잦은 동기화가 필요하거나, 기기 간에 거대한 모델 데이터를 전송해야 할 때 발생합니다. 각 GPU가 독립적인 데이터를 처리하는 일반적인 추론이나 학습 환경에서는 드문 일이죠.
시나리오 B: 바이퍼케이션 미사용 시
- GPU 1: CPU 직결 x16 레인
- GPU 2: 칩셋을 통한 x4 레인 (대역폭 공유)
칩셋 업링크(~8–16 GB/s, 플랫폼에 따라 다름)는 SATA 드라이브, USB 컨트롤러, 네트워크 어댑터, 추가 M.2 슬롯, 그리고 두 번째 GPU까지 모든 칩셋 연결 장치가 공유합니다. 입출력(I/O)이 동시에 몰리는 상황에서는 두 번째 GPU가 이름뿐인 x4 대역폭의 일부만 가져가게 될 수도 있습니다.
레인 재할당 옵션
일부 메인보드는 M.2 슬롯을 희생하여 GPU 연결성을 확보할 수 있게 해줍니다. BIOS에서 특정 M.2 슬롯을 비활성화하면 해당 CPU 레인을 두 번째 PCIe 슬롯으로 재할당하여, 칩셋 x4 레인을 CPU 직결 x4 레인으로 업그레이드할 수도 있습니다. 메인보드 매뉴얼의 PCIe 구성 표를 보면 어떤 슬롯이 레인을 공유하는지, 어떤 재할당 옵션이 있는지 알 수 있습니다. BIOS 설정에서 “PCIe Slot Configuration”, “M.2/PCIe Sharing”, 또는 “Bifurcation Mode” 같은 항목을 찾아보세요. 보급형 보드는 사용자 설정 없이 하드웨어적으로 고정된 경우가 많습니다.
비대칭 GPU 구성
비대칭 구성(예: RTX 4090 + RTX 3060)을 사용한다면, 더 강력한 GPU에 x16 레인을 모두 할당하세요. 작은 모델의 추론이나 영상 인코딩 같은 보조적인 작업을 담당하는 낮은 성능의 카드는 대역폭 손실이 상대적으로 덜 중요하기 때문입니다.
현재 구성 확인하기
메인보드 매뉴얼에서 PCIe 구성 표와 CPU/칩셋 라우팅 다이어그램을 확인하세요. “Slot 2는 x4로 작동하며 M.2_3과 대역폭을 공유함"과 같은 메모가 있는지 살펴보는 것이 좋습니다.
실제 실행 중인 시스템의 구성을 확인하려면 GPU-Z나 HWiNFO를 사용하세요. 링크 폭(x8/x16)과 PCIe 세대(3.0/4.0/5.0)를 모두 확인해야 합니다. BIOS 설정이 항상 실제 협상된(negotiated) 속도를 보장하지는 않기 때문입니다.
레인 할당은 각 GPU가 가질 수 있는 이론적 최대 대역폭을 결정합니다. CPU 직결 x8 레인과 공유 칩셋 x4 레인의 차이는 멀티 GPU AI 작업에서 분명히 측정 가능한 수준이지만, 본인의 작업 환경에서 그 차이가 얼마나 중요한지는 직접 따져봐야 할 문제입니다.
균형 잡기의 미학: 무조건 나누는 게 정답은 아니다
PCIe 레인을 x8/x8로 나누어 두 개의 GPU에 할당하면 각각의 대역폭은 줄어들 수밖에 없습니다. 이는 작업 부하가 실행되는 동안 PCIe 사용률을 지속적으로 70~80% 이상 점유할 때 문제가 됩니다. (간헐적인 스파이크 정도는 보통 괜찮습니다.)
분산보다 집중이 나을 때
데이터 로딩 중에 PCIe 대역폭을 꽉 채우는 딥러닝 학습 작업은 레인을 나누는 순간 대역폭 제한(bandwidth-constrained)에 걸리게 됩니다.
- 두 개의 x8 GPU (PCIe 3.0): 각각 방향당 ~7.88 GB/s를 가져가므로 둘 다 최적보다 느리게 학습됩니다.
- 하나의 x16 GPU (PCIe 3.0): 방향당 ~15.75 GB/s를 확보하여 최대 처리량으로 학습합니다.
- 두 개의 x8 GPU (PCIe 4.0): 각각 방향당 ~15.75 GB/s를 확보하므로 보통 충분합니다.
PCIe 세대가 중요합니다. x8 Gen4 링크는 x16 Gen3와 동일한 대역폭을 제공하므로, 최신 플랫폼에서는 x8/x8로 나누는 것이 훨씬 덜 골칫거리입니다.
GPU 간 병렬 처리가 되지 않는 단일 학습 작업이라면, x16 GPU 하나가 두 개의 x8 GPU 중 하나에서 학습하는 것보다 더 빨리 끝날 수 있습니다. 만약 대역폭 제한 때문에 각 GPU가 최적 속도의 60%밖에 내지 못한다면, 두 개의 GPU를 써도 1.2배 정도의 처리량밖에 안 나오게 됩니다. 하나를 썼을 때보다는 낫지만, 두 개 값을 지불하고도 2배의 효율을 얻지 못한 셈이죠. 이 손해가 감당할 수준인지는 두 카드를 모두 채울 만큼 병렬 작업이 있느냐에 달려 있습니다.
크고 작은 전략 (Big & Small Strategy)
혼합 워크로드를 운영한다면 비대칭 구성을 고려해 보세요.
큰 GPU (슬롯 1, x16): 학습이나 연산 집약적인 작업을 위한 고성능 카드 작은 GPU (슬롯 2, x8 또는 x4): 디스플레이 출력, 비디오 인코딩, 가벼운 추론을 위한 저가형 카드 (GTX 1650 등)
주 작업은 대역폭을 온전히 누리고, 보조 GPU는 데스크톱 컴포지팅이나 주피터 노트북, 다중 모니터 출력 등을 담당하게 됩니다. 요즘 GPU는 데스크톱 컴포지팅을 가볍게 처리하지만, 카드를 분리하면 VRAM 파편화를 방지하고 메인 GPU의 메모리 전체를 오롯이 학습에 집중시킬 수 있습니다.
치명적인 제약 사항: 많은 소비자용 메인보드는 슬롯 2를 채우는 순간 슬롯 1을 x8로 강등시킵니다. 물론 하이엔드 칩셋(X570, Z690 이상)은 x16 + x4를 지원하기도 하죠. x16 + x8을 동시에 쓰려면 HEDT 플랫폼(스레드리퍼, 제온 W)이 필요합니다. 반드시 매뉴얼에서 본인 보드의 PCIe 토폴로지를 확인하세요.
언제 나누고, 언제 피할 것인가
레인을 분배하기 전, 다음을 체크해 보세요.
x8/x8이 합리적인 경우:
- 모델이 VRAM 안에 완전히 들어오고, 호스트와의 데이터 이동이 최소화된 경우
- 데이터 로딩이 아닌 GPU 연산 자체가 병목인 추론 서버
- 동기화가 거의 발생하지 않는 순수 연산 작업
- x8만으로도 충분한 대역폭을 제공하는 PCIe 4.0 또는 5.0 시스템
x16(또는 x16 + x4)이 합리적인 경우:
- 호스트와 디바이스 간 데이터 이동이 잦은 대형 모델 학습
- 시스템 RAM에서 데이터를 지속적으로 스트리밍해야 하는 고해상도 이미지 처리
- Pin-memory를 사용하지 않는 작업 (PyTorch DataLoader의
pin_memory설정을 확인하세요. 설정하지 않으면 전송 속도가 눈에 띄게 느려집니다.) - 대역폭에 민감한 워크로드를 돌리는 PCIe 3.0 시스템
실제 워크로드 수행 중 nvidia-smi dmon -s pcie 명령어나 Nsight Systems 같은 프로파일링 도구를 사용해 PCIe 사용량을 측정해 보세요. “대역폭이 병목일 거야"라고 지레짐작하기 전에 링크 처리량 수치를 먼저 확인하는 것이 좋습니다.
병목 구간 진단하기
I/O 병목 현상을 최적화하기 전에, 정말로 I/O가 문제의 원인인지 먼저 확인해야 합니다.
GPU 토폴로지 확인
하드웨어 구성이 어떻게 되어 있는지 확인해 보세요.
nvidia-smi topo -m # GPU 토폴로지와 연결 유형 표시
확인할 수 있는 연결 유형은 다음과 같습니다.
NVLink: GPU 간 직접 연결 (가장 이상적)PHB: 동일한 PCIe 호스트 브릿지 (좋음)PIX: PCIe 스위치 연결 (허용 가능한 수준)SYS: 서로 다른 CPU 소켓 간 통신 (가장 느림)
만약 GPU 1은 SYS 연결인데 GPU 0은 PHB 연결이라면, 토폴로지가 비대칭 상태인 겁니다. CPU나 PCIe 루트 콤플렉스에 더 가까운 GPU(일반적으로 GPU 0)는 시스템 메모리와 스토리지에 더 낮은 지연 시간으로 접근하는 반면, 두 번째 GPU는 더 많은 PCIe 홉을 거쳐야 하기 때문이죠.
실시간 PCIe 대역폭 모니터링
학습 중 PCIe 트래픽을 관찰해 보세요.
nvidia-smi dmon -s pucvmet # p=전력, u=사용률, c=클럭, v=전압, m=메모리, e=인코더, t=온도
PCIe 처리량(MB/s 단위)을 보여주는 pcie_tx와 pcie_rx 열에 집중하세요.
학습 중에 다음 상황이 발생하는지 지켜봐야 합니다.
- PCIe 3.0 x16 환경에서 PCIe rx 대역폭이 ~12-14 GB/s에 도달: 이론상 최대치는 15.75 GB/s이지만, 프로토콜 오버헤드 때문에 실제 사용 가능한 대역폭은 약 80% 수준으로 줄어듭니다.
- 대역폭이 포화될 때 GPU 사용률(sm)이 60-80%로 하락: I/O 처리가 GPU 연산을 따라가지 못하고 있다는 신호입니다.
- 비대칭 패턴: GPU 0은 95% 사용률을 유지하는데 GPU 1은 50-90% 사이에서 요동치는 경우.
GPU별 학습 처리량 비교
각 GPU의 초당 샘플 처리 수(samples/second)를 측정하세요. DDP 학습에서는 rank를 사용하여 GPU를 식별할 수 있습니다.
import time
import torch.distributed as dist
from collections import defaultdict
throughput_stats = defaultdict(list)
for batch in dataloader:
start = time.perf_counter()
# ... 학습 단계 ...
elapsed = time.perf_counter() - start
samples_per_sec = batch_size / elapsed
gpu_id = dist.get_rank() # DDP에서 rank는 GPU와 대응됩니다
throughput_stats[gpu_id].append(samples_per_sec)
만약 GPU 1이 GPU 0보다 항상 20-30% 적은 샘플을 처리한다면, 데이터 전달이 불균형하게 이루어지고 있다는 뜻입니다.
P2P 대역폭 테스트 수행
실제 GPU 간 전송 속도를 측정해 보세요.
import torch
size = 1024 * 1024 * 1024 # 1GB
iters = 20
src, dst = 'cuda:0', 'cuda:1'
x = torch.empty(size, dtype=torch.uint8, device=src)
start, end = torch.cuda.Event(enable_timing=True), torch.cuda.Event(enable_timing=True)
# 워밍업 및 동기화
for _ in range(5): x.to(dst)
torch.cuda.synchronize(src); torch.cuda.synchronize(dst)
# 벤치마크
start.record()
for _ in range(iters): x.to(dst)
end.record()
torch.cuda.synchronize(dst)
# 결과 (GB/s)
avg_ms = start.elapsed_time(end) / iters
gbps = (size / (avg_ms / 1000)) / 1e9
print(f"P2P Bandwidth: {gbps:.2f} GB/s")
기대 대역폭은 다음과 같습니다.
- NVLink: 링크당 25-50 GB/s (V100, A100 등)
- PCIe 3.0 x16: 단방향 12-14 GB/s
- PCIe 4.0 x16: 단방향 24-28 GB/s
이보다 현저히 낮게 나온다면, 병목이 발생했거나 설정이 잘못된 상태입니다.
데이터 로딩 단계의 성능 하락 관찰
데이터 로딩 중에 GPU 사용률이 급락한다면 I/O 기아(starvation) 상태일 가능성이 높습니다. nvidia-smi dmon을 실행하고 sm(스트리밍 멀티프로세서) 사용률을 확인해 보세요.
# GPU 0: 98% -> 95% -> 97% -> 96% (안정적)
# GPU 1: 92% -> 65% -> 88% -> 58% (I/O 발생 시 하락)
GPU 1은 데이터를 기다리고 있는데, GPU 0이 공유 I/O 경로에 우선권을 가지고 있는 상황입니다.
주요 점검 항목(Red Flags) 요약
다음 상황 중 하나라도 해당한다면(임계치는 작업 부하에 따라 다를 수 있습니다) I/O 병목이 발생한 것입니다.
- PCIe 대역폭이 지속적으로 포화 상태임 (이론상 최대치의 90% 초과)
- 학습 중 GPU 1의 사용률이 GPU 0보다 15-30% 낮게 유지됨
- GPU별 처리량(throughput)에서 20% 이상의 비대칭 발생
- P2P 대역폭 테스트에서 예상보다 훨씬 낮은 GPU 간 속도 측정
nvidia-smi dmon상에서 PCIerx포화 시sm사용률이 동반 하락함
병목 현상을 확인했고 더 높은 성능이 필요하다면, 이제 조금 더 극단적인 해결책을 고민해 볼 차례입니다.
HEDT 및 그 이상
데스크탑 플랫폼은 3~4개의 GPU 구성을 병목 시킵니다. Ryzen 9 7950X는 CPU에서 24개의 PCIe 5.0 레인을 제공하며, Intel Core i9-13900K/14900K는 20개의 레인(16 PCIe 5.0 + 4 PCIe 4.0)을 제공합니다. 칩셋이 레인을 추가해 주긴 하지만, 이들은 CPU와 공유 업링크로 연결되기 때문에 CPU 직결 레인과 같은 대역폭 특성을 갖지 못합니다. 대역폭 분할 문제는 차치하더라도, 일반적인 데스크탑 메인보드는 물리적으로 4개의 듀얼 슬롯 GPU를 장착하기 어렵고, 네 번째 슬롯은 보통 M.2나 다른 주변 장치와 레인을 공유합니다.
PCIe 5.0 x8은 PCIe 4.0 x16과 동일한 대역폭(~32 GB/s 양방향)을 제공하므로, 24레인 PCIe 5.0 CPU는 이론적으로 3개의 GPU를 PCIe 4.0 풀 대역폭 수준으로 돌릴 수 있습니다. GPU가 PCIe 5.0을 지원하는 3-GPU 구성이라면 가능하죠. 하지만 대부분의 워크스테이션용 GPU(A5000, A6000)나 현세대 소비자용 카드는 여전히 PCIe 4.0을 사용하며, 물리적인 슬롯 제한 문제도 여전합니다. 4개 이상의 GPU를 쓰려면 레인이 더 많은 플랫폼으로 넘어가는 게 확실한 해답입니다.
HEDT(High-End Desktop) 및 서버 플랫폼은 CPU에서 직접 뽑아내는 PCIe 레인 수가 압도적으로 많습니다.
CPU 직결 PCIe 레인:
- 메인스트림 데스크탑 (Ryzen 9 7950X): 24 레인 PCIe 5.0
- 메인스트림 데스크탑 (Core i9-13900K): 20 레인 (16 Gen5 + 4 Gen4)
- Threadripper Pro 5000WX: 128 레인 PCIe 4.0
- EPYC 7003/9004: 128 레인 PCIe 4.0/5.0 (싱글 소켓)
- Xeon-W 3400: 64 레인 PCIe 5.0
Threadripper Pro나 EPYC을 쓰면 4개의 GPU를 x16 풀 대역폭으로 구동(64 레인)하고도 NVMe, 네트워킹, 확장 카드를 위한 레인이 48개 이상 남습니다. 또한 HEDT 플랫폼은 대부분의 슬롯에서 PCIe bifurcation(분기)을 지원하여 일반 데스크탑 보드에서는 불가능한 유연한 구성을 할 수 있습니다.
참고로, EPYC/Threadripper Pro의 128개 레인 모두를 확장 카드에 쓸 수 있는 건 아닙니다. 칩셋 연결, BMC, 온보드 장치들을 위해 일부 레인을 예약해 두거든요. 실제 확장 카드를 위해 가용한 레인은 96~112개 정도로 생각하는 게 좋습니다.
또한 HEDT 플랫폼은 쿼드 채널(Threadripper Pro) 또는 옥타 채널(EPYC) 메모리 대역폭을 제공하는데, 이는 시스템 RAM과 GPU 메모리 사이에서 대용량 데이터를 옮겨야 하는 워크로드에서 매우 중요한 요소입니다.
플랫폼 투자가 빛을 발하는 순간
고성능 GPU 하나당 보통 $1,600~$2,000(RTX 4090, A5000급) 정도 합니다. 4개면 $6,400~$8,000이죠. 여기에 CPU($1,500~$5,000+), TRX50 메인보드($800~$1,200), 쿼드 채널 ECC 메모리 비용까지 고려하면 Threadripper Pro 워크스테이션은 일반 데스크탑보다 $3,000~$6,000 이상 비싸집니다.
만약 데이터 병렬 ML 학습, 멀티 GPU 렌더링, 병렬 시뮬레이션처럼 여러 GPU를 동시에 꽉 채워 쓰는 워크로드를 돌린다면, GPU 활용도를 극대화하기 위해 이 정도 플랫폼 투자를 하는 건 충분히 가치 있는 일입니다. 하지만 한 번에 GPU 집약적인 작업을 하나만 돌리거나, 2개까지만 확장해도 충분한 워크로드라면 일반 데스크탑 플랫폼을 유지하세요. HEDT는 CPU 코어나 메모리가 아니라, ‘GPU 활용도’가 병목이 되는 시나리오를 위한 것입니다.
PCIe 그 너머: NCCL, NVLink, GPUDirect Storage
충분한 레인을 확보했다면, 그다음 대역폭 개선은 “데이터는 무조건 RAM을 거쳐야 한다"는 기본 규칙을 깨는 것에서 시작합니다. 리눅스 환경에서 NCCL(NVIDIA Collective Communications Library) 은 시스템 토폴로지를 매핑합니다. 단순히 GPU가 어떤 CPU에 달려 있는지만 보는 게 아니라, 그 CPU 내부의 어느 Root Complex에 속해 있는지까지 파악해서 하드웨어가 허용하는 한 GPU 간의 P2P DMA 경로를 엽니다. NCCL이 P2P를 사용할 수 있게 되면 그라디언트 동기화가 더 이상 RAM을 경유하지 않게 되고, 앞서 언급한 메모리 대역폭 경합 문제도 사라집니다.
하지만 결국 PCIe라는 한계는 남습니다. NVLink는 PCIe를 완전히 건너뛰는 NVIDIA의 GPU 간 직접 상호 연결 기술입니다. H100은 18개의 링크를 통해 총 900 GB/s에 달하는 NVLink 대역폭을 내는데, PCIe 5.0 x16의 ~63 GB/s와는 차원이 다르죠. NCCL은 NVLink를 감지하면 PCIe 토폴로지를 보는 것을 중단하고 전용 링크를 통해 트래픽을 라우팅합니다. NVLink는 연결된 GPU 간 캐시 일관성 메모리 액세스도 지원하는데, 원격 VRAM에 접근할 때 로컬보다는 느리지만 시스템 RAM을 거치는 것보다는 훨씬 빠른 NUMA 영역처럼 동작합니다.
토폴로지는 여전히 중요합니다. NVLink는 포인트 투 포인트 방식이라 모든 GPU 쌍이 직접 연결되지는 않거든요. 이를 해결하는 게 스위치 패브릭인 NVSwitch입니다. NVIDIA DGX H100에서는 4개의 NVSwitch가 8개 GPU 모두에 블로킹 없는 올 투 올(all-to-all) NVLink 대역폭을 제공하죠. AMD의 Infinity Fabric과 Intel의 Xe Link도 각자의 생태계에서 비슷한 역할을 합니다. NVIDIA GPU의 경우, 성숙한 소프트웨어 스택을 갖춘 유일한 옵션은 NVLink입니다.
스토리지에도 이와 유사한 우회 경로가 있습니다. 전통적인 경로는 다음과 같습니다.
스토리지 → RAM → CPU (bounce buffer) → GPU
GPUDirect Storage(GDS) 는 이를 다음과 같이 단축합니다.
스토리지 → GPU (DMA 사용)
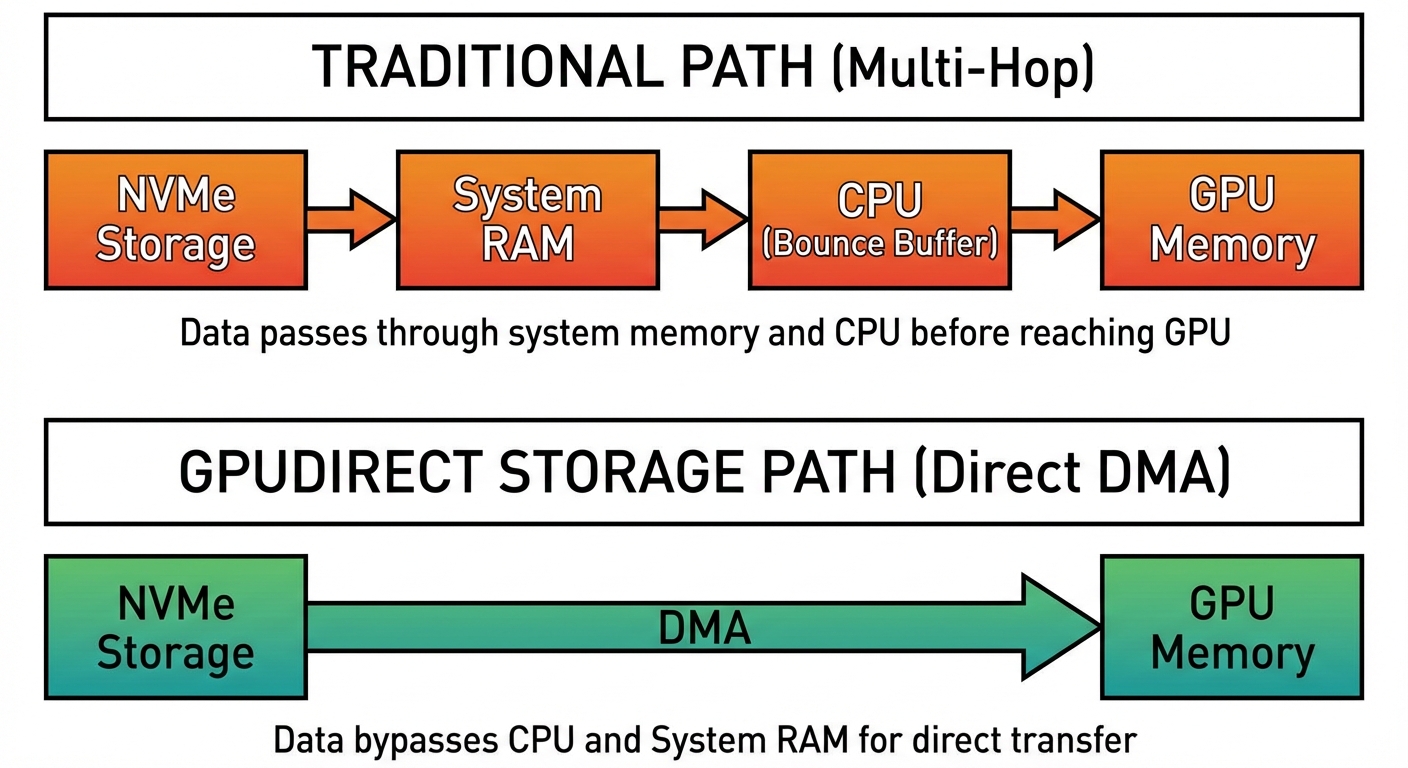
GDS가 작동하려면 NVMe 컨트롤러가 GPU BAR 메모리에 직접 DMA를 쏠 수 있도록 PCIe 피어 투 피어(peer-to-peer) 지원이 필요합니다. 모든 컨트롤러와 BIOS가 허용하는 건 아니기에, 실제로는 데이터 센터급 기능이라 볼 수 있습니다. 제대로 세팅되면 더 높은 대역폭(CPU/메모리 병목 없음), 더 낮은 지연 시간(두 번 옮길 걸 한 번으로 끝냄), 그리고 전처리 및 스케줄링을 위해 해방된 CPU 자원을 얻을 수 있습니다.
이런 기술들은 대역폭 스펙트럼의 끝단에 있는 기법들입니다. 대부분의 데스크탑 환경에서는 과할지 모르지만, “데이터를 공유 경로에서 최대한 치워라"라는 원칙의 자연스러운 확장이라 할 수 있습니다.
결론: 워크로드에 맞는 하드웨어 선택하기
멀티 GPU의 성능은 제품 사양서에 적힌 내용보다 x86 PCIe 토폴로지에 의해 더 크게 좌우됩니다. 어떤 CPU를 쓰느냐에 따라 사용 가능한 레인 수가 결정되고, 메인보드가 이를 어떻게 분배하느냐가 관건인데, 보통은 싱글 GPU 구성을 우선시하도록 설계되어 있거든요.
구매 전 체크리스트:
메인보드 매뉴얼에서 실제 레인 할당 방식을 확인하세요. “3개의 PCIe x16 슬롯"을 지원한다고 광고하는 보드라도, 실제로는 부하가 걸리면 x16/x0/x4나 x8/x8/x4로 동작하는 경우가 태반입니다. GPU당 12GB/s 대역폭을 밀어 넣는 상황이라면 이 숫자가 정말 중요합니다.
최적화 전 체크리스트:
진짜 병목 구간이 어디인지 측정부터 해보세요. 학습 중에 nvidia-smi dmon -s pucvmet 명령어를 실행해서 PCIe 처리량을 확인하는 겁니다. 만약 x8 레인 환경에서도 GPU 사용률이 90% 이상 나온다면, 병목은 I/O가 아니라 파이프라인의 다른 곳에 있다는 뜻입니다. 레인을 늘려봤자 아무 소용 없다는 거죠.
플랫폼의 현실:
일반 데스크톱 CPU(Ryzen 5/7, Core i5/i7/i9)는 보통 총 2024개의 PCIe 레인을 제공합니다. 이 정도면 GPU 2개를 x8로 돌리고 NVMe 저장장치를 쓰기엔 충분합니다. 그런데 고대역폭 GPU를 34개씩 써야 한다고요? 그럴 때 필요한 게 바로 Threadripper나 Xeon W, EPYC 같은 녀석들입니다. 64~128개의 레인을 제공하지만, 그만큼 몸값이 비싸죠.
경제적인 최적화:
4개의 A6000을 모두 x16으로 돌려야 한다면 2,000달러짜리 HEDT 플랫폼을 사는 게 맞습니다. 하지만 단순히 Stable Diffusion 속도를 두 배 높이겠다고 그런 장비를 사는 건 낭비죠. 워크로드에서 창출되는 수익이나 절감되는 시간을 고려해서 하드웨어에 투자하세요. x8로도 x16 성능의 95%를 뽑아낼 수 있다면, 사실 “적당한 수준"이 가장 최적일 때가 많거든요.
진짜 중요한 질문은 “멀티 GPU를 돌릴 수 있는가"가 아니라, “내 워크로드가 그만큼의 고스펙 플랫폼을 정당화할 수 있는가"입니다. 이제 PCIe 토폴로지에 대해 확실히 알게 되셨으니, 이 질문에 정직하게 답할 수 있을 겁니다. 사양 부족으로 x4 병목에 걸리거나, 3,000달러짜리 메인보드에 놀고 있는 레인을 보며 후회하는 일을 모두 피할 수 있을 테니까요.
레인을 확인하고, 병목을 측정하고, 실제로 필요한 만큼만 구매하세요.