Introduction: Why Clean Code Still Matters in the AI Era
We’re flooded with AI tools that promise to do the coding for us. But after experimenting with them, I noticed a recurring pattern: AI writes code in a vacuum. It doesn’t see the “messy” reality of my project three files away. I realized that the faster the AI generates code, the faster my codebase can turn into a nightmare if I’m not careful. This brought me back to the basics. Why did we start talking about Clean Code in the first place? As Uncle Bob famously noted in his book years before ChatGPT existed:
“Indeed, the ratio of time spent reading versus writing is over 10 to 1. We are constantly reading old code as part of the effort to write new code.” - Robert C. Martin
That ratio hasn’t changed with AI. We still spend most of our time reading, understanding, and navigating existing code. The AI handles the typing part, but you’re still the one who has to understand what the code does, how it fits together, and whether it’s correct.
Think of your codebase like a Jenga tower. AI can hand you blocks faster than ever, but if you don’t place them carefully from the foundation up, the whole thing collapses the moment you need to pull one out. Every shortcut, every “I’ll clean this up later,” every unclear variable name compounds over time.
The goal hasn’t changed: deliver business value continuously and sustainably. Clean code isn’t about being pedantic or aesthetic—it’s about maintaining the ability to ship features next month, next quarter, next year. When your codebase becomes unreadable, velocity drops to zero regardless of how fast AI can generate new code.
The principles of clean code aren’t just still relevant in the AI era—they’re more critical than ever. The faster we can generate code, the faster we can create a mess.
The Essence of Clean Code: A Universal Agreement for Collaboration
The Agile Manifesto emphasizes sustainable development and continuous attention to technical excellence. Clean code isn’t separate from these goals—it’s how you achieve them. Code that’s hard to read slows down every sprint and accumulates technical debt.
The Economic Reality: Reading vs. Writing
Developers spend more time reading code than writing it. Function names that require mental translation, nested conditionals that demand careful tracing, implicit assumptions buried in git history—these slow down every task.
Clean code addresses three fundamental costs:
Reading cost minimization: Code should be clear on first read. Compare:
def calc(x, y, z):
return (x * y) * (1 + z)
vs.
def calculate_order_total_with_tax(subtotal, quantity, tax_rate):
# Example: subtotal=$100, quantity=2, tax_rate=0.20 → $240
return (subtotal * quantity) * (1 + tax_rate)
The second version eliminates guesswork. When reading code six months later—or when a teammate needs to modify it—explicit names mean you understand intent immediately instead of reconstructing logic from context.
Intent clarification: Explicit intent means new team members onboard faster, bugs surface sooner, and changes happen with confidence.
Problem decomposition: Complex problems broken into well-named, focused functions create natural documentation. Each function represents one idea instead of a wall of mixed logic.
A Universal Principle, Not a Programming Quirk
In a professional kitchen, tools and ingredients have consistent locations so anyone can work efficiently under pressure. A sous chef stepping in mid-shift doesn’t hunt for the paring knife or guess which container holds cumin. These conventions aren’t personal preference—they prevent collision when multiple people work in the same space.
Software development works the same way. Consistent naming conventions, predictable file structures, clear separation of concerns—these shared conventions reduce the overhead of collaboration.
AI development tools work better with clean code patterns. Claude Code generates more relevant suggestions when surrounding code follows clear, consistent patterns. The same practices that help human collaboration help AI collaboration.
When to Break the Rules
Clean code isn’t dogma. Throwaway scripts, quick prototypes, or one-off migrations rarely need perfect naming. Performance-critical inner loops sometimes need terse variable names to keep implementation details visible. The key is conscious decision-making: understand when you’re incurring technical debt and why.
Most production code—the kind that lives for years and gets maintained by teams—benefits from clean code practices. The 5 minutes spent on a better function name saves hours across the codebase’s lifetime.
AI and Clean Code
AI coding assistants don’t persist knowledge between sessions. When you start a new session tomorrow, the AI has no memory of today’s work. Within a session, most tools maintain conversation history, but they still need to load relevant code files into context for each request. They use various mechanisms—embeddings with semantic search, AST parsing, dependency graph analysis, or LSP information—to retrieve files from your codebase, then load those files into the context window. The quality of your code directly determines how much context the AI needs and how much room remains for reasoning about the solution.
The Context Budget Problem
Attention degradation: Models struggle to accurately reference information in very long contexts. Research shows this “lost in the middle” phenomenon—a fact buried in 100K tokens is harder for the model to retrieve and reason about correctly, even though it technically fits in the window.
The Token Tax: We often forget that every line of messy code is a “tax” on the AI’s reasoning capability. Claude Code has strict message limits and context overhead; if your project is cluttered, you’re essentially paying a premium to feed the AI “trash.” A clean, modular codebase means you can fit more of your actual project into a single prompt, resulting in fewer hallucinations and faster iterations before you hit that dreaded “You’ve reached your limit” notification.
Here’s what happen s when context bloats: You ask the AI to add a validation check to your order processing function. In clean code, the AI loads the function (50 lines) and the validation utilities module (100 lines). In messy code, it needs the function (200 lines with mixed concerns), three different validation patterns scattered across files, the database models to understand data types, and the configuration file to figure out which validation applies when. Instead of 150 tokens of relevant code, you’re loading 2,000 tokens of tangled dependencies. The AI generates code that uses the wrong validation pattern because it couldn’t track which pattern applies to this specific case—the information was there, but buried in noise.
The Robot Vacuum Analogy
To put it simply: coding with AI is like using a robot vacuum.
If your floor is covered in large obstacles, tangled cables, and random clutter, a robot vacuum won’t make your life easier. You’ll spend more time “rescuing” the robot or pre-cleaning the floor than if you had just grabbed a broom yourself. But if your room is organized and the floor is flat? You can just lie on your bed and give the command.
The same applies to AI. If your codebase is a mess of tangled dependencies and “obstacles,” the AI gets stuck. But if your architecture is clean and “flat,” you just give the command and watch the work get done.
Architecture over Implementation
So, how do we build an “AI-friendly” room?
The good news is that you don’t have to write every single line of code yourself anymore. Your job has shifted: you are no longer the one pushing the broom; you are the Architect. Your primary responsibility is to define the right patterns and structures for the AI to follow.
Here are the methodologies and their brief overview aht I frequently use to keep my codebase maintainable.
Recommendation 1: DDD and Bounded Context
When you modify your codebase, they need to understand what’s related. Domain-Driven Design (DDD)’s bounded contexts give them that map — authentication code stays separate from payment code not because of technical layering, but because they’re different domains with different rules.
1. Domain Alignment Over Technical Layers
DDD shifts the focus from technical implementation to the core business logic, treating technology as a supporting detail. This alignment ensures that the software architecture evolves in sync with business requirements, creating a resilient structure where technical decisions never compromise the integrity of business rules.
2. Ubiquitous Language: Consistency is Key
Ubiquitous Language means using identical terminology in code, documentation, specs.
- Inconsistent (High Risk): Code uses
UserAccount, Specs useCustomer profile, and you prompt forSubscriber. The AI must guess if these are the same thing. - Consistent (Low Risk): Everyone uses
Customer. Instead of saying “add a field to track user purchases,” you say: “Add purchaseHistory to the Customer aggregate in the Sales context.” Precise prompts become possible only with precise naming.
3. Aggregates: Defining Modification Scope
Aggregates protect business rules (invariants) that must always be true. This defines what can be modified together and what must stay consistent.
// Order aggregate protects invariants
class Order {
private lines: OrderLine[] = [];
private total: Money;
// Right: AI should suggest this (Enforces invariants)
addLine(productId: string, quantity: number, price: Money) {
const line = new OrderLine(productId, quantity, price);
this.lines.push(line);
this.recalculateTotal(); // Logic for "total must match sum of prices"
}
private recalculateTotal() {
this.total = this.lines.reduce((sum, line) => sum.add(line.subtotal()), Money.zero());
}
}
// Wrong: AI shouldn't suggest direct manipulation
// order.lines.push(new OrderLine(...)); -> Bypasses invariant checks
4. Context Map: Boundaries and Relationships
A Context Map explicitly defines how different domains (Contexts) interact.
- The Database Warning: Sharing a database between contexts creates coupling through schema migrations and shared transactions. If you must share, use separate schemas. Shared database migrations are a common cause of AI-generated code breaking multiple contexts simultaneously.
Key Relationship Types:
- Shared Kernel: Two contexts share a specific model (e.g.,
Money). Both teams must coordinate changes to this shared code. - Customer-Supplier: One context (Orde`r) depends on a stable API from another (Catalog).
- Anticorruption Layer (ACL): Order doesn’t use Catalog’s internal models directly; it translates through an adapter. This is crucial when the AI needs to integrate with legacy or third-party APIs.
5. Avoid the “Shared” Dumping Ground
A single shared or common module becomes a dumping ground where everything depends on everything. Changes ripple everywhere, and AI tools can’t determine what’s safe to modify.
Extract common logic into an explicit Shared Kernel (e.g., /src/shared_kernel), but keep it as lean as possible. Treat it as a stable, minimalist contract. The smaller the kernel, the less coupling you create.
Warning signs your contexts are bleeding:
- AI suggestions frequently span multiple contexts in a single change.
- The same entity name exists in multiple contexts without clear differentiation.
- You need extensive cross-context coordination for simple features.
Recommendation 2: Hexagonal Architecture
Hexagonal Architecture (also known as Ports and Adapters) solves a simple but critical problem: your business logic shouldn’t break when you swap PostgreSQL for MySQL, or switch from Express to Fastify.
Domain Isolation and Testability
The core principle is straightforward: keep your domain logic free from infrastructure dependencies or frameworks. Your business rules shouldn’t know or care whether data comes from a database, a message queue, or an HTTP API.
// Bad: Domain logic coupled to infrastructure
class OrderService {
async createOrder(items: Item[]) {
const order = new Order(items);
// Direct dependency on PostgreSQL client
await pgClient.query('INSERT INTO orders...', order);
// Direct dependency on RabbitMQ
await rabbitMQ.publish('order.created', order);
return order;
}
}
// Good: Domain logic isolated
class OrderService {
constructor(
private orderRepository: OrderRepository, // Port (interface)
private eventPublisher: EventPublisher // Port (interface)
) {}
async createOrder(items: Item[]): Promise<Order> {
const order = new Order(items);
await this.orderRepository.save(order);
await this.eventPublisher.publish('order.created', order);
return order;
}
}
This isolation gives you two immediate benefits:
- Testing becomes trivial - mock the interfaces, no database or message queue needed
- Infrastructure changes don’t ripple into business logic - swap implementations without touching the domain
Infrastructure Changes More Than Domain
Here’s the reality of backend systems:
- Infrastructure changes: Database migrations, switching message brokers, adopting new frameworks, moving from REST to gRPC
- Domain changes: Business rules, pricing logic, order workflows
Infrastructure evolves constantly. Domain logic, once stabilized, changes far less frequently. Hexagonal Architecture acknowledges this asymmetry by making infrastructure swappable while keeping domain code stable.
I’ve seen teams migrate databases or frameworks where the domain logic remained entirely untouched. By isolating the core, the team could focus their energy entirely on the porting process, ensuring the business logic was preserved without risk of regression. That is the true power of proper abstraction.
Dependency Direction Matters
Traditional Layered Architecture:
Domain → Database Library → PostgreSQL
Domain → Framework → Express
Hexagonal Architecture:
Domain ← Repository Adapter → PostgreSQL
Domain ← HTTP Adapter → Express
In hexagonal architecture, dependencies point inward. The domain defines interfaces (ports), and infrastructure implements them (adapters). The domain never imports from infrastructure packages.
// Domain layer defines the contract
interface OrderRepository {
save(order: Order): Promise<void>;
findById(id: string): Promise<Order | null>;
}
// Infrastructure layer implements it
class PostgresOrderRepository implements OrderRepository {
constructor(private pool: pg.Pool) {}
async save(order: Order): Promise<void> {
// PostgreSQL-specific implementation
}
async findById(id: string): Promise<Order | null> {
// PostgreSQL-specific implementation
}
}
Use It Selectively: Bounded Context Level Only
Do not apply hexagonal architecture everywhere. This is critical.
Apply it at the Bounded Context level - services with complex business logic:
- Payment processing service
- Inventory management service
- Pricing engine service
Don’t apply it to:
- API Gateway - it’s just routing and composition, no domain logic
- Composition services - aggregating data from multiple services
- Simple CRUD services - adding layers adds no value, only overhead
- Internal tools and admin panels - pragmatism over purity
- Anticorruption Layer (ACL) : If you’re building a dedicated proxy or adapter to translate between a legacy system and a new one, the ACL is the adapter. Don’t wrap an adapter in another hexagonal structure; just focus on the mapping logic.
I’ve seen teams apply hexagonal architecture to an API gateway that literally just forwards requests. The result? Four extra layers of indirection for zero benefit. Your API gateway doesn’t need a “domain layer” - it has no domain.
Practical Structure
src/
├── contexts/
│ ├── payment/ # Complex Domain: Apply Hexagonal
│ │ ├── domain/ # Pure Business Logic
│ │ │ ├── model/ # Entities & Value Objects
│ │ │ ├── service/ # Domain Services (Use Cases)
│ │ │ └── ports/ # Output Interfaces (Repository/Gateway)
│ │ ├── adapters/ # External Implementation
│ │ │ ├── in/ # Driving: HTTP, CLI, Message Queue
│ │ │ └── out/ # Driven: Postgres, Stripe, Redis
│ │ └── index.ts # Context Entry Point (DI)
│ │
│ ├── catalog/ # Simple CRUD: Skip Hexagonal
│ │ ├── models.ts # Simple DB Models
│ │ ├── routes.ts # Direct API Routing
│ │ └── services.ts # Basic Query/Command logic
│ │
│ └── shared_kernel/ # Minimal & Explicit Shared Logic
│ └── money.ts # Shared Value Object
The domain folder contains zero infrastructure imports. If you see import pg from 'pg' or import express from 'express' in your domain code, you’re doing it wrong.
When You Know It’s Working
You can test your entire domain logic without spinning up a database, message queue, or HTTP server. Your tests look like this:
describe('OrderService', () => {
it('should create order and publish event', async () => {
const mockRepo = { save: jest.fn() };
const mockPublisher = { publish: jest.fn() };
const service = new OrderService(mockRepo, mockPublisher);
await service.createOrder([item1, item2]);
expect(mockRepo.save).toHaveBeenCalled();
expect(mockPublisher.publish).toHaveBeenCalledWith('order.created', expect.any(Order));
});
});
No database setup, no teardown, no network calls. Tests run in milliseconds.
Hexagonal architecture isn’t about drawing pretty diagrams. It’s about protecting your business logic from infrastructure churn and making your code testable without external dependencies. Use it where it matters, skip it where it doesn’t.
Recommendation 3: Adopt a Mono-repo Strategy
After defining bounded contexts, the instinct is often to create separate repositories for each domain. This feels clean and aligned with DDD principles, but it creates significant friction that outweighs the perceived benefits.
The Multi-repo Productivity Tax
Cross-domain refactoring becomes painful. When you rename a core domain entity that multiple contexts reference, you need to coordinate changes across multiple PRs in different repositories. The OrderContext might reference CustomerId, but if the CustomerContext refactors this to CustomerAccountId, you’re managing synchronized releases across repos.
Shared code requires package versioning overhead. Common utilities or value objects need to be extracted into internal packages. You end up publishing packages, managing semantic versioning, and updating dependencies across repositories just to share a Money value object.
Dependency updates multiply. Security patches or framework upgrades require opening PRs in every repository. What should be a single update becomes a coordination exercise.
Why Mono-repo Works for DDD
A mono-repo keeps all bounded contexts in a single repository while maintaining logical separation through directory structure:
/
├── apps/
│ ├── order-service/
│ ├── customer-service/
│ └── inventory-service/
├── packages/
│ ├── order-domain/
│ ├── customer-domain/
│ ├── inventory-domain/
│ └── shared-kernel/
└── tools/
Each app in apps/ is a deployable service that imports domain packages:
// apps/order-service/src/handlers/createOrder.ts
import { Order, OrderId } from '@myapp/order-domain';
import { CustomerId } from '@myapp/customer-domain';
import { Money } from '@myapp/shared-kernel';
The workspace protocol (pnpm workspaces, yarn workspaces, or npm workspaces) handles package resolution. Your root package.json defines the workspace structure:
{
"name": "myapp-monorepo",
"private": true,
"workspaces": [
"apps/*",
"packages/*"
]
}
Each package and app has its own package.json with specific dependencies, but workspace-aware package managers coordinate versions and deduplication across the entire repo.
Atomic changes across contexts. When your Payment domain needs to integrate with Order domain, you make all changes in a single PR. The CI pipeline validates everything together.
Simplified code sharing. Shared utilities, domain events, or integration contracts live in the same repository. Import what you need without publishing internal packages.
Centralized dependency management. Security updates happen once at the root level. Workspace tools ensure consistent versions across all packages.
Full codebase visibility. Search across all domains simultaneously. Understanding how contexts interact is a grep command away.
Mono-repo Tools: Nx Deep Dive
Modern tools make mono-repos viable at scale. Nx is the most mature option for enterprise applications and DDD structures.
Nx builds a dependency graph of your projects and runs tasks intelligently. Here’s a minimal nx.json configuration:
{
"tasksRunnerOptions": {
"default": {
"runner": "nx/tasks-runners/default",
"options": {
"cacheableOperations": ["build", "test", "lint"]
}
}
}
}
Define project dependencies in each package:
// packages/order-domain/project.json
{
"name": "order-domain",
"targets": {
"build": {
"executor": "@nx/js:tsc",
"outputs": ["{workspaceRoot}/dist/packages/order-domain"]
},
"test": {
"executor": "@nx/jest:jest"
}
},
"implicitDependencies": ["shared-kernel"]
}
When you modify shared-kernel, Nx knows to rebuild order-domain and any apps that depend on it. Unchanged projects use cached builds. On CI, this cuts build times from “everything every time” to “only what changed.”
Nx also provides:
- Remote caching across developers and CI servers
- Parallel execution with configurable concurrency
- Affected command detection:
nx affected:testruns tests only for changed projects
Turborepo is a lighter alternative focused on pipeline optimization with excellent remote caching for typescript. It’s simpler to configure but less feature-rich.
Mono-repo ≠ Monolithic
Using a mono-repo doesn’t mean building a monolithic application.
A mono-repo is a version control strategy. All code lives in one repository.
A monolith is a deployment architecture. All code runs as a single process.
You can absolutely deploy each bounded context as an independent service from a mono-repo. The order-service and customer-service directories become separate Docker images, deployed independently, scaled independently, and failing independently.
The mono-repo gives you development ergonomics. Your deployment strategy remains a separate decision based on your scaling needs, team structure, and operational requirements.
Real Trade-offs to Consider
Mono-repos aren’t universally better. They introduce specific challenges:
CI/CD complexity increases. When deploying services independently, you need logic to detect which services changed and build only those Docker images. Naive CI that builds everything on every commit wastes time. You’ll need tools like Nx’s affected commands or custom scripts.
Clone size grows over time. A mono-repo with years of history across dozens of services becomes large. Initial clones take longer. Git operations slow down at scale, though partial clone strategies help.
Access control is coarser. In a multi-repo setup, you can restrict access to specific repositories. In a mono-repo, developers typically have access to the entire codebase. If regulatory or security requirements demand strict separation, mono-repos are harder to lock down.
Deployment decoupling becomes harder. Services often have different release cycles and risk profiles. If boundaries aren’t strictly maintained, you risk creating a “distributed monolith” where a change in one service triggers unnecessary builds for others. This is especially inefficient for entirely unrelated services that share no code, as the overhead of enforcing isolation in a shared repo often outweighs the benefits of co-location.
Git history becomes noisy. Commits across all domains appear in the same history. Finding relevant changes requires better commit discipline and tooling.
For most teams (under 50-100 developers, managing under 20 services), these trade-offs are manageable and outweighed by the productivity gains. At larger scale, the calculus shifts—Google and Facebook famously use mono-repos, but they’ve built custom infrastructure to handle billions of lines of code.
Recommendation 4: Microservice vs Monolithic
Microservices are not a silver bullet. I’ve seen too many teams adopt microservices prematurely, lured by conference talks and tech blog hype, only to struggle with complexity they weren’t ready to handle.
The Hidden Costs of Microservices
Microservices replace code complexity with distributed systems complexity:
Data flow becomes invisible. In a monolith, you can trace a request through your codebase with a debugger. In microservices, a single user action might trigger a cascade of HTTP calls, message queue events, and async operations across five different services. When something breaks, debugging requires distributed tracing tools and correlation IDs across multiple log streams.
Testing becomes exponentially harder. Integration tests now require spinning up multiple services, managing test databases for each, and coordinating state across service boundaries. Contract testing tools like Pact or consumer-driven contracts become necessary to verify service interactions without full integration environments.
Operational overhead multiplies. Each service needs its own deployment pipeline, monitoring, logging aggregation, and incident response procedures—turning what was single-app operations into managing a fleet.
Network reliability becomes your problem. You now deal with timeouts, retry logic, circuit breakers, and service mesh complexity. A database query that took ~5ms becomes a network call that might take ~50ms or fail entirely. Tools like Istio or Linkerd help, but add another layer of infrastructure to manage.
Data consistency gets complicated. Transactions that were simple database commits now involve distributed transactions, saga patterns, or eventual consistency. Foreign key constraints can’t span services—you handle referential integrity in application code.
When Monolithic Makes Sense
Start with a monolith if:
- Your domain boundaries are unclear. Early-stage products pivot constantly. Refactoring within a monolith is painful; refactoring across microservices is a nightmare.
- Your team is small (< 10 engineers). The coordination overhead of microservices will slow you down more than a shared codebase.
- You don’t have independent scaling needs. If your entire app scales together, microservices add complexity without benefit.
- You’re optimizing for development speed. Shipping features fast matters more than theoretical scalability.
- Your security needs are uniform. If all parts of your app share the same data sensitivity, managing a single security perimeter is simpler than securing dozens of separate connections.
When Microservices Make Sense
Consider microservices when:
- You have clear, stable domain boundaries. Your user management system, payment processing, and content delivery have minimal overlap and change for different reasons.
- You need independent scaling. Your video transcoding service needs 50x the resources of your API gateway.
- You have multiple teams that need to move independently. Team A can deploy their service without waiting for Team B’s code review.
- You have specific technology requirements. Your recommendation engine benefits from Python’s ML ecosystem while your application API layer stays in Node.js or Kotlin.
- You need to isolate sensitive data. Placing payment processing or identity management in a dedicated service makes it easier to meet strict compliance without subjecting the entire codebase to the same audit rigor.
The Separation Decision
Split a module into its own service when you see concrete signals:
- Scaling mismatch: One module handles >10x the traffic of others and needs independent infrastructure
- Team contention: >3 teams touching the same codebase causing frequent merge conflicts (>5 per week)
- Stability divergence: A domain hasn’t changed in 6+ months while others iterate rapidly
- Different SLAs: Some functionality needs 99.99% uptime while other parts tolerate more downtime
Patterns for a Flexible Codebase
Build a modular monolith—strong logical boundaries within a single deployable unit. Structure by business domain, not technical layers. Each module should:
Own its data logically. Other modules access this data only through the module’s service layer, never direct database queries. This prepares you for database-per-service if you split later, while still using a shared database today:
// ❌ DON'T: Direct cross-module database access
const user = await db.query('SELECT * FROM users WHERE id = ?', userId);
const payment = await db.query('SELECT * FROM payments WHERE user_id = ?', userId);
// ✅ DO: Access through module API
const user = await UserService.getById(userId);
const payment = await PaymentService.getByUserId(userId);
Expose a clear public API. Define which functions are public interfaces vs internal implementation:
// user-management/index.js
export { getById, authenticate, updateProfile } from './services/user-service';
// Don't export internal helpers, repository functions, or models
Enforce boundaries at build time. Tools like Nx let you prevent unauthorized imports:
// nx.json - dependency constraints
{
"projects": {
"payment-processing": {
"tags": ["domain:payment"],
"implicitDependencies": []
},
"user-management": {
"tags": ["domain:user"],
"implicitDependencies": []
}
},
"targetDefaults": {
"lint": {
"options": {
"depConstraints": [
{
"sourceTag": "domain:payment",
"onlyDependOnLibsWithTags": ["domain:payment", "shared"]
},
{
"sourceTag": "domain:user",
"onlyDependOnLibsWithTags": ["domain:user", "shared"]
}
]
}
}
}
}
This prevents payment-processing from accidentally importing internal code from user-management. The build fails if you violate boundaries.
The Hard Part: Data Migration
Splitting services means splitting your database. This is where most teams struggle:
Denormalize data across boundaries. If payment-processing needs user email addresses, copy that data into the payments service rather than joining across databases:
// Before: Single database with joins
SELECT p.*, u.email
FROM payments p
JOIN users u ON p.user_id = u.id
// After: Denormalized in payment service
SELECT p.*, p.user_email // email copied to payments table
FROM payments p
Replace foreign keys with service calls. Referential integrity checks move from database constraints to application logic:
// Before: Database enforces user exists
CREATE TABLE payments (
user_id INT REFERENCES users(id)
);
// After: Application validates via service call
@Transactional
async function createPayment(userId, amount) {
const user = await userServiceClient.getById(userId);
if (!user) throw new Error('User not found');
return db.payments.insert({ userId, amount });
}
Recommendation 5: CQRS Pattern
CQRS (Command Query Responsibility Segregation) separates Write models (commands) from Read models (queries). Write operations use domain objects with business rules. Read operations use specialized DTOs optimized for queries.
Complex queries pollute domain objects with view-specific fields. A user listing that needs “total purchase amount” adds a totalPurchase property to the User entity, eroding DDD principles.
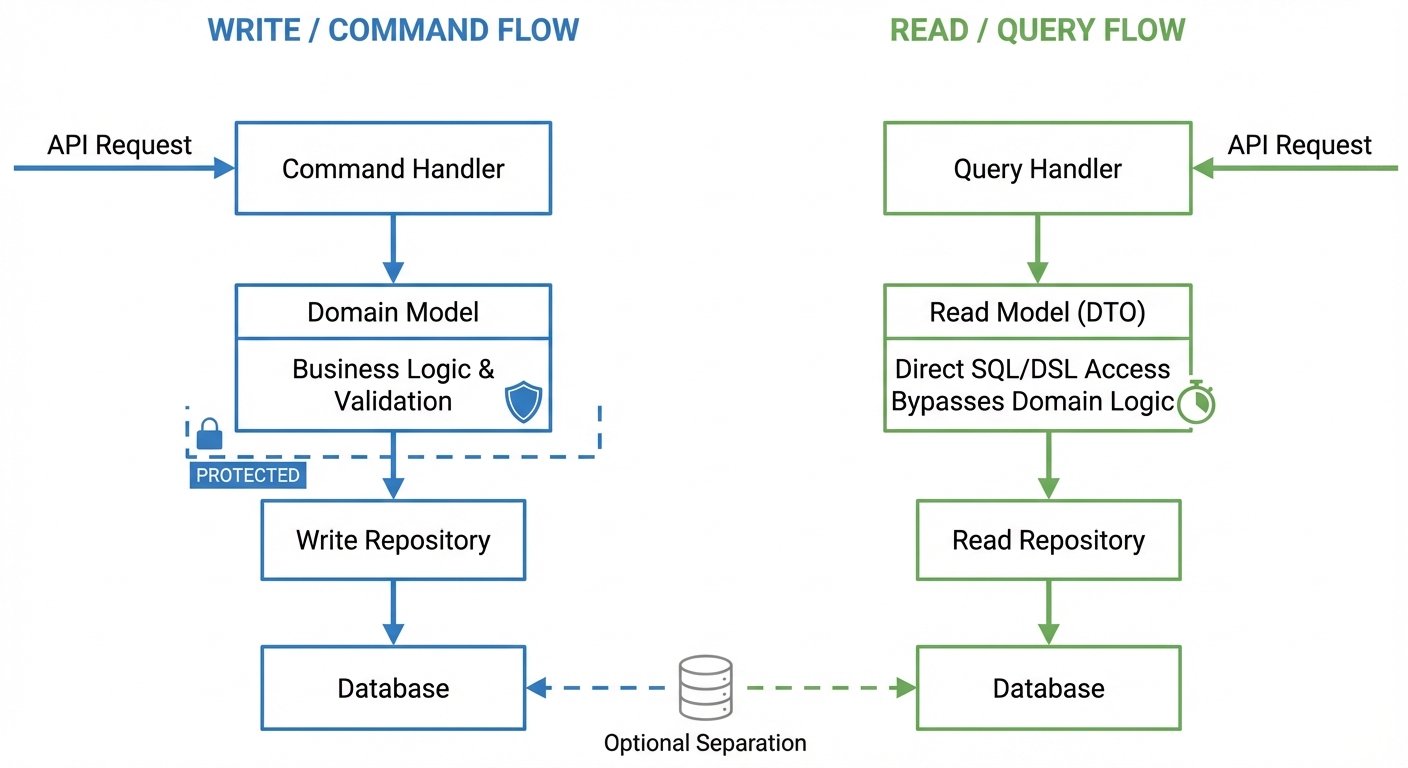
Protecting Domain Objects
// ❌ Domain object polluted with view concerns
class User {
id: string;
email: string;
// These don't belong in the domain model
totalPurchaseAmount?: number; // Only for admin dashboard
lastLoginDate?: Date; // Only for analytics
orderCount?: number; // Only for reports
}
// ✅ Clean domain object
class User {
id: string;
email: string;
changeEmail(newEmail: string) {
// Business logic for email changes
}
}
// ✅ Separate read model for views
interface UserDashboardView {
userId: string;
email: string;
totalPurchaseAmount: number;
lastLoginDate: Date;
orderCount: number;
}
In prompts and code reviews, enforce: domain objects for writes, DTOs for reads.
Using DSL/SQL for Complex Queries
In complex domains like financial settlement or reporting, you need aggregations across multiple tables. Don’t force this through domain objects—use direct queries for pure data retrieval:
// ✅ Direct query for complex view
class SettlementQueryRepository {
async getMonthlySettlement(merchantId: string, year: number, month: number) {
return this.db.query(`
SELECT
m.merchant_id,
m.merchant_name,
COUNT(o.order_id) as order_count,
SUM(o.amount) as total_amount,
SUM(o.fee) as total_fee,
SUM(o.amount - o.fee) as net_amount
FROM merchants m
JOIN orders o ON m.merchant_id = o.merchant_id
WHERE m.merchant_id = $1
AND EXTRACT(YEAR FROM o.created_at) = $2
AND EXTRACT(MONTH FROM o.created_at) = $3
GROUP BY m.merchant_id, m.merchant_name
`, [merchantId, year, month]);
}
}
For queries like this, you can use raw SQL or type-safe query builders like Kysely:
// ✅ Type-safe alternative with Kysely
async getMonthlySettlement(merchantId: string, year: number, month: number) {
return this.db
.selectFrom('merchants as m')
.innerJoin('orders as o', 'm.merchant_id', 'o.merchant_id')
.select([
'm.merchant_id',
'm.merchant_name',
(eb) => eb.fn.count('o.order_id').as('order_count'),
(eb) => eb.fn.sum('o.amount').as('total_amount'),
(eb) => eb.fn.sum('o.fee').as('total_fee'),
])
.where('m.merchant_id', '=', merchantId)
.where(sql`EXTRACT(YEAR FROM o.created_at)`, '=', year)
.where(sql`EXTRACT(MONTH FROM o.created_at)`, '=', month)
.groupBy(['m.merchant_id', 'm.merchant_name'])
.execute();
}
Query builders enable compile-time type checking and dynamic query composition (add filters conditionally without string concatenation). Raw SQL is more direct but loses type safety. Choose based on your team’s priorities.
Critical for performance: Add indexes for the query patterns. For financial settlement queries, index column order matters: (merchant_id, created_at) works for queries filtering by merchant first. For time-range queries across all merchants, you need (created_at, merchant_id). Check your query patterns with EXPLAIN ANALYZE.
Storage-Level Separation
For high-traffic systems, you can separate Write and Read databases:
// Write: normalized tables, transactional
class OrderCommandRepository {
constructor(private writeDb: Database) {}
async createOrder(order: Order) {
await this.writeDb.transaction(async (tx) => {
await tx.insert('orders', order);
await tx.insert('order_items', order.items);
});
}
}
// Read: denormalized view, optimized for queries
class OrderQueryRepository {
constructor(private readDb: Database) {}
async getOrderListView(filters: OrderFilters) {
// Query against materialized view
return this.readDb.query('order_list_view', filters);
}
}
Data flows from write to read database via:
- CDC (Change Data Capture): Sub-second latency, requires database-specific tooling (Debezium for PostgreSQL, DynamoDB Streams). Adds operational complexity but provides near-real-time sync.
- Event streams: Build an audit log, enables multiple read projections. Adds infrastructure (Kafka/RabbitMQ) and application-level publish logic.
- Polling: Simplest approach, query write DB for changes every 5-30s. Wastes resources on empty polls but requires no special infrastructure.
For PostgreSQL materialized views, refresh strategy matters. REFRESH MATERIALIZED VIEW locks the view during refresh—unacceptable for production reads. Use REFRESH MATERIALIZED VIEW CONCURRENTLY, which requires a unique index and takes longer but allows concurrent reads. Triggers that update on every write cause write amplification—prefer scheduled refreshes (cron job running REFRESH MATERIALIZED VIEW CONCURRENTLY every 5-15 minutes) for most use cases.
Separate storage when:
- Read queries cause measurable write latency (p99 > 100ms)
- Read and write databases need different scaling strategies (write needs vertical scaling for transactions, read needs horizontal scaling for query distribution)
- Query complexity requires denormalized schemas that conflict with normalized write models
Eventual Consistency Trade-offs
When read storage is separate, accept that reads may be stale. The read database reflects the write database’s state from seconds or minutes ago, depending on sync frequency.
For financial settlement reports, showing yesterday’s finalized data is acceptable. For real-time inventory checks or fraud detection, stale data creates business problems. Don’t separate storage for use cases that require strong consistency.
If you need both read optimization and consistency guarantees, keep the same database but use dedicated read replicas. Note that even with synchronous replication (which provides durability, not consistency), read replicas can lag. For critical reads that need fresh data, query the write database directly:
async getOrderStatus(orderId: string, requiresFreshData: boolean) {
if (requiresFreshData) {
return this.writeDb.query('SELECT * FROM orders WHERE id = $1', [orderId]);
}
return this.readDb.query('SELECT * FROM order_list_view WHERE id = $1', [orderId]);
}
This defeats caching but solves the consistency problem for critical paths.
When NOT to Use CQRS
Don’t use CQRS for simple CRUD operations. If your read and write models are identical—a basic user profile that shows the same fields you edit—separation adds boilerplate without benefit.
Start with shared models. Split into CQRS when:
- View complexity requires joins across tables
- Read models need fields that don’t exist in domain objects
- Performance monitoring shows read queries impacting write operations
Premature CQRS creates unnecessary abstraction. Apply it when view requirements force the split.
Recommendation 6: Type Safety
When an AI generates code in a dynamically typed language, it might reference user.email when the object only has user.emailAddress. In JavaScript or plain Python, this fails at runtime. With TypeScript or Python type hints, the IDE flags it immediately.
Without types (JavaScript):
function sendNotification(user, message) {
// AI might generate this, but user.email doesn't exist
sendEmail(user.email, message);
logActivity(user.id, 'notification_sent');
}
With types (TypeScript):
interface User {
userId: string;
emailAddress: string;
displayName: string;
}
function sendNotification(user: User, message: string): void {
// IDE immediately shows: Property 'email' does not exist on type 'User'
sendEmail(user.email, message); // ❌ Compile error
// AI must use the correct property
sendEmail(user.emailAddress, message); // ✅ Correct
logActivity(user.userId, 'notification_sent');
}
Types eliminate entire classes of errors before runtime—wrong object references, non-existent properties, incorrect function signatures. The AI can’t hallucinate a method that doesn’t exist if the type system won’t compile it.
How Types Constrain AI Output
With complex transformations or data mappings, AI often accesses nested properties that don’t exist or passes arguments in the wrong order.
Running mypy or using an IDE with type checking catches this before it ever runs. The compile-time feedback loop is faster than the test-and-fix cycle:
- Immediate feedback: Red squiggles in the IDE, not failures in CI/CD
- Better autocomplete: Types improve AI’s context understanding for subsequent code
- Reduced iteration: Fewer back-and-forth prompts to fix basic mistakes
In TypeScript projects, just let strict typing enabled and use biome with husky.
Effective Type Patterns for AI
TypeScript and Python type hints offer a practical middle ground—you get type safety where it matters without the verbosity of fully static languages like Java.
Define interfaces for all external data
Any data coming from APIs, databases, or user input should have an explicit type:
// API response
interface ApiResponse<T> {
data: T;
status: number;
error?: string;
}
interface ProductData {
id: string;
name: string;
price: number;
inStock: boolean;
}
async function fetchProduct(productId: string): Promise<ApiResponse<ProductData>> {
// AI knows exactly what structure to expect and return
const response = await api.get(`/products/${productId}`);
return response.data;
}
Use discriminated unions for state management
This prevents AI from accessing properties that don’t exist in certain states. The common AI mistake: trying to access state.data without checking if the state is actually success.
type RequestState =
| { status: 'idle' }
| { status: 'loading' }
| { status: 'success'; data: ProductData }
| { status: 'error'; error: string };
function handleRequest(state: RequestState): void {
// AI often generates this - accessing data without checking status
displayProduct(state.data); // ❌ Property 'data' does not exist on all union types
// Discriminated unions force proper checks
if (state.status === 'success') {
displayProduct(state.data); // ✅ Type narrowing ensures data exists
} else if (state.status === 'error') {
showError(state.error); // ✅ Type narrowing ensures error exists
}
}
Without the type system, AI generates the first version—code that compiles but crashes when state is loading or error.
Leverage generics for reusable components
Generics maintain type consistency across operations:
from typing import TypeVar, Generic, List, Optional
T = TypeVar('T')
class Repository(Generic[T]):
def __init__(self, items: List[T]):
self._items = items
def find_by_id(self, item_id: str, get_id: callable) -> Optional[T]:
for item in self._items:
if get_id(item) == item_id:
return item
return None
def find_all(self) -> List[T]:
return self._items.copy()
# Usage
user_repo = Repository[User]([user1, user2])
user = user_repo.find_by_id("123", lambda u: u.id) # Type checker knows this is Optional[User]
The generic T ensures type consistency—whatever type you instantiate the repository with flows through all methods. AI can’t accidentally mix types or return the wrong structure.
Type Definitions as Specification
Well-defined types guide AI generation. When you ask AI to “add a method to update user preferences,” it can see the UserPreferences type and knows exactly what fields are available:
interface UserPreferences {
theme: 'light' | 'dark';
notifications: {
email: boolean;
push: boolean;
sms: boolean;
};
language: string;
}
class UserService {
// AI can generate this accurately because it sees the type structure
updatePreferences(userId: string, preferences: Partial<UserPreferences>): void {
// Type system ensures only valid fields are accessed
if (preferences.theme) {
this.validateTheme(preferences.theme); // AI knows theme is 'light' | 'dark'
}
if (preferences.notifications?.email !== undefined) {
this.updateEmailNotifications(userId, preferences.notifications.email);
}
}
}
Without the type definition, AI might generate code that tries to set preferences.colorScheme or preferences.emailNotifications—plausible but wrong.
Limitations of Type Safety
Types catch structural errors but miss entire categories of problems:
Same-type parameter swapping: If two parameters have the same type, AI can still swap them:
function sendEmail(subject: string, body: string): void { ... }
// Both are strings—type checker won't catch this
sendEmail(emailBody, emailSubject); // ✅ Type checks, ❌ semantically wrong
For critical cases, use wrapper types that enforce distinction at the type level:
class EmailSubject {
constructor(public readonly value: string) {}
}
class EmailBody {
constructor(public readonly value: string) {}
}
function sendEmail(subject: EmailSubject, body: EmailBody): void {
// Implementation uses subject.value and body.value
}
// Usage
sendEmail(new EmailSubject("Hello"), new EmailBody("Message text"));
sendEmail(new EmailBody("Message text"), new EmailSubject("Hello")); // ❌ Type error
Business logic errors: Types won’t catch if AI generates algorithmically correct code that doesn’t match your business requirements. If the requirement is “apply discount to items over $100” and AI generates “apply discount to items over $50,” the types are satisfied but the logic is wrong.
Overly complex types: Deep generic nesting, complex conditional types, and intricate type transformations can confuse AI or make the generated code harder to understand. If you find yourself writing types that require multiple readings to understand, simplify them—both for AI and for human maintainers.
Types constrain structure and catch interface mismatches. They don’t replace code review, testing, or domain knowledge.
Practical Implementation
Start with high-value areas:
- API boundaries: Request/response types for all endpoints
- Database models: Entity types matching your schema
- Business logic functions: Input/output types for core operations
- State management: Type-safe reducers and actions
You don’t need 100% type coverage from day one. Focus on the interfaces between components—the places where AI is most likely to make assumptions.
Combine type hints with runtime validation using libraries like pydantic for python or zod for typescript:
from pydantic import BaseModel, validator
from typing import List
class OrderItem(BaseModel):
product_id: str
quantity: int
price: float
class OrderRequest(BaseModel):
items: List[OrderItem]
customer_id: str
shipping_address: str
@validator('items')
def items_not_empty(cls, v):
if not v:
raise ValueError('Order must contain at least one item')
return v
# AI generates this, types ensure correctness
def create_order(request_data: dict) -> Order:
# Pydantic validates at runtime, types guide AI at generation time
validated_request = OrderRequest(**request_data)
return Order(
order_id=generate_id(),
items=validated_request.items,
customer_id=validated_request.customer_id
)
Static types catch errors during code generation and in your IDE. Runtime validation catches malformed data from external sources—API requests, file uploads, user input. Use both: types guide AI during development, validation protects production systems.
Preventing structural errors is crucial, but maintaining consistent code style across AI-generated and human-written code is equally important for long-term maintainability. That’s where automated linting and formatting come in.
Recommendation 7: Automate Linting & Formatting
Inconsistent code style creates noise in code review. AI-generated code mirrors whatever patterns it sees, so enforce your style mechanically—don’t waste review time or AI tokens on formatting.
Filter AI Code with Linters
AI-generated code needs automated style checks. Run it through your linter before review:
# Generate code with AI, then immediately check it
$ biome check --write ./src # JavaScript/TypeScript
$ ruff check --fix . # Python
Catches instantly:
- Unused imports
- Inconsistent spacing
- Missing semicolons
- Line length violations
- Trailing whitespace
Recommended Tools by Language
JavaScript/TypeScript: Biome
Biome combines linting and formatting with significantly better performance than ESLint + Prettier. Single configuration file, zero dependencies:
{
"linter": {
"enabled": true,
"rules": {
"recommended": true
}
},
"formatter": {
"enabled": true,
"indentStyle": "space",
"indentWidth": 2
}
}
Python: Ruff
Ruff replaces multiple tools (Flake8, Black, isort) with one Rust-powered binary. Configure rule categories: E/W for pycodestyle, F for pyflakes, I for import sorting, N for naming:
[tool.ruff]
line-length = 100
select = ["E", "F", "I", "N", "W"]
fix = true
Pre-Commit Automation
#!/bin/sh
# .husky/pre-commit
npm run lint --fix || {
echo "Linting failed. Fix errors before committing."
exit 1
}
Don’t Waste AI Tokens on Formatting
Linters are faster, cheaper, and more reliable than asking AI to format code. If AI consistently produces style violations, update your system prompt—don’t use the AI as a formatter.
Automation Strategy
Run linting at multiple stages:
- Pre-commit: Git hooks block badly formatted commits—prevents bad code from entering the repo
- CI/CD: Fail builds if linting errors exist—team-wide enforcement
Once linting ensures style consistency, functional correctness becomes the next priority. AI can generate code quickly, but without proper testing, you’re shipping untested logic at scale.
Recommendation 8: Testing Strategy
AI generates a 200-line CRUD service in 30 seconds. Thorough manual review takes 20+ minutes. You need automated verification—manual code review alone doesn’t scale.
Enforce Testing in CI/CD
When AI writes a new API endpoint or database query, require tests before merging. Enforce this in your CI/CD pipeline: if branch coverage for critical paths drops below your threshold, the build fails.
Don’t use line coverage as your metric—it’s easily gamed with tests that execute code but verify nothing. Focus on branch coverage for paths where bugs have real consequences.
This creates a contract that defines what the code is supposed to do. When AI generates code you don’t fully understand, the tests tell you what to expect.
Review Test Code First
Focus your review energy on the test code, not the implementation.
Look at what the tests verify:
- Are edge cases covered?
- Do assertions match actual business requirements?
- Are there integration tests for database interactions?
- Are error conditions tested?
Here’s the critical issue with AI-generated tests: AI writes tests that verify what it THINKS the code should do, not necessarily what your requirements demand. The AI might generate perfectly passing tests for behavior you don’t actually want.
Example of what to catch in review:
# AI-generated test - looks good but tests WRONG behavior
def test_create_order():
product = create_product(stock=5)
order = order_service.create_order(product_id=product.id, quantity=3)
assert order.id is not None
assert order.quantity == 3
# AI forgot to verify inventory was decremented!
# Bug: inventory unchanged after order creation
What you need instead:
def test_create_order_decrements_inventory():
product = create_product(stock=5)
order = order_service.create_order(product_id=product.id, quantity=3)
assert order.id is not None
assert order.quantity == 3
assert product.stock == 2 # Critical assertion AI missed
E2E Testing with Playwright
E2E testing is traditionally high-maintenance, but AI agents transform this by shifting from manual scripting to intent-based testing.
- AI-Powered Generation: Describe a user journey in natural language (e.g., “Login to checkout golden path”), and let the AI scaffold the Playwright scripts and Page Object Models (POM) for you.
- Self-Healing & Debugging: When tests fail, feed error logs or Trace Viewer data to the AI. It can instantly distinguish between a broken selector and a race condition, providing a “self-healing” patch.
- Architectural Alignment: Use AI to enforce boundaries. Instruct it to “Setup test data via
UserServiceAPI rather than direct DB queries,” ensuring tests remain decoupled from the internal schema. - Edge Case Discovery: Ask AI to brainstorm failure points you might miss—like network latency or partial input—to quickly expand coverage beyond the happy path.
Development Workflow
Set up your workflow so that:
- AI generates implementation + tests
- Developers review test code for completeness and correctness
- CI runs full test suite automatically
- No merge without passing tests and required coverage
This shifts review focus to where human judgment adds the most value: understanding requirements and validating behavior through tests, not hunting for syntax errors in generated code.